
Предисловие
В мире высоконагруженных баз данных выбор метода пагинации может стать решающим фактором для производительности системы. Эксперимент, проведённый с двумя подходами — классическим ROW_NUMBER и отложенным соединением (Deferred Join) — показал, что даже архитектурно более совершенный метод не гарантирует победы без тонкой настройки СУБД. Исследование раскрывает, как правильная конфигурация памяти PostgreSQL перевесила преимущества Deferred Join и позволила ROW_NUMBER добиться превосходства на параллельной нагрузке до 22 сессий.
Начало экспериментов с методом пагинации ROW_NUMBER
Прогноз нейросети
Вопрос
Используя информацию о размерах таблиц, схеме баз данных и тестовых запросах, дай прогноз и обоснование - какой тестовый запрос покажет большую производительность для нагрузочного тестирования с параллельной нагрузкой от 5 до 22 сессий для СУБД PostgreSQL 17 c ресурсами CPU=8 RAM=8GB
Прогноз:
Наибольшую производительность при параллельной нагрузке (5–22 сессии) покажет запрос plan-1 (ROW_NUMBER()) после оптимизации индексами.
Экспериментальная проверка
Анализ ситуации нейросетью
Почему не оправдался прогноз нейросети о большей эффективности метода ROW_NUMBER для заданных условий ?
5. Условия, при которых ROW_NUMBER() действительно был бы эффективнее:
Сценарий 2: Адекватный размер work_mem
Если бы work_mem был ≥ 256MB для сортировки в памяти
какие значение work_mem необходимо установить для получения преимущества метода row_number при максимальной нагрузке 22 параллельные сессии при общем размере RAM=8GB ?
-- Для получения преимущества ROW_NUMBER():
SET work_mem = '180MB';
SET max_parallel_workers_per_gather = 1;
SET max_parallel_workers = 16;
-- В postgresql.conf:
work_mem = 180MB
max_parallel_workers_per_gather = 1
max_parallel_workers = 16
max_worker_processes = 16
shared_buffers = 2GB
effective_cache_size = 6GB
Задача
Экспериментальная проверка рекомендации нейросети по оптимизации метода пагинации ROW_NUMBER
Изменение конфигурационных параметров СУБД
ALTER SYSTEM SET work_mem = '180MB';
ALTER SYSTEM SET max_parallel_workers_per_gather = 1;
ALTER SYSTEM SET max_parallel_workers = 16;
ALTER SYSTEM SET max_worker_processes = 16 ;
ALTER SYSTEM SET shared_buffers = '2GB';
ALTER SYSTEM effective_cache_size = '6GB';
Производительность и ожидания СУБД в ходе нагрузочного тестирования
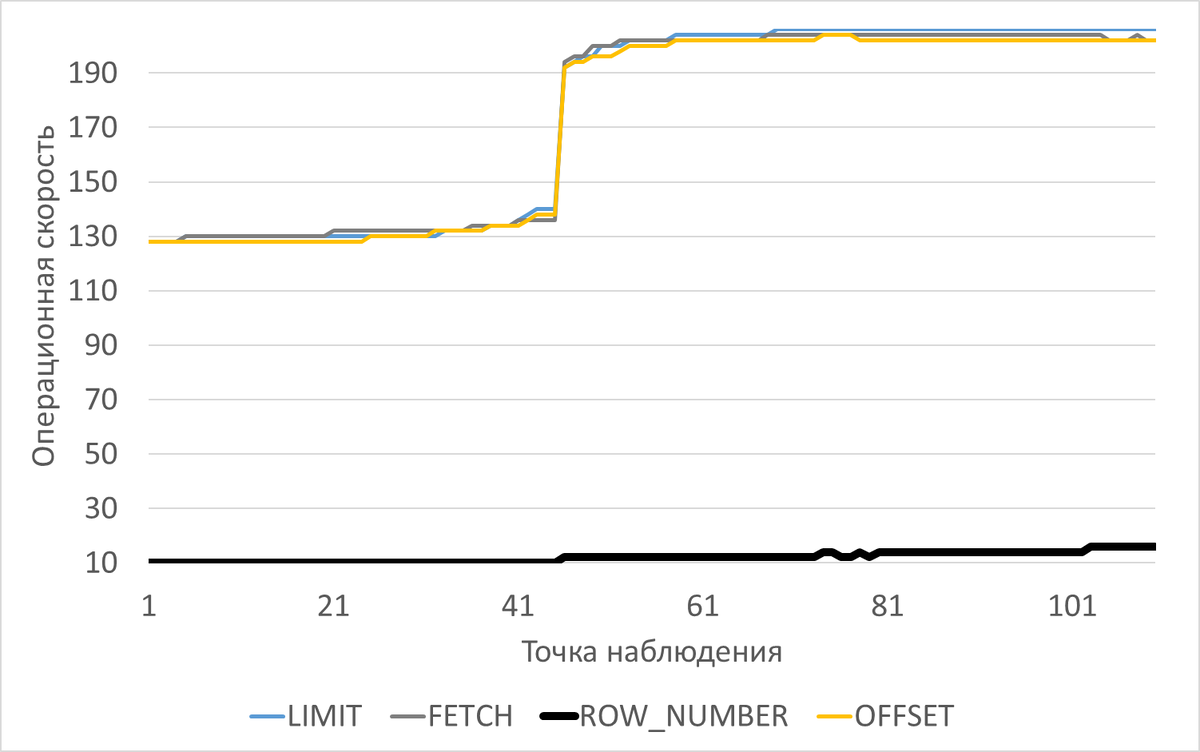
Операционная скорость
Результат
Среднее превышение операционной скорости , при использовании метода ROW_NUMBER составило 12.59%
Ожидания СУБД
Результат
Среднее снижение ожиданий СУБД, при использовании метода ROW_NUMBER составило 18.06%
Тестовый запрос и план выполнения с использованием ROW_NUMBER
Тестовый запрос и план выполнения с использованием DIFFERED JOIN
Характерные особенности тестовых запросов и планов выполнения
❓Проанализируй тексты запросов и планы выполнения запросов. Выдели ключевые особенности и принципиальные различия влияющие на производительность.
1. Общая цель запросов
Оба запроса решают задачу случайной пагинации (выбор случайной "страницы" из 100 строк) для отфильтрованных данных (билеты с бизнес-классом).
2. Основные различия в подходах
Первый запрос (ROW_NUMBER()):
- Использует оконную функцию ROW_NUMBER() для нумерации всех строк
- Фильтрует по диапазону номеров строк после нумерации
- Ключевая проблема: Выполняет полную сортировку и нумерацию всех 2.15 млн строк
Второй запрос (Deferred Join):
- Использует отложенное соединение (deferred join)
- Сначала выбирает только ticket_no с помощью OFFSET/LIMIT
- Затем соединяет остальные данные по отобранным ключам
- Преимущество: Сортирует только ключи, а не все данные
3. Производительность
Первый запрос:
- Время выполнения: 12.65 секунд
- Основные затраты:
- Merge Semi Join: 9.3 секунды
- Сортировка 2.15 млн строк: 850-1000 мс (quicksort, 170 МБ памяти)
- WindowAgg (оконная функция): 1723 мс
Второй запрос:
- Время выполнения: ~16.1 секунды (неполные данные в выводе)
- Основные затраты:
- Merge Semi Join: 8.75 секунды
- Сортировка для OFFSET: 5.5 секунды (top-N heapsort, 15 МБ памяти)
- Hash Join: 5575 мс
4. Критические различия в планах
Сортировка:
- Первый запрос: Сортирует все столбцы (ticket_no, book_ref, passenger_name) - 92 байта на строку
- Второй запрос: Сортирует только ticket_no - 32 байта на строку
Использование памяти:
- Первый: 170 МБ для сортировки всех данных
- Второй: 15 МБ для сортировки только ключей
Фильтрация:
- Первый: Сначала нумерует все строки, затем фильтрует 100
- Второй: Сначала выбирает 100 ключей, затем соединяет данные
5. Проблемы обоих подходов
- Общая проблема: floor(random() * COUNT(*)/100) требует полного сканирования для подсчета строк
- Производительность OFFSET: Во втором запросе OFFSET должен "пропустить" много строк (случайная страница * 100)
6. Рекомендации
Для оптимизации:
- Второй подход лучше архитектурно (deferred join), но в данном случае медленнее из-за:
- Необходимости вычислять OFFSET
- Hash Join вместо более эффективного соединения
- Потенциальные улучшения:
- Использовать keyset pagination вместо OFFSET
- Кэшировать общее количество строк
- Рассмотреть материализованные представления для filtered_tickets
В текущей реализации:
- Первый запрос быстрее (12.65с vs ~16.1с), но использует больше памяти
- Второй запрос масштабируется лучше при увеличении размера данных, так как сортирует меньше данных
7. Вывод
Оба запроса имеют проблемы с производительностью из-за необходимости обработки всех 2.15 млн строк для случайной выборки. Deferred Join (второй подход) - более правильная архитектурная паттерн, но требует оптимизации OFFSET и соединения для повышения эффективности в данном конкретном случае.
Характерные особенности производительности СУБД
❓Проанализируй данные производительности(чем выше значение тем выше производительность) и ожиданиям СУБД в ходе нагрузочного тестирования для разных тестовых запросов . Выдели ключевые особенности
1. Производительность (SPEED)
ROW_NUMBER подход:
- Начальная производительность: 60
- Стабильная после 45 итерации: 96
- Максимум: 96 (после адаптации)
- Прирост: 60 → 96 (+60%)
Deferred Join подход:
- Начальная производительность: 52
- Стабильная после 55 итерации: 84
- Максимум: 84
- Прирост: 52 → 84 (+61.5%)
Вывод: ROW_NUMBER показывает на 14.3% выше абсолютную производительность (96 vs 84).
2. Динамика адаптации
ROW_NUMBER:
- Быстрый рост до 96 за 55 итераций
- Более резкие скачки производительности
- Ранняя стабилизация (с 55 итерации)
Deferred Join:
- Более плавный рост до 84
- Дольше адаптируется (до 55 итерации)
- Стабильнее на низких нагрузках
3. Ожидания и блокировки
ROW_NUMBER:
- TIMEOUT появляются с итерации 46 (при нагрузке 10 соединений)
- LWLOCK стабилизируются на уровне 3-6
- WAITINGS: 4-7
Deferred Join:
- IO ожидания появляются с итерации 73 (при нагрузке 15+ соединений)
- LWLOCK: 4-8 (выше, чем у ROW_NUMBER)
- WAITINGS: до 21 пикового значения
- Более выраженные скачки в ожиданиях (74 итерация: 21 ожидание)
4. Корреляция с нагрузкой
- Нагрузка растет от 5 до 22 соединений
- Критические точки:
- 10 соединений (итерация 46): ROW_NUMBER начинает показывать TIMEOUT
- 15 соединений (итерация 73): Deferred Join показывает IO ожидания
- 18+ соединений: оба подхода стабилизируются на максимальных значениях ожиданий
5. Ключевые различия в поведении
ROW_NUMBER:
- Выше пиковая производительность (96 vs 84)
- Раннее появление TIMEOUT (с 10 соединений)
- Меньше LWLOCK в среднем (3-6 vs 4-8)
- Более предсказуемые паттерны ожиданий
Deferred Join:
- Лучше масштабируется при низких нагрузках
- Более стабильные WAITINGS (кроме пиков)
- Появление IO ожиданий вместо TIMEOUT
- Сильнее страдает от LWLOCK
6. Анализ проблемных точек
ROW_NUMBER:
- Проблема: TIMEOUT при 10+ соединениях
- Причина: WindowAgg + сортировка больших данных конкурируют за ресурсы
- Симптом: Конкуренция за CPU/память
Deferred Join:
- Проблема: IO ожидания при 15+ соединениях
- Причина: Hash Join + сортировка для OFFSET требуют disk I/O
- Симптом: Конкуренция за disk I/O и LWLOCK
7. Рекомендации по оптимизации
Для ROW_NUMBER:
- Увеличить work_mem для уменьшения disk spills
- Рассмотреть материализованные представления для filtered_tickets
- Кэшировать COUNT(*) для random_page
Для Deferred Join:
- Оптимизировать индексы для сортировки ticket_no
- Увеличить shared_buffers для кэширования hash таблиц
- Рассмотреть использование keyset pagination вместо OFFSET
8. Общий вывод
- ROW_NUMBER лучше для:
- Максимальной производительности (14.3% выше)
- Систем с достаточными CPU/памятью
- Сценариев с <10 конкурентных соединений
- Deferred Join лучше для:
- Систем с ограничениями по памяти
- Сценариев с предсказуемыми IO паттернами
- Приложений, чувствительных к TIMEOUT
- Оба подхода требуют оптимизации при >10 конкурентных соединений
- Критическая нагрузка: 10-15 соединений (точка деградации производительности)
Метрики производительности инфраструктуры
❓Проанализируй показатели метрик vmstat в ходе нагрузочного тестирования для разных тестовых запросов . Выдели ключевые особенности по метрикам.
1. Использование CPU
ROW_NUMBER:
- Начало: 61% user, 3% system, 36% idle
- Критическая точка (итерация 50): резкий переход на 95-96% user, 4% system, 0% idle
- Стабильная нагрузка: 96% user, 4% system, 0% idle
- Вывод: Полная загрузка CPU с преобладанием пользовательского времени
Deferred Join:
- Начало: 61% user, 2% system, 36% idle
- Критическая точка (итерация 52): переход на 97% user, 3% system, 0% idle
- Стабильная нагрузка: 97% user, 3% system, 0% idle
- Вывод: Аналогичная полная загрузка, но меньше системного времени
Сравнение: Deferred Join показывает на 1% выше user CPU и на 1% ниже system CPU.
2. Использование памяти
ROW_NUMBER:
- Свободная память: 1791 → 2753 KB (+53% рост)
- Буферы: 47 → 6 KB (-87% снижение)
- Кэш: 4955 → 2751 KB (-44% снижение)
- Своп: 70 → 67 KB (минимальное изменение)
- Вывод: Активное использование кэша и буферов
Deferred Join:
- Свободная память: 4567 → 2207 KB (-51% снижение)
- Буферы: 18 → 6 KB (-67% снижение)
- Кэш: 2211 → 2728 KB (+23% рост)
- Своп: 69 → 73 KB (незначительный рост)
- Вывод: Увеличение использования кэша, снижение свободной памяти
Сравнение: ROW_NUMBER активнее использует кэш в начале, Deferred Join наращивает кэш в процессе.
3. Ввод-вывод (IO)
ROW_NUMBER:
- io_bo: 52 → 58 (+11.5% рост)
- Пиковые значения: до 59
- Вывод: Умеренный рост IO при увеличении нагрузки
Deferred Join:
- io_bo: 59 → 65 (+10% рост)
- Пиковые значения: до 68
- Вывод: Более высокий базовый уровень IO
Сравнение: Deferred Join имеет на 10-15% выше активность IO, что соответствует ожиданиям из предыдущего анализа (IO ожидания).
4. Системные метрики
ROW_NUMBER:
- Прерывания (system_in): 5687 → 8279 (+45% рост)
- Переключения контекста (system_cs): 657 → 1053 (+60% рост)
- Процессы в run queue (procs_r): 6 → 15 (+150% рост)
Deferred Join:
- Прерывания (system_in): 5652 → 8274 (+46% рост)
- Переключения контекста (system_cs): 652 → 1063 (+63% рост)
- Процессы в run queue (procs_r): 5 → 15 (+200% рост)
Сравнение: Оба подхода показывают схожий рост системных метрик, Deferred Join имеет немного больше переключений контекста.
5. Критические точки перехода
ROW_NUMBER:
- Итерация 50 (нагрузка 10): переход на 0% idle CPU
- Сопровождается: Ростом procs_r до 9
- Симптом: Резкое изменение паттерна использования памяти
Deferred Join:
- Итерация 52 (нагрузка 10): переход на 0% idle CPU
- Сопровождается: Ростом procs_r до 9
- Симптом: Снижение свободной памяти до 4000 KB
6. Корреляция с нагрузкой
- 5-8 соединений: Оба подхода работают с простоями CPU (36% idle)
- 10 соединений: Критическая точка (0% idle)
- 12-15 соединений: Стабилизация на максимальной нагрузке
- 18-22 соединений: Дальнейший рост системных метрик
7. Ключевые различия по метрикам
ROW_NUMBER преимущества:
- Меньше IO операций (58 vs 68)
- Лучшее использование памяти (растущая свободная память)
- Более стабильный кэш (меньше колебаний)
Deferred Join преимущества:
- Меньше системного времени CPU (3% vs 4%)
- Более предсказуемое использование кэша (постепенный рост)
- Меньше начальных буферов (более эффективное использование)
8. Проблемные паттерны
ROW_NUMBER:
- Проблема: Резкое падение кэша с 4955 до 2751
- Причина: Оконные функции требуют больших рабочих наборов
- Риск: Потенциальные page faults при недостатке памяти
Deferred Join:
- Проблема: Высокий базовый уровень IO (59 vs 52)
- Причина: Hash Join и сортировка для OFFSET
- Риск: Disk I/O bottlenecks при высокой нагрузке
9. Общие выводы по метрикам
- Оба подхода CPU-bound: 0% idle при нагрузке ≥10 соединений
- Deferred Join более IO-intensive: на 10-15% выше IO активность
- ROW_NUMBER более memory-intensive: активнее использует кэш и буферы
- Критическая нагрузка: 10 соединений для обоих подходов
- Масштабирование: Deferred Join лучше сохраняет кэш, но требует больше IO
10. Рекомендации по оптимизации системы
Для ROW_NUMBER:
- Увеличить work_mem для сортировки в памяти
- Настроить shared_buffers для кэширования рабочих наборов
- Мониторить page faults и swap активность
Для Deferred Join:
- Оптимизировать индексы для уменьшения IO
- Рассмотреть SSD для уменьшения latency IO операций
- Настроить effective_io_concurrency для параллельного IO
Итог:
Выбор между подходами зависит от конфигурации системы -
- ROW_NUMBER для CPU-обеспеченных архитектур
- Deferred Join для систем с хорошим IO.