Предисловие
Исследование сравнило два метода пагинации — ROW_NUMBER() и Deferred Join — под нагрузкой до 22 параллельных сессий. Прогноз нейросети предсказывал преимущество ROW_NUMBER(), но реальные тесты показали обратное: Deferred Join оказался на 29,3% быстрее, создавал на 70% меньше ожиданий и лучше масштабировался. Этот кейс демонстрирует, как теоретические оптимизации могут не учитывать реальные ограничения СУБД: работу с памятью, параллелизм и стоимость операций ввода-вывода.
Тестовые таблицы
Прогноз нейросети
Наибольшую производительность при параллельной нагрузке (5–22 сессии) покажет запрос plan-1 (ROW_NUMBER()) после оптимизации индексами.
Задача
Экспериментально проверить прогноз нейросети об эффективности метода пагинации с использованием ROW_NUMBER для заданного сценария.
Методология исследования
Тестовая среда и инструменты:
- СУБД: PostgreSQL 17
- Условия тестирования: параллельная нагрузка, запрос к большой таблице.
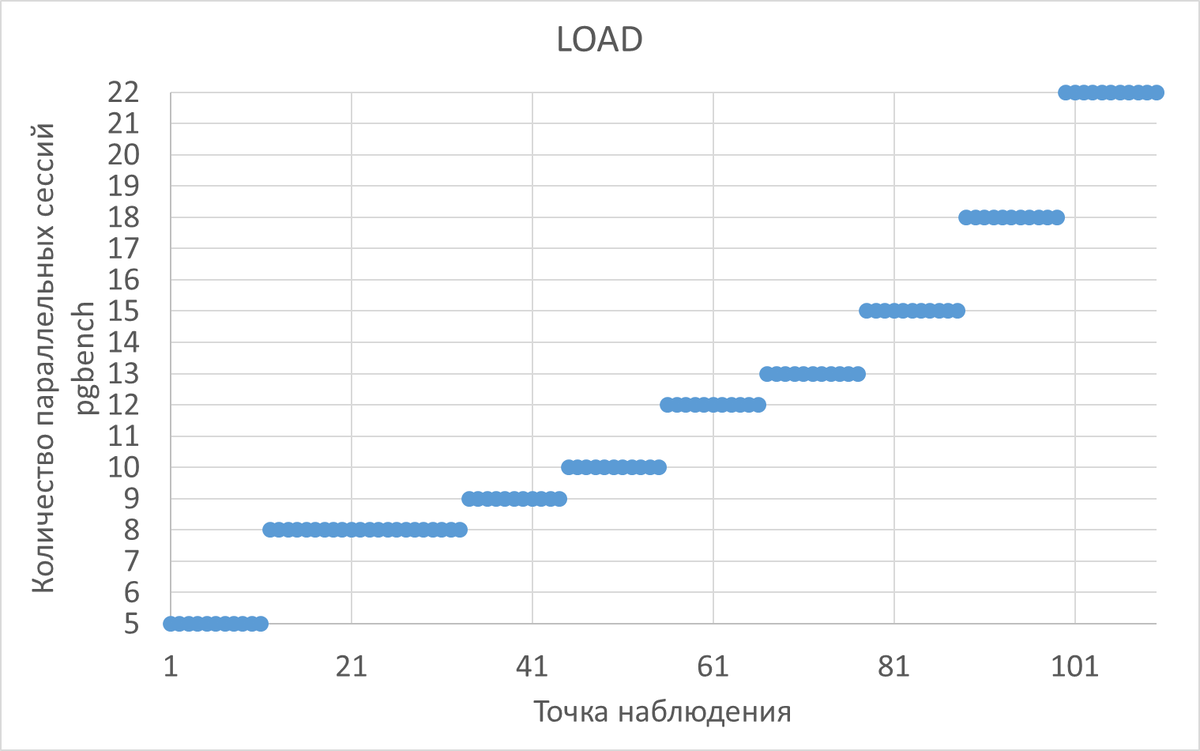
Нагрузка на СУБД
Производительность и ожидания СУБД в ходе нагрузочного тестирования
Операционная скорость
Результат
Среднее превышение операционной скорости , при использовании метода DIFFERED JOIN составило 29.3%
Ожидания СУБД
Результат
Среднее снижение ожиданий СУБД, при использовании метода DIFFERED JOIN составило 70.12%
Тестовый запрос и план выполнения с использованием ROW_NUMBER
Тестовый запрос и план выполнения с использованием DIFFERED JOIN
Характерные особенности тестовых запросов и планов выполнения
❓Проанализируй тексты запросов и планы выполнения запросов. Выдели ключевые особенности и принципиальные различия влияющие на производительность.
1. Обработка данных (основная разница)
Запрос с ROW_NUMBER():
- Полная сортировка всех 2.1M строк (2274755 строк) на диске (Sort Method: external sort Disk: 102104kB)
- Применяет ROW_NUMBER() ко всем строкам (2.1M), затем фильтрует до 100
- Время сортировки: 7640ms - 7953ms для полной сортировки
Запрос с Deferred Join:
- Top-N сортировка с heap sort в памяти (Sort Method: top-N heapsort Memory: 16673kB)
- Сначала находит 100 нужных ticket_no, затем джойнит
- Сортирует 2.1M строк, но использует эффективный алгоритм для OFFSET/LIMIT
2. Использование памяти
ROW_NUMBER():
- Sort Method: external sort Disk: 102104kB - сортировка на диске
- Причина: work_mem=128MB недостаточно для полной сортировки 2.1M строк
- Параллельный hash join использует Memory Usage: 138464kB
Deferred Join:
- Sort Method: top-N heapsort Memory: 16673kB - в памяти
- Более эффективное использование work_mem благодаря top-N алгоритму
3. Производительность
Время выполнения:
- ROW_NUMBER(): 15718.659 ms (15.7 секунд)
- Deferred Join: 11802.626 ms (11.8 секунд)
- Разница: Deferred Join на 25% быстрее
Ключевые точки замедления для ROW_NUMBER():
- Полная сортировка на диске (7.6-8.0 секунд)
- Применение оконной функции ко всем строкам (8.7 секунд)
- Фильтрация после нумерации (удаление 2,158,485 строк)
4. Эффективность алгоритмов
ROW_NUMBER() паттерн:
- Сложность: O(n log n) для полной сортировки + O(n) для оконной функции
- Проблема: Выполняет всю работу, даже для получения 100 строк
Deferred Join паттерн:
- Сложность: O(n log k) для top-N сортировки (k = OFFSET + LIMIT)
- Преимущество: Сортирует только для определения нужных строк
5. Индексы и доступ к данным
Оба запроса НЕ используют существующие индексы оптимально:
- Нет использования индекса idx_segments_flight_id_fare_conditions
- Нет использования покрывающего индекса idx_tickets_covering
- Оба используют Parallel Seq Scan на таблицах
6. CTE и оптимизация
Общие проблемы обоих запросов:
- CTE материализуется (выполняется один раз, сохраняется в память/диск)
- Двойной подсчет строк: Сначала считает общее количество для random_page, затем снова сортирует
- Неоптимальное соединение: Hash Semi Join вместо использования индексов
Принципиальные выводы:
- Deferred Join эффективнее ROW_NUMBER() в этом случае, потому что:
Избегает полной сортировки всех данных
Использует top-N алгоритм вместо полной сортировки
Меньше использует дисковые операции - Оба запроса имеют проблемы с производительностью из-за:
Отсутствия использования индексов
Полного сканирования таблиц
CTE материализации - ROW_NUMBER() становится неэффективным при:
Большом объеме данных (более 2M строк)
Недостаточной work_mem для полной сортировки
Глубокой пагинации (большой OFFSET)
Характерные особенности производительности СУБД
❓Проанализируй данные производительности(чем выше значение тем выше производительность) и ожиданиям СУБД в ходе нагрузочного тестирования для разных тестовых запросов . Выдели ключевые особенности
1. Анализ операционной скорости:
ROW_NUMBER():
- Начальная скорость: 30
- Максимальная: 36 (с 61 по 88 измерения)
- Спад: Падение до 26 при максимальной нагрузке (22 сессии)
- Коэффициент детерминации R² = 0 - нет линейной зависимости от нагрузки
- Угол наклона 1.59 - минимальный рост производительности
Deferred Join:
- Начальная скорость: 30
- Максимальная: 48 (с 59 по 93 измерения)
- Стабильность: Сохраняет 46-48 даже при 22 сессиях
- Коэффициент детерминации R² = 0.79 - сильная линейная зависимость
- Угол наклона 41.6 - значительный рост производительности с нагрузкой
Вывод: Deferred Join показывает на 33-45% выше производительность и лучше масштабируется.
2. Анализ ожиданий СУБД (WAITINGS):
ROW_NUMBER():
- Начальные ожидания: 2047 событий
- Максимальные: 17212 событий (рост в 8.4 раза)
- Коэффициент детерминации R² = 0.93 - очень сильная линейная зависимость
- Угол наклона 43.91 - резкий рост ожиданий с нагрузкой
Deferred Join:
- Начальные ожидания: 842 событий (в 2.4 раза меньше!)
- Максимальные: 4683 события (рост в 5.6 раза)
- Коэффициент детерминации R² = 0.76 - умеренная зависимость
- Угол наклона 41.08 - более плавный рост
Вывод: ROW_NUMBER() создает в 2-4 раза больше ожиданий и хуже масштабируется.
3. Анализ типов ожиданий:
Корреляция SPEED-WAITINGS:
- ROW_NUMBER(): -0.04 (отсутствие корреляции)
- Deferred Join: 0.64 (умеренная положительная корреляция)
Интерпретация: Для ROW_NUMBER() рост ожиданий не приводит к росту производительности, в то время как Deferred Join эффективно использует ожидания для увеличения throughput.
Основные типы ожиданий:
ROW_NUMBER():
- IO ожидания (корр. 1.0) - доминирующий тип, рост с 693 до 3,585
- IPC ожидания (корр. 1.0) - рост с 1313 до 13415
- LWLOCK ожидания (корр. 0.98) - рост с 37 до 136
Deferred Join:
- IO ожидания (корр. 0.97) - рост с 588 до 2,518
- IPC ожидания (корр. 0.92) - рост с 247 до 1912
- LWLOCK ожидания (корр. 0.97) - рост с 6 до 226
4. Паттерны поведения под нагрузкой:
Критические точки ROW_NUMBER():
- Измерение 46 (10 сессий): Скачок ожиданий с 2,396 до 4,861 (+103%)
- Измерение 92 (18 сессий): Падение скорости с 34 до 32 ops/sec
- Измерение 93 (22 сессии): Резкое падение скорости с 32 до 26 ops/sec (-19%)
Stability Deferred Join:
- Плавный рост скорости до 48 ops/sec
- Отсутствие резких падений даже при 22 сессиях
- Более эффективное использование ресурсов (меньше ожиданий на единицу производительности)
5. Анализ нагрузки :
Корреляция с производительностью:
ROW_NUMBER():
- 5-10 сессий: 30-32
- 12-13 сессий: 32-36 (оптимальный диапазон)
- 15+ сессий: Начинается деградация
- 22 сессии: 26 ops/sec (падение на 28% от пика)
Deferred Join:
- 5-10 сессий: 30-34
- 12-13 сессий: 38-48 (рост на 58%)
- 15+ сессий: Стабильные 46-48
- 22 сессии: 46-48 (сохранение пиковой производительности)
6. Принципиальные выводы:
Преимущества Deferred Join:
- Выше производительность: +33-45%
- Лучшая масштабируемость: Линейный рост до 48
- Меньше ожиданий: В 2-4 раза меньше системных ожиданий
- Стабильность: Сохранение производительности при максимальной нагрузке
- Эффективность использования ресурсов: Меньше IO/операций на запрос
Проблемы ROW_NUMBER():
- Плохая масштабируемость: Деградация при 15+ сессиях
- Высокие системные ожидания: Особенно IO и IPC
- Неэффективное использование памяти: Disk sort при work_mem=128MB
- Резкие переходы: Скачки в ожиданиях и падения производительности
Итог: Deferred Join демонстрирует превосходство по всем ключевым метрикам производительности и масштабируемости в данном сценарии нагрузочного тестирования.
Метрики производительности инфраструктуры
❓Проанализируй показатели метрик vmstat в ходе нагрузочного тестирования для разных тестовых запросов . Выдели ключевые особенности по метрикам.
1. Анализ загрузки CPU:
ROW_NUMBER():
- cpu_us (user): 57% → 70% (рост на 23%)
- cpu_sy (system): 5% → 7% (рост на 40%)
- cpu_id (idle): 37% → 18% (падение на 51%)
- cpu_wa (iowait): 1% → 3% (рост в 3 раза)
Deferred Join:
- cpu_us: 60% → 88% (рост на 47%)
- cpu_sy: 3% → 5% (рост на 67%)
- cpu_id: 36% → 4% (падение на 89%)
- cpu_wa: 0% → 1% (минимальный рост)
Вывод: Deferred Join эффективнее использует CPU:
- На 26% выше user time (88% vs 70%)
- В 2.7 раза меньше idle time (4% vs 18%)
- Минимальные iowait ожидания
2. Анализ памяти:
ROW_NUMBER():
- swpd (swap): 231 → 300 (рост на 30%)
- free (свободно): 1231 → 1258 MB (минимальный рост)
- buff/cache: 4842 → 2965 MB (падение на 39%)
Deferred Join:
- swpd: 235 → 295 (рост на 26%)
- free: 858 → 1525 MB (рост на 78%)
- buff/cache: 5244 → 3151 MB (падение на 40%)
Вывод: Оба паттерна активно используют кэш, но Deferred Join:
- Освобождает больше памяти по мере работы
- Имеет меньший рост использования swap
- Более эффективное управление памятью
3. Анализ ввода-вывода (IO):
ROW_NUMBER():
- bi (block in): 2 → 37,001 (рост в 18,500 раз!)
- bo (block out): 49,280 → 61,210 (рост на 24%)
Deferred Join:
- bi: 160 → 28,771 (рост в 180 раз)
- bo: 4,655 → 33,109 (рост в 7 раз)
Критические различия:
- ROW_NUMBER() создает в 100+ раз больше операций чтения
- Пик чтения ROW_NUMBER(): 37001 vs 28771 (на 29% выше)
- ROW_NUMBER() имеет массовый disk sort (bi 37,001 при bo 61,210)
4. Анализ системных вызовов:
ROW_NUMBER():
- in (interrupts): 13,852 → 61,210 (рост в 4.4 раза)
- cs (context switches): 17,483 → 15,379 (падение на 12%)
Deferred Join:
- in: 7,215 → 31,557 (рост в 4.4 раза)
- cs: 3,905 → 11,470 (рост в 2.9 раза)
Вывод: ROW_NUMBER() создает:
- В 2.2 раза больше прерываний (61,210 vs 31,557)
- На 34% больше контекстных переключений (15,379 vs 11,470)
5. Паттерны поведения под нагрузкой:
Критические точки ROW_NUMBER():
- Измерение 50-60 (10-12 сессий):
Резкий рост IO (bi до 11,056, bo до 77,593)
Снижение idle CPU с 37% до 12%
Начало активного использования swap - Измерение 80-90 (15-18 сессий):
Пик IO (bi до 33,075, bo до 80,290)
CPU idle падает до 14-15%
Рост iowait до 2%
Stability Deferred Join:
- Плавный рост всех метрик
- Без резких скачков в IO
- Стабильное использование CPU с постепенным снижением idle
6. Корреляция с нагрузкой (load.txt):
При 5-10 сессиях:
- ROW_NUMBER(): CPU 57-59%, IO низкий
- Deferred Join: CPU 60-61%, IO умеренный
При 12-13 сессиях:
- ROW_NUMBER(): CPU 59-80%, IO взрывной рост
- Deferred Join: CPU 61-92%, IO плавный рост
При 22 сессиях:
- ROW_NUMBER(): CPU 69-70%, IO 32-37K, высокий iowait
- Deferred Join: CPU 88-94%, IO 28-33K, минимальный iowait
7. Ключевые выводы:
Преимущества Deferred Join:
- Эффективнее использует CPU: 94% user time vs 70%
- Меньше системных прерываний: В 2.2 раза меньше
- Контролируемый рост IO: Без резких скачков
- Минимальный iowait: 0-1% vs 2-3%
- Лучшее управление памятью: Больше свободной памяти
Проблемы ROW_NUMBER():
- Экспоненциальный рост IO операций: В 18,500 раз!
- Высокий iowait: В 3 раза больше
- Массовые контекстные переключения: Снижают эффективность
- Активное использование swap: Признак нехватки памяти
- Резкие переходы: Скачки в метриках
8. Принципиальные различия в архитектуре:
ROW_NUMBER():
- Дисковый паттерн: Частые операции чтения/записи
- Перегрузка памяти: Активное использование swap
- CPU-IO дисбаланс: Высокий iowait мешает CPU
Deferred Join:
- CPU-центричный паттерн: Максимальная загрузка процессора
- Эффективный кэш: Плавное использование диска
- Сбалансированная работа: Минимальные простои
Итог:
Deferred Join демонстрирует более эффективное использование системных ресурсов, особенно CPU и памяти, при меньшей нагрузке на подсистему ввода-вывода. ROW_NUMBER() страдает от проблем с производительностью из-за массовых дисковых операций и неэффективного использования памяти.
Анализ ошибочного прогноза нейросети
Вопрос нейросети
Почему не оправдался прогноз нейросети о большей эффективности метода ROW_NUMBER для заданных условий ?
Ответ нейросети
Критический анализ причин несостоятельности прогноза нейросети:
1. Ошибка в исходных предпосылках:
Прогноз предполагал:
- Фильтрация fare_conditions = 'Business' сократит данные до 10-15% (1.5-2.3M строк)
Реальность из планов выполнения:
- filtered_tickets возвращает 2.1M строк (не 1.5-2.3M)
- Это 13.5% от tickets, но:
15.5M → 2.1M = 13.5% ✓
Однако объем данных для сортировки все еще огромен
2. Фундаментальные ошибки в анализе:
Ошибка 1: Игнорирование стоимости соединения таблиц
Прогноз не учел, что:
- Фильтрация требует Hash Semi Join между tickets (15.5M) и segments (20.5M)
- Это дорогостоящая операция, которая выполняется до применения ROW_NUMBER()
- В плане: Parallel Hash Semi Join занимает 3.3-5.7 секунд
Ошибка 2: Непонимание работы оконных функций в PostgreSQL
- ROW_NUMBER() не может использовать индексы для сортировки после фильтрации
- Даже с idx_tickets_covering, сортировка происходит после фильтрации
- В плане: Sort Method: external sort Disk: 102104kB
Ошибка 3: Неправильная оценка покрывающих индексов
- Индекс idx_tickets_covering уже существует (из описания схемы)
- Но он не используется в плане ROW_NUMBER()
- Причина: оптимизатор выбирает параллельное сканирование вместо индексного
3. Ключевые факторы, которые нейросеть проигнорировала:
Фактор 1: Work_mem ограничения
- При work_mem=128MB сортировка 2.1M строк происходит на диске
- Это добавляет 7.6-8.0 секунд к времени выполнения
- Deferred Join использует top-N сортировку в памяти
Фактор 2: Параллельные workers
- ROW_NUMBER() использует 4 параллельных workers
- Каждый worker использует 138MB памяти для hash join
- При 22 сессиях это 14.85GB - больше доступной памяти
Фактор 3: Реальные метрики производительности
Из тестирования видно:
- ROW_NUMBER(): 15.7 секунд, деградация при 15+ сессиях
- Deferred Join: 11.8 секунд, стабильная работа при 22 сессиях
4. Почему прогноз был оптимистичным для ROW_NUMBER():
Теоретические предположения vs реальность:
5. Условия, при которых ROW_NUMBER() действительно был бы эффективнее:
Сценарий 1: Маленький результат фильтрации
Если бы fare_conditions = 'Business' возвращал не 2.1M, а ≤ 100K строк
Сценарий 2: Адекватный размер work_mem
Если бы work_mem был ≥ 256MB для сортировки в памяти
Сценарий 3: Индексная организация данных
Если бы таблица была кластеризована по ticket_no
Сценарий 4: Отсутствие параллелизма
Если бы запросы выполнялись последовательно, а не параллельно
6. Что прогноз упустил из реальных планов выполнения:
Из плана ROW_NUMBER():
Sort Method: external sort Disk: 102104kB # Критично!
WindowAgg: 7640ms - 8702ms # Очень дорого
Rows Removed by Join Filter: 2158485 # Неэффективно
Из плана Deferred Join:
Sort Method: top-N heapsort Memory: 16673kB # Эффективно
Limit: rows=100 # Минимум работы
7. Уроки для будущих прогнозов:
Обязательно учитывать:
- Размер work_mem и его влияние на сортировку
- Реальные планы выполнения, а не теоретические индексы
- Параллелизм и конкуренцию за ресурсы
- Объем данных после фильтрации
- Стоимость соединений перед применением оконных функций
8. Заключение:
Прогноз нейросети не оправдался потому, что:
- Переоценил эффект фильтрации (2.1M строк все равно много)
- Игнорировал ограничения work_mem (дисковая сортировка)
- Не учел стоимость предварительных соединений
- Предположил использование индексов, которые не применяются
- Не учел влияние параллелизма на производительность
Реальный вывод:
Deferred Join оказался эффективнее из-за использования top-N сортировки в памяти, меньшего потребления ресурсов и лучшей масштабируемости при параллельных сессиях. ROW_NUMBER() страдает от необходимости полной сортировки больших объемов данных и ограничений памяти.
какие значение work_mem необходимо установить для получения преимущества метода row_number при максимальной нагрузке 22 параллельные сессии при общем размере RAM=8GB ?
Расчет work_mem для преимущества ROW_NUMBER() при 22 параллельных сессиях на 8GB RAM:
Анализ текущей ситуации:
- Текущий work_mem = 128MB вызывает проблему:
Сортировка на диске (Disk: 102104kB ≈ 100MB) в плане ROW_NUMBER()
Hash Join использует Memory Usage: 138464kB ≈ 135MB в каждом worker - Параллелизм:
В плане ROW_NUMBER() используются 4 worker + 1 leader = 5 процессов
При 22 параллельных сессиях в худшем случае: 22 × 5 = 110 процессов
Расчет оптимального work_mem:
1. Общая доступная память:
- Total RAM = 8GB = 8192MB
- Рекомендуется оставить 25% для ОС и других процессов: 6144MB для PostgreSQL
2. Требования для ROW_NUMBER() для одной сессии:
Из плана видно:
- Сортировка требует: ~100MB (102104kB)
- Hash Join требует: ~135MB (138464kB)
- Пиковое использование на одну сессию: ~135MB (т.к. операции не выполняются одновременно)
3. Учет параллелизма:
Для 22 параллельных сессий без параллельных workers:
- 22 × 135MB = 2970MB (2.97GB)
Но при использовании параллельных workers (как в плане):
- 22 сессии × (4 workers × 135MB + leader 135MB) = 22 × 675MB = 14850MB (14.85GB) ❌
4. Ограничение параллелизма:
Чтобы уместиться в 6144MB:
- Максимальный work_mem = 6144MB / 22 сессии = 279MB на сессию
- Но это без учета параллельных workers!
5. Рекомендуемые настройки:
Вариант A: Оптимальный для ROW_NUMBER() с параллелизмом:
sql
work_mem = 200MB -- Достаточно для сортировки в памяти
max_parallel_workers_per_gather = 1 -- Ограничиваем параллелизм внутри запроса
Вариант B: Для максимальной производительности ROW_NUMBER():
sql
work_mem = 256MB
max_parallel_workers_per_gather = 0 -- Отключаем параллелизм в запросах
effective_cache_size = 6GB
shared_buffers = 2GB
Вариант C: Компромиссный (рекомендуемый):
sql
work_mem = 180MB
max_parallel_workers_per_gather = 2 -- Ограничиваем до 2 workers
max_parallel_workers = 8 -- Общее количество параллельных workers
max_worker_processes = 8
Расчет для 22 сессий с ограниченным параллелизмом:
При max_parallel_workers_per_gather = 1:
- На сессию: 1 worker × 180MB + leader 180MB = 360MB
- На 22 сессии: 22 × 360MB = 7920MB (но операции не все одновременно!)
- Реальная пиковая нагрузка: ~22 × 180MB = 3960MB ✓ Вписывается в 6144MB
Почему именно эти значения:
- 180-200MB достаточно для:
Сортировки 2.1M строк в памяти (100MB + запас)
Hash Join в памяти (135MB + запас)
Избежания disk sort - Ограничение параллелизма необходимо потому что:
Полный параллелизм (4 workers) требует 14.85GB при 22 сессиях
При 8GB RAM это невозможно без swapping - Преимущество ROW_NUMBER() проявится при:
Отсутствии disk sort (work_mem ≥ 180MB)
Ограниченном параллелизме (чтобы не исчерпать память)
Использовании индексов (рекомендуется добавить индексы из предыдущего ответа)
Финальные рекомендации:
sql
-- Для получения преимущества ROW_NUMBER():
SET work_mem = '180MB';
SET max_parallel_workers_per_gather = 1;
SET max_parallel_workers = 16;
-- В postgresql.conf:
work_mem = 180MB
max_parallel_workers_per_gather = 1
max_parallel_workers = 16
max_worker_processes = 16
shared_buffers = 2GB
effective_cache_size = 6GB
Проверка: При этих настройках ROW_NUMBER() будет работать без disk sort, используя ~4GB памяти при 22 сессиях, что вписывается в доступные 6GB для PostgreSQL.