🔥 Разбор того, как Mixture-of-Experts (MoE) LLM можно сделать реально дешёвыми, если подогнать архитектуру под железо.
В чём проблема
- MoE включает только часть экспертов на токен → экономия compute.
- Но при больших batch size растут коммуникации и память:
- больше экспертов грузится,
- KV-кэш раздувается,
- узким местом становится память и сеть.
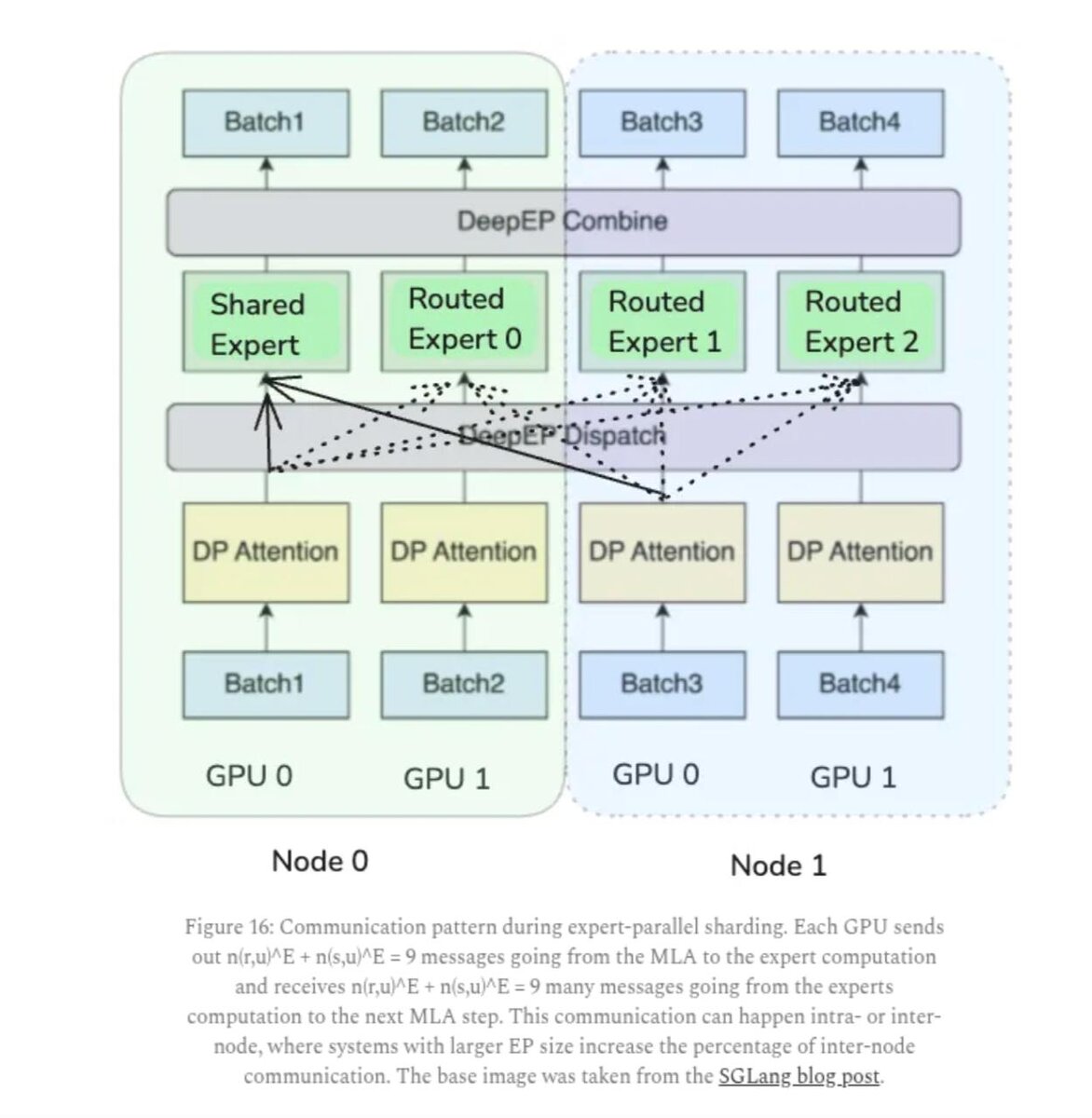
Решение - expert parallelism
- Эксперты размазаны по многим GPU.
- Токен идёт к top-N экспертам + shared-эксперт.
- В DeepSeek: 8 экспертов из 256 на слой × 58 слоёв.
Чтобы справиться с коммуникациями:
- внимание остаётся data parallel (кэш сидит на одном GPU),
- гоняются только маленькие вектора активаций,
- два микробатча: один считает, другой общается,
- горячие эксперты дублируются,
- токены стараются держать экспертов в пределах одного узла.
Оптимизации
- multi-head latent attention → сжатие KV-кэша до ~70KB вместо сотен KB.
- перестройка математики внимания → меньше вычислений при длинных контекстах.
- prefill и decode разделены, кэш даёт ~56% хитов → меньше затрат.
Экономика
- Стоимость = $/GPU-час ÷ токены/час.
- Дешевле при больших batch size, быстрых interconnect, большем числе GPU.
- Но если сервис обещает 20 токенов/сек на юзера → батчи меньше, цена выше.
Практика
- NVLink кластеры масштабируются отлично.
- InfiniBand между DGX - bottleneck.
- 72 GPU при batch 64 → миллиарды токенов в день за ~$0.40 / 1M токенов.
Итог
MoE становятся дёшевыми при:
- больших батчах,
- сжатом KV-кэше,
- грамотном роутинге,
- разделении префилла и декода,
- быстрых interconnect.
Это даёт гибкость: быстрый чат продаётся дороже, а bulk-генерация (синтетика, fine-tune) идёт почти по себестоимости.
https://www.tensoreconomics.com/p/moe-inference-economics-from-first