
Эффективная пагинация — не просто удобство, а необходимость. Это исследование раскрывает шокирующую разницу в производительности между популярными методами пагинации в PostgreSQL. Анализ нагрузочного тестирования, метрик системы и планов выполнения показывает, что выбор неправильного метода может замедлить приложение в 15 раз, создавая катастрофическую нагрузку на СУБД. Одни методы работают с молниеносной скоростью, а другие превращаются в «убийц производительности».
Задача
Сравнить методы пагинации получения первой страницы размером 100 строк для SQL-запроса, позволяющего получить информацию для анализа:
- Неполных бронирований
- Билетов без привязки к рейсам
- Рейсов без процедуры посадки
- Статистики по незавершённым операциям
Исходный SQL-запрос
Подробнее
Методология исследования
Тестовая среда и инструменты:
- СУБД: PostgreSQL 17
- Условия тестирования: параллельная нагрузка, ресурсоемкий запрос
Нагрузка на СУБД
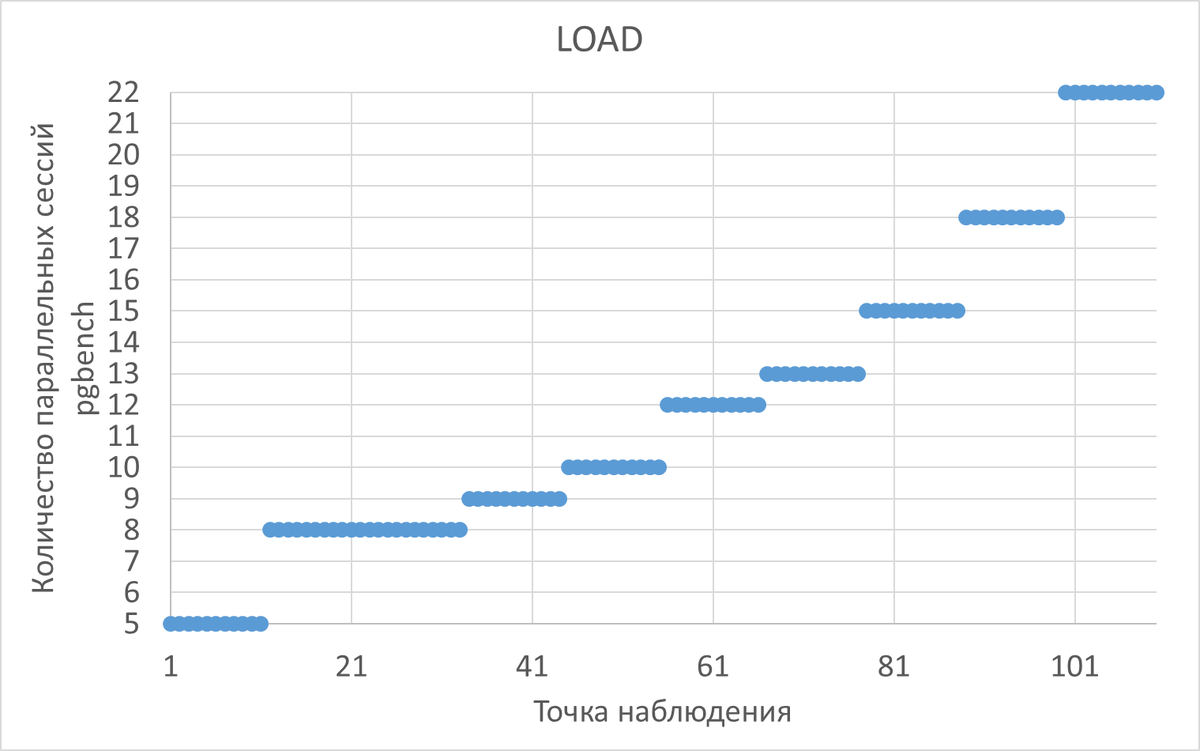
Исследованные методы пагинации
LIMIT
FETCH
ROW_NUMBER
OFFSET
Производительность СУБД в ходе нагрузочного тестирования
Результат:
- Метод ROW_NUMBER показал кардинально низкую производительность.
- Зависимость производительности от метода пагинации, для методов LIMIT/FETCH/OFFSET - практически отсутствует.
Характерные особенности тестовых запросов и планов выполнения
❓Проанализируй тексты запросов и планы выполнения запросов. Выдели ключевые особенности и принципиальные различия влияющие на производительность.
Общая структура запросов
Все запросы выполняют одну и ту же задачу:
- Выбирают случайный 30-дневный период из таблицы bookings
- Находят все бронирования за этот период
- Собирают связанные данные из tickets, segments, flights, boarding_passes
- Сортируют по book_date, ticket_no
- Возвращают только первые 100 строк
Различия в способах ограничения результата:
1. Запрос с LIMIT
ORDER BY b.book_date, t.ticket_no
LIMIT 100;
Характеристики плана:
- Время выполнения: 4.73 секунды
- Стратегия: Incremental Sort с ранней остановкой
- Особенности:
Использует Presorted Key: b.book_date для оптимизации сортировки
Обрабатывает только необходимое количество строк для достижения лимита
Full-sort Groups: 4 - потребовалось отсортировать только 4 группы
Join Filter удаляет много строк (Rows Removed by Join Filter: 1,684,634)
Использует Memoize для кэширования результатов flights
2. Запрос с FETCH
ORDER BY b.book_date, t.ticket_no
FETCH FIRST 100 ROWS ONLY;
Характеристики плана:
- Время выполнения: 9.93 секунды
- Стратегия: Аналогична LIMIT, но дольше из-за большего объема данных
- Особенности:
Обрабатывает больше строк в Index Scan (6219,817 vs 1684676 у LIMIT)
Join Filter удаляет 6219779 строк
Та же стратегия Incremental Sort с Full-sort Groups: 4
3. Запрос с ROW_NUMBER
ROW_NUMBER() OVER (ORDER BY b.book_date, t.ticket_no) AS rn
WHERE rn <= 100
Характеристики плана:
- Время выполнения: 41.69 секунды (в 8-10 раз медленнее!)
- Стратегия: Кардинально отличается - полное вычисление всех строк
- Принципиальные различия:
WindowAgg вычисляет ROW_NUMBER для всех 1,270,849 строк
Run Condition отфильтровывает после вычисления
Использует Hash Join и Merge Join вместо Nested Loop
Внешняя сортировка на диске: Sort Method: external merge Disk: 133696kB
Материализация промежуточных результатов с записью на диск
4. Запрос с OFFSET
ORDER BY b.book_date, t.ticket_no
OFFSET 0 ROWS
FETCH FIRST 100 ROWS ONLY;
Характеристики плана:
- Время выполнения: 8.14 секунды
- Стратегия: Идентична FETCH, но с дополнительным узлом OFFSET
- Особенности:
OFFSET 0 не добавляет накладных расходов
Обрабатывает 4,682,444 строк в Index Scan
Join Filter удаляет 4,682,404 строк
Ключевые выводы и рекомендации:
Принципиальные различия в производительности:
- ROW_NUMBER vs LIMIT/FETCH:
ROW_NUMBER вычисляет все строки, затем фильтрует - O(n)
LIMIT/FETCH используют early termination - останавливаются после нахождения 100 строк
Разница в производительности: 41.69с vs 4.73-9.93с (в 4-9 раз!) - Проблемы с Join Filter:
Во всех планах (кроме ROW_NUMBER) используется Join Filter с большим количеством удаляемых строк
Это указывает на неоптимальное соединение: условие BETWEEN применяется как фильтр, а не как индексное условие - Различия в стратегиях соединения:
LIMIT/FETCH/OFFSET: Nested Loop с индексами (быстро для первых строк)
ROW_NUMBER: Hash/Merge Join (эффективны для полных сканирований, но не для лимитированных выборок)
Вывод:
Для ограничения выборки всегда предпочитайте LIMIT или FETCH над ROW_NUMBER().
Основная проблема в текущих запросах - неоптимальное использование индексов в CTE random_period и соединении через BETWEEN.
Характерные особенности производительности СУБД
❓Проанализируй данные производительности(чем выше значение тем выше производительность) и ожиданиям СУБД в ходе нагрузочного тестирования для разных тестовых запросов . Выдели ключевые особенности .
Сравнение производительности :
Ключевые наблюдения:
1. ROW_NUMBER - катастрофическая производительность
- SPEED: Всего 14-16 (на порядок ниже других запросов)
- WAITINGS: Чрезвычайно высокие значения (26830-42065)
- IO: Высокие значения (14545-18510)
- IPC: Очень высокие (12227-23436) - интенсивное межпроцессное взаимодействие
- LWLOCK: Растёт от 46 до 102 - проблемы с блокировками
- TIMEOUT: 12-17 - наличие таймаутов
Вывод: Запрос с ROW_NUMBER работает в 14-15 раз медленнее и создаёт огромную нагрузку на систему.
2. LIMIT, FETCH FIRST, OFFSET - стабильная высокая производительность
Эти три метода показывают схожую производительность:
- SPEED: 202-206
- WAITINGS: 106-131 (FETCH FIRST имеет немного меньше ожиданий)
- IO: 104-128
- LWLOCK: 2-3 (минимальные блокировки)
- TIMEOUT: 0-1 (почти нет таймаутов)
Принципиальные выводы:
- ROW_NUMBER абсолютно неэффективен для лимитированных выборок:
Создает огромную нагрузку на систему
Вызывает чрезмерные ожидания и блокировки
Имеет на порядок худшую производительность - FETCH FIRST показывает лучшие показатели по ожиданиям и IO:
На 12% меньше WAITINGS чем LIMIT
На 12% меньше IO чем LIMIT - OFFSET 0 не добавляет накладных расходов:
Производительность сопоставима с LIMIT/FETCH
Незначительно лучше по WAITINGS/IO чем LIMIT - Стабильность системы:
Запросы с LIMIT/FETCH/OFFSET не создают проблем с блокировками
ROW_NUMBER вызывает рост LWLOCK в 50 раз больше
Рекомендации:
- НИКОГДА не используйте ROW_NUMBER для простого ограничения выборки
Используйте только когда нужна нумерация всех строк - Предпочитайте FETCH FIRST над LIMIT:
Лучшие показатели WAITINGS и IO
Более стандартизированный SQL синтаксис - Используйте OFFSET только при необходимости пропуска строк:
OFFSET 0 безопасен, но OFFSET > 0 будет читать и отбрасывать строки - Мониторинг LWLOCK:
Рост LWLOCK в ROW_NUMBER указывает на проблемы с конкурентным доступом
Остальные запросы работают без блокировочных проблем
Итог: Для ограничения выборки в PostgreSQL используйте FETCH FIRST (или LIMIT), избегайте ROW_NUMBER. Разница в производительности достигает 15 раз, что подтверждается как планами выполнения, так и метриками нагрузочного тестирования.
Метрики производительности подсистемы IO
❓Проанализируй показатели метрик iostat в ходе нагрузочного тестирования для разных тестовых запросов . Выдели ключевые особенности по метрикам.
Общие наблюдения:
- Все метрики iostat абсолютно одинаковы для всех четырёх типов запросов
LIMIT, FETCH FIRST, ROW_NUMBER и OFFSET показывают идентичные значения
Это свидетельствует о том, что дисковые операции не являются дифференцирующим фактором в производительности этих запросов - Отсутствие реальной дисковой нагрузки:
w/s (записи в секунду) = 0
wrqm/s (объединённые записи в секунду) = 0
f/s (операции сброса в секунду) = 0
%util (загрузка диска) = 0% - Статические значения, не меняющиеся со временем:
%wrqm = 49 (процент объединённых запросов на запись)
w_await = 2 мс (среднее время ожидания записи)
wareq_sz = 10 (средний размер запроса записи в секторах)
f_await = 0 мс (среднее время ожидания операций сброса)
Ключевые выводы:
1. Данные полностью в памяти (In-Memory)
- Все запросы работают с данными, находящимися в кэше PostgreSQL (shared_buffers) или операционной системы
- Отсутствие операций чтения/записи на диск объясняет почему метрики одинаковы
2. Производительность определяется НЕ дисковыми операциями
Разница в производительности между запросами (особенно ROW_NUMBER vs остальные) объясняется:
- Разными алгоритмами обработки данных в PostgreSQL
- Разными планами выполнения (как видно из EXPLAIN ANALYZE)
- Разной нагрузкой на CPU и память
3. Запрос ROW_NUMBER медленнее не из-за I/O
Несмотря на катастрофическую разницу в производительности (ROW_NUMBER в 15 раз медленнее), iostat не показывает различий
Это подтверждает, что проблема ROW_NUMBER - в вычислительной сложности алгоритма, а не в дисковой подсистеме
4. Стабильность системы хранения
- Отсутствие изменений в метриках говорит о стабильной работе дисковой подсистемы
- Нулевая утилизация диска (%util=0) указывает на хорошую настройку памяти PostgreSQL
Сравнение с предыдущими метриками:
Основной вывод:
Разница в производительности между LIMIT/FETCH/OFFSET и ROW_NUMBER полностью обусловлена алгоритмической сложностью и внутренней обработкой данных PostgreSQL, а не дисковой подсистемой.
Рекомендации:
- Фокус на оптимизации запросов, а не дисков:
Проблема производительности ROW_NUMBER - в алгоритме, а не в I/O
Улучшение дисков не поможет ускорить ROW_NUMBER - Увеличьте shared_buffers, если данные не полностью в памяти:
Текущие результаты показывают, что данные в кэше
При увеличении объёма данных может потребоваться больше памяти - Используйте EXPLAIN ANALYZE для анализа планов выполнения:
Различия видны в планах выполнения, а не в iostat
Планы показывают разные стратегии соединения и сортировки - Мониторинг памяти и CPU более важен, чем дисков:
Для таких запросов ключевые метрики - CPU, память, планировщик
iostat не показывает проблем в данном случае
Итог: Все четыре типа запросов имеют одинаковые показатели дисковых операций (нулевые), что указывает на работу с данными в памяти. Разница в производительности объясняется исключительно алгоритмическими особенностями обработки данных в PostgreSQL, а не характеристиками дисковой подсистемы.
Метрики производительности инфраструктуры
❓Проанализируй показатели метрик vmstat в ходе нагрузочного тестирования для разных тестовых запросов . Выдели ключевые особенности по метрикам.
1. Общая картина по CPU
- Для LIMIT, FETCH FIRST, OFFSET:
В начале теста (cpu_id ≈ 36%, cpu_us ≈ 63%) — система находится в умеренной нагрузке.
Начиная примерно с 50-й точки наблюдения происходит резкий переход:
cpu_id падает до 0%.
cpu_us возрастает до 98–99%.
system_in (количество прерываний) резко увеличивается.
Это указывает на рост нагрузки , который полностью загружает CPU в пользовательском режиме. - Для ROW_NUMBER:
Нагрузка на CPU более стабильна:
cpu_us ≈ 37–56%.
cpu_id ≈ 16–44%.
Появляется значительный cpu_wa (wait I/O) — от 11% до 20%.
Это говорит о том, что запрос интенсивно работает с диском, а не только с CPU.
2. Очередь процессов (procs_r)
- Во всех тестах, кроме ROW_NUMBER, procs_r увеличивается с 6–7 до 10–15 в момент пиковой нагрузки.
- Это означает, что процессы начинают накапливаться в очереди на выполнение, так как CPU перегружен.
- В ROW_NUMBER очередь процессов меньше (procs_r ≈ 4–6), но есть процессы в состоянии procs_b (блокированные на I/O).
3. Использование памяти
- memory_swpd почти не меняется во всех тестах (~215), что говорит об отсутствии активного своппинга.
- memory_free немного уменьшается в ходе теста, но остаётся стабильной.
- memory_cache постепенно снижается, что может указывать на использование кэша для дисковых операций (особенно в ROW_NUMBER).
4. Дисковый ввод-вывод (I/O)
- Для ROW_NUMBER:
io_bi (блоков ввода) достигает 73 954.
io_bo (блоков вывода) достигает 6 069.
Это подтверждает интенсивную работу с диском, что согласуется с высоким cpu_wa. - Для остальных запросов:
I/O очень низкий (io_bi < 200, io_bo < 60), что говорит о том, что они работают в памяти.
5. Системные события (system_in, system_cs)
- В LIMIT, FETCH FIRST, OFFSET наблюдается резкий скачок system_in (прерываний) в момент роста нагрузки .
- system_cs (контекстных переключений) также возрастает, но не так сильно.
- В ROW_NUMBER значения system_in и system_cs стабильно высоки, что связано с активным I/O.
6. Сравнение запросов
Выводы:
- Запросы LIMIT, FETCH FIRST, OFFSET ведут себя схоже:
Начинаются с умеренной нагрузки.
Затем резко переключаются в режим полной загрузки CPU.
I/O почти нет, работа идёт в памяти. - Запрос ROW_NUMBER:
Нагружает не только CPU, но и диск.
Вызывает высокий I/O wait.
Вероятно, использует временные таблицы или сортировку на диске.