Я уже писал в 2019 году о том, что компьютерный алгоритм научился определять по активности мозга что человек хочет сказать. Если кто читает мою фантастику, то может вспомнить, что в романе “Ретенция” по сюжету главный герой уже дорабатывает некогда до него созданную технологию декодирования нервно-психических кодов и пытается адаптировать её для управления летательными аппаратами. Когда я начинал обдумывать сюжет романа ещё в 2013 году, то и помыслить не мог, что столь существенные успехи будут достигнуты столь быстро.

Итак, что здесь нового. До этого все попытки разобраться в том, как формируются мысли проводились в основном с помощью электродных методик, в том числе на открытом мозге. В мозг буквально погружали электроды и регистрировали активность, потом сопоставляли с тем, на какие стимулы реагируют нейроны, обучаются ли они включаться/выключаться на что-то ещё, а затем решали обратную задачу – по активности пытались воспроизвести то, что мог “проиграть” нейрон: звук, изображение, слово и т.д. Так делали как с отдельными нейронами, так и с обширными группами клеток. Преимущество электродов в том, что у них огромное временное разрешение, то есть они могут регистрировать процессы, измеряемые в миллисекундах. А вот у сканирующих методов такой способности нет. Условно говоря, фМРТ медленнее скорости мыслей. Поэтому традиционно фМРТ сканер отметался для исследований декодирования сложных мыслей в реальном времени. Кстати, я считаю, что будущее всё-таки за какими-то нанокомпозитными трекерами (наночастицами) по типу напыления на мозг, которые смогут детектировать очень быстрые изменения в активности и с помощью ИИ интерпретировать данные в мыслеобраз. По крайней мере для управления устройствами и аппаратами такая технология выглядит реалистичнее. Но вернёмся к ошеломляющей по своему значению работе.
Команда исследователей их Техасского университета поместила трёх испытуемых в функциональный МРТ сканер, позволяющий следить за активностью мозга в режиме реального времени. В таком случае оценивается количество перераспределённого кровотока, и уже косвенно по этому признаку интерпретируется активность тех или иных структур. Испытуемые прослушивали аудиозаписи подкастов и радиопередач, в общей сложности по 16 часов каждый. Говорят, что слушали в том числе TED (я бы и сам принял участие в таком эксперименте))).
На основе полученных данных компьютерный алгоритм смог научиться прогнозировать рисунок активности мозга, получаемый во время сканирования. Для того, чтобы протестировать алгоритм испытуемые в сканере уже не слушали аудио, а сами мысленно представляли различные истории. После этого они рассказывали истории вне сканера. И результаты сравнений оказались пугающими. Алгоритм с очень высокой точностью из активности обширных областей мозга смог восстановить ход событий рассказанных историй. Да, были некоторые неточности в местоимениях и прочие погрешности, но все последовательности событий/действий были интерпретированы верно. Оказалось, что алгоритм также способен с довольно высокой точностью определять содержание прослушанной истории. Рис. 2 (b) в карусели. Причём, нередко алгоритм мог не просто определить последовательность основных действий, но и дешифровать целые фразы и слова.
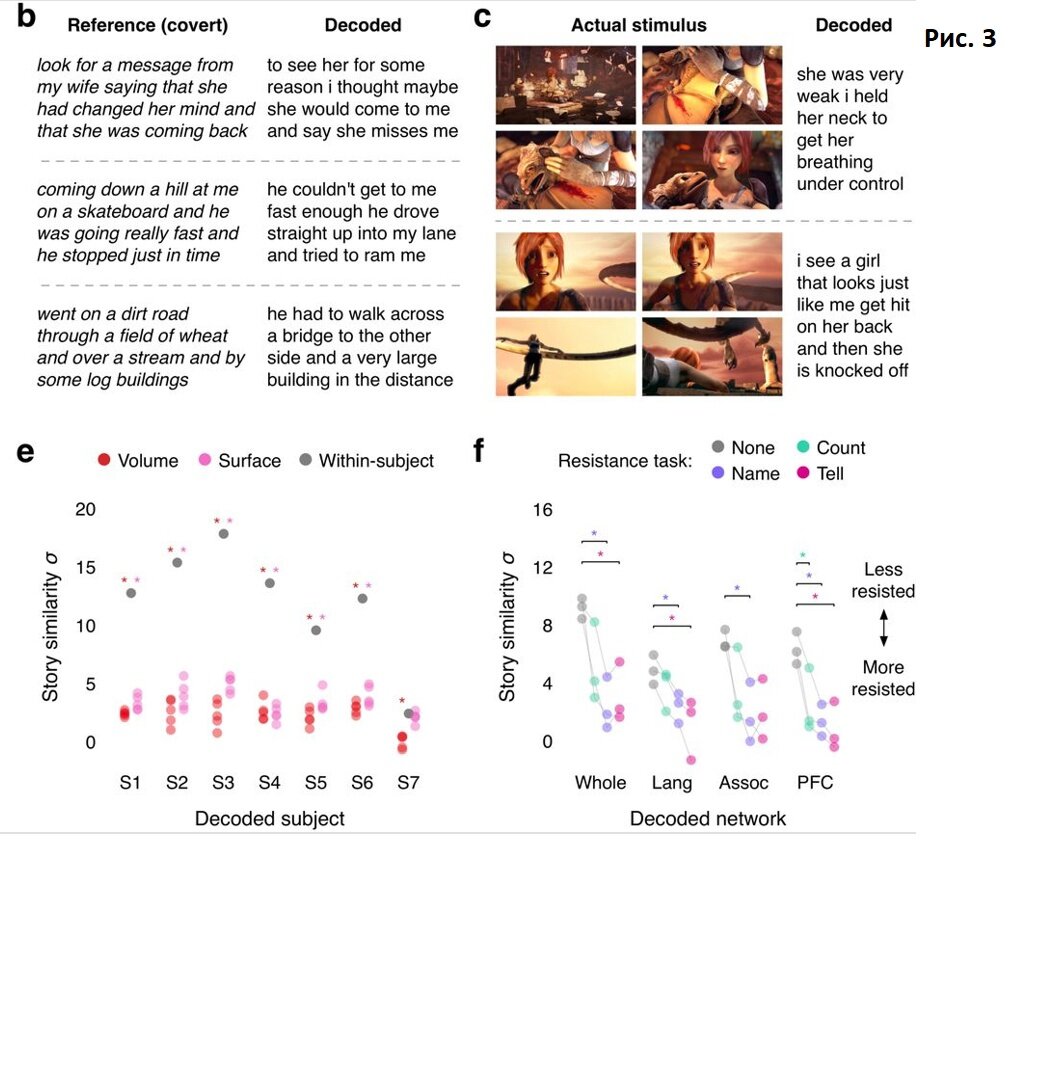
Лично меня больше всего в работе ошеломила часть с кросс-модальным декодированием: возможностью перейти от картинки к речи. Испытуемым предъявили несколько коротких немых анимационных фильмов и алгоритм смог восстановить по активности мозга все события просмотренных историй! Рис. 3 (c). Вы просто оторвитесь от текста и на секунду подумайте об этом. Вот вы сейчас прочли этот текст, а сканер вам его перескажет. Ему даже вас спрашивать ни о чём не надо!
Таким образом, данное исследование подтверждает концепцию потоков информации в мозге (Сверху-вниз (Bottom-up) и Сверху-вниз (Top-down) о том, что процессы представления информации и подготовки к речевому высказыванию имеют схожие рисунки активности мозга. Тогда как восприятие информации идёт иным путём. Поэтому в норме мозг никогда не путает то, что он ВОСПРИНИМАЕТ (видит, слышит, осязает) с тем, что он сейчас ПРЕДСТАВЛЯЕТ. Именно эту особенность мозга и использовали авторы, чтобы создать относительно универсальный алгоритм распознавания представляемых образов. Конечно, говорить о полноценном “чтении мыслей” всё ещё рано, но точность представленного алгоритма лично меня пугает. И заставляет пересмотреть мои планы на исследования и новые проекты на ближайшие десятилетия. Как бы я переиначил известную фразу - это маленький шаг для учёных, но колоссальный для человечества.
Кстати, сами исследователи затронули и этическую сторону вопроса – последствия создания подобной технологии. О чём я также много писал в Ретенции (не думал, что придётся сегодня говорить об этом уже вне поля научной фантастики).
Руководителю группы, Александеру Хасу пришлось даже оправдываться за подобные разработки. В частности, он успокаивает нас тем, что его команда глубоко обдумала последствия и позаботилась о том, чтобы удостовериться, что данный алгоритм не может работать без согласия человека. В частности, если испытуемый отвлекается на посторонние процессы, например, на воображаемых животных, то алгоритм уже не в состоянии правильно интерпретировать ход мыслей во время прослушивания историй. Но у кого есть сомнения, что доработанный алгоритм не сможет обойти эти ограничения? =)
А что вы думаете по поводу такой технологии? Хотели бы чтобы помимо вашей воли читали мысли?
Автор статьи Илья Андреевич Мартынов, нейробиолог, научный руководитель Центра Развития Мозга.