Вот мы и добрались до деревьев – одного из самых важных и сложных типов коллекций.
Готовых классов коллекций-деревьев среди разных языков я не нашел (может, плохо искал), но во-первых, они присутствуют как внутренние реализации других коллекций, а во-вторых, реализацию можно написать самостоятельно.
Итак, дерево – это развитие идеи связного списка. Если в списке каждый элемент имеет только одного "потомка", то в дереве каждый элемент может иметь несколько "потомков", которые существуют параллельно друг другу. Они не связаны друг с другом, но связаны со своим "родителем". Каждый из этих потомков может быть родителем своих потомков, и т.д.
То есть структура данных, начиная с первого элемента, ветвится на несколько элементов, далее каждый из них может опять ветвиться, то есть – получается настоящее дерево, но обычно его рисуют в перевёрнутом виде:
Деревья применяются очень широко: это и представление семейных связей, и классификация животного мира, и файловая система, и даже банальная карта разделов сайта – это дерево. Документ XML или JSON также имеет древовидную структуру.
С точки зрения доступа к данным такой коллекции, у нас есть её корневой элемент. У этого элемента есть потомки, то есть мы можем получить их в виде массива, множества или списка. Далее, каждого потомка мы рассматриваем как отдельное дерево – то есть мы можем получить от него список его потомков, и т.д.
Обход всех элементов дерева это типично рекурсивная задача. Дерево подобно самому себе, то есть содержит поддеревья, которые также содержат поддеревья и т.д. Вопросы рекурсии мы рассмотрим в следующих выпусках.
Нужно отметить, что кроме утилитарного хранения данных в иерархическом виде (карта сайта, документ XML), деревья используются как вспомогательные структуры других коллекций для быстрого поиска.
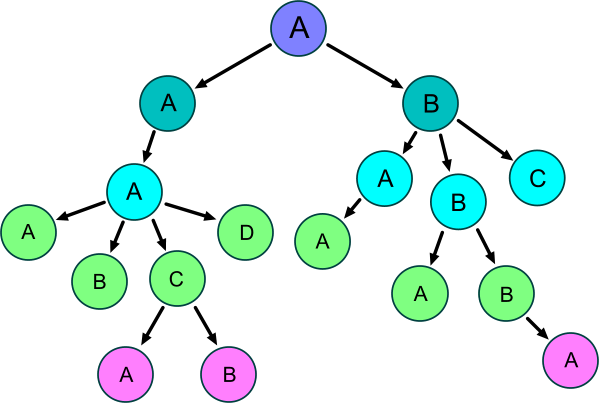
Например, чтобы найти слово 'ABBA' в базе слов, нам пришлось бы сравнить его с каждым словом из базы. Но если заранее построить дерево из сочетаний букв, которые есть в словах в базе, то слово 'ABBA' можно найти за 4 обращения к данным:
Мы берём первую букву "A", затем среди её потомков ищем букву "B", затем среди её потомков опять ищем букву "B" и наконец среди её потомков ищем последнюю букву "A". Если мы нашли все 4 буквы, то мы нашли слово. Если на каком-то из этапов очередная буква не нашлась, то поиск можно не продолжать.
Одним из вариантов поискового дерева является бинарное дерево. Это такое дерево, где у каждого элемента может быть только 2 потомка: левый и правый. Таким образом можно сортировать любые данные, у которых есть признак типа "да-нет".
Например, можно организовать какой-то произвольный набор чисел в такое бинарное дерево:
Корневым элементом может являться любое число из набора. Его потомками – тоже любые числа, но с одним условием: левым потомком становится число, которое меньше, а правым – которое больше. Если такого числа не нашлось, то потомка просто нет.
Поиск элемента в бинарном дереве похож на задание уточняющих вопросов в игре, где отвечающий может говорить только "да" или "нет".
Допустим, нам надо найти ответ на вопрос, если ли в наборе число 7.
Мы начинаем с корневого элемента (8) и задаем вопрос: 7 больше 8? Нет. Значит, мы идем в левую ветку. Там находится число 3. Мы опять задаем вопрос: 7 больше 3? Да. Тогда мы идем в правую ветку. Там находится число 6. Мы снова задаем вопрос: 7 больше 6? Да. Тогда мы идем в правую ветку и находим там искомое число 7. То есть мы нашли элемент за 4 операции. Какая альтернатива? Полный перебор (в данном случае 9 операций).
Но следует помнить, что бинарное дерево – не панацея. Во-первых, если бы число 7 оказалось чисто случайно первым в списке, то с помощью перебора мы нашли бы его всего за одну операцию. Кроме того, если у нас есть какая-то информация о том, как расположены числа в коллекции (например, по возрастанию), тогда и искать их можно более эффективно без помощи дерева.
Также критически важно, чтобы само дерево было сбалансировано. Ведь его можно построить и таким образом:
То есть все его элементы будут только с правой стороны, и таким образом мы получим обычный связный список, хоть и отсортированный по возрастанию.
Короче говоря, эффективность использования деревьев сильно зависит от качества реализации этих деревьев и от природы используемых данных.
Вот, пожалуй, и всё о коллекциях. Предыдущие выпуски:
- Массивы