Исследователи компании DeepSeek в понедельник выпустили экспериментальную модель V3.2-exp, которая должна значительно снизить затраты на работы с длинным контекстом. Анонс был сделан на платформе Hugging Face вместе с публикацией научной статьи [PDF] на GitHub.
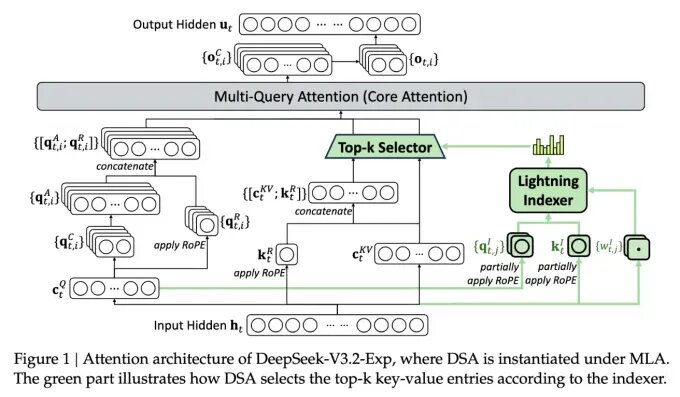
Главная особенность новой модели получила название DeepSeek Sparse Attention. Система строится на двух ключевых модулях:
- lightning indexer – выделяет наиболее важные фрагменты из длинного контекстного окна
- fine-grained token selection system – выбирает отдельные токены внутри этих фрагментов для загрузки в ограниченное окно внимания модели.
Такой подход позволяет эффективно обрабатывать длинные последовательности без значительных нагрузок на сервер.
Первые тесты показали заметные результаты: в длинноконтекстных задачах стоимость простого API-запроса может снижаться почти вдвое. Хотя для окончательной оценки требуется больше испытаний, открытые веса и свободный доступ к модели на Hugging Face ускорят независимую проверку этих заявлений.
Разработка DeepSeek стала частью серии прорывов, направленных на снижение расходов на «умозаключения» модели — то есть эксплуатационных затрат при работе с уже обученной нейросетью, в отличие от затрат на её обучение. В данном случае исследователи искали способы повысить эффективность самой архитектуры и показали, что улучшения всё ещё возможны.
Компания DeepSeek, базирующаяся в Китае, давно выделяется на фоне глобальной ИИ-гонки, которую многие описывают как противостояние США и Китая. В начале года она уже привлекла внимание моделью R1 обошедшей американских конкурентов по стоимости обучения. Однако, вопреки прогнозам, R1 не вызвала революции на рынке, и компания на время ушла в тень.
Новая технология вряд ли вызовет столь же громкий резонанс, как R1, но может стать полезным уроком и для американских провайдеров, помогая им снижать издержки на работу ИИ-сервисов.
Ещё по теме: