ℹ️Работы по проекту "PG_HAZEL"-завершены.Исследования продолжены в проекте PG_EXPECTOℹ️

Стратегическая цель
Начало работ
Продолжение работ
Задача
Протестировать возможности и результаты использования cемантического анализа текста и технологии обработки естественного языка (NLP) при анализе инцидента производительности СУБД .
Инцидент снижения производительности СУБД
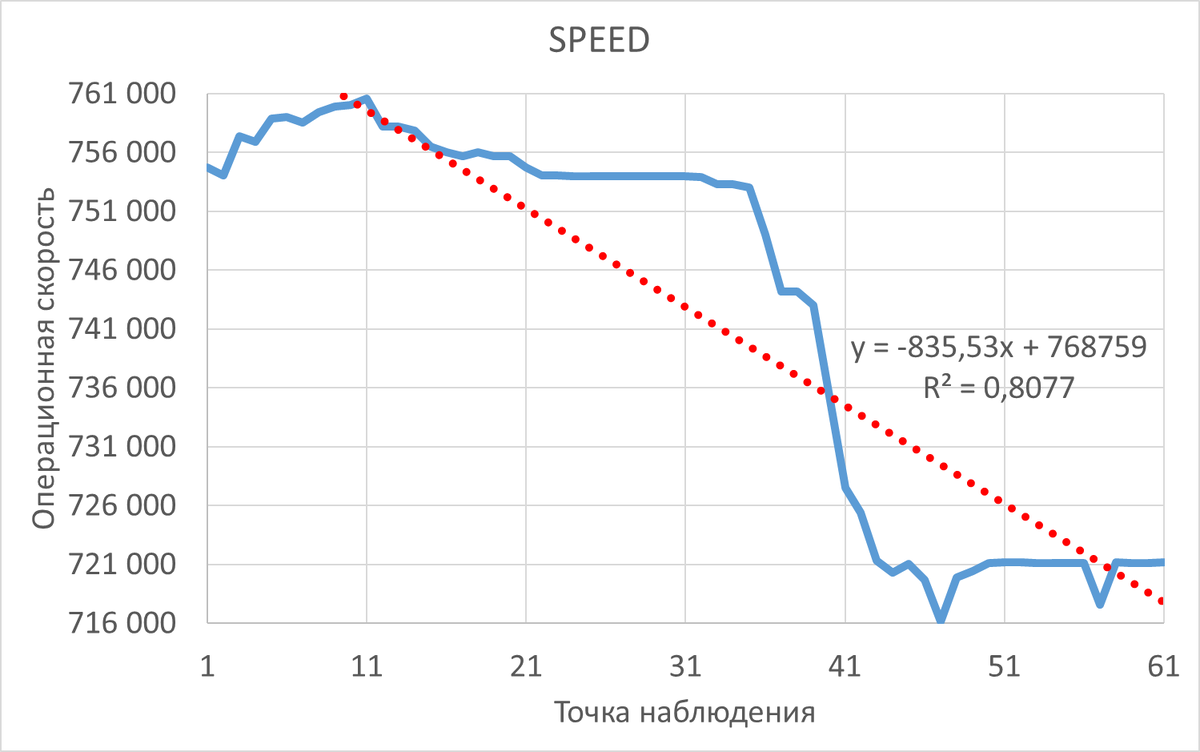
Корреляция ожиданий
Исходные данные для семантического анализа
80% ожидания СУБД (диаграмма Парето)
80% SQL-запросы, вызывающие ожидания (диаграмма Парето)
Семантический анализ ожиданий типа IO (DataFileRead)
🎯 Общие категории оптимизации:
1. Настройка памяти и кэширования
- Увеличение shared_buffers для эффективного кэширования данных
- Настройка work_mem для операций в памяти вместо диска
2. Оптимизация запросов и схемы данных
- Создание индексов для замены последовательных сканирований на индексные
- Борьба с "вздутием" индексов через переиндексацию
- Использование партиционирования больших таблиц
- Анализ и переписывание "тяжелых" запросов
3. Обслуживание базы данных
- Настройка агрессивного автовакуума
- Регулярное выполнение VACUUM и ANALYZE
- Оптимизация параметров autovacuum_vacuum_scale_factor и autovacuum_analyze_scale_factor
4. Масштабирование инфраструктуры
- Увеличение аппаратных ресурсов (RAM, быстрые диски)
- Использование реплик для распределения нагрузки
🔄 Смысловые совпадения:
Важность профилактики операций ввода-вывода через:
- Кэширование в памяти вместо чтения с диска
- Эффективное использование индексов
- Регулярное обслуживание для предотвращения "вздутия"
- Правильное планирование ресурсов
Все рекомендации направлены на сокращение физических операций чтения с диска, что является общей целью при оптимизации производительности PostgreSQL.
Семантический анализ ожиданий типа IPC (BgWorkerShutdown, ParallelFinish, ExecuteGather, BufferIO)
🎯 Общие категории оптимизации:
1. Управление параллельными операциями
- Настройка параметров max_parallel_workers_per_gather, max_worker_processes, max_parallel_workers
- Балансировка количества параллельных процессов для избежания конкуренции за ресурсы
- Отключение параллелизма для быстрых запросов через SET max_parallel_workers_per_gather = 0
2. Оптимизация запросов и планов выполнения
- Анализ планов запросов с помощью EXPLAIN (ANALYZE, BUFFERS)
- Обновление статистики через ANALYZE для улучшения решений оптимизатора
- Выявление и оптимизация проблемных запросов с высокими ожиданиями
3. Настройка памяти и ресурсов
- Увеличение shared_buffers для кэширования данных в памяти
- Настройка work_mem для операций сортировки и хеширования в памяти
- Оптимизация maintenance_work_mem для операций обслуживания
4. Управление системными ресурсами
- Мониторинг загрузки CPU и дисковой подсистемы
- Обеспечение достаточности ресурсов для обработки параллельных рабочих нагрузок
- Настройка контрольных точек через max_wal_size и checkpoint_timeout
5. Обслуживание базы данных
- Борьба с "вздутием" таблиц и индексов
- Создание и оптимизация индексов для условий WHERE и JOIN
- Управление подключениями через пулы соединений
🔄 Смысловые совпадения:
Ключевые пересекающиеся темы:
- Параллельные операции - центральная проблема в трех из четырех типов ожиданий
- Эффективность использования памяти - критически важна для всех типов оптимизации
- Балансировка нагрузки - необходимость согласования параллелизма с доступными ресурсами
- Качество индексов - влияет как на параллельные операции, так и на эффективность буферного ввода-вывода
Общий подход: Все рекомендации направлены на снижение накладных расходов и оптимизацию распределения ресурсов между конкурирующими процессами в PostgreSQL.
Семантический анализ ожиданий типа LWLock (ParallelHashJoin, LockManager, BufferMapping, BufferContent)
🎯 Общие категории оптимизации:
1. Настройка памяти и ресурсов
- Увеличение shared_buffers - для улучшения кэширования данных
- Оптимизация work_mem - предотвращение операций на диске
- Настройка hash_mem_multiplier - для хэш-операций
- Мониторинг эффективности кэша через BufferCacheHitRatio
2. Управление параллелизмом
- Настройка max_parallel_workers_per_gather - ограничение параллельных процессов
- Контроль max_parallel_workers - общее количество параллельных воркеров
- Отключение параллелизма для быстрых запросов через SET max_parallel_workers_per_gather = 0
3. Оптимизация индексов и схемы БД
- Борьба с раздутостью (Bloat) таблиц и индексов
- Удаление неиспользуемых индексов - снижение нагрузки при операциях записи
- Создание частичных индексов где это применимо
- Обновление статистики через ANALYZE
4. Оптимизация запросов и рабочей нагрузки
- Анализ планов запросов с помощью EXPLAIN (ANALYZE, BUFFERS)
- Сокращение времени транзакций - уменьшение времени удержания блокировок
- Снижение конкуренции за "горячие" данные
- Пересмотр логики приложения для уменьшения конфликтов
🔄 Смысловые совпадения:
Ключевые пересекающиеся темы:
- Эффективность использования памяти - центральная проблема для всех типов ожиданий
- Балансировка параллельных операций - предотвращение чрезмерной конкуренции
- Качество индексов - влияет на все аспекты производительности
- Своевременное обслуживание - VACUUM, ANALYZE, REINDEX
Общие технические подходы:
- Профилактика операций на диске - через адекватную настройку памяти
- Снижение конкуренции за ресурсы - через оптимизацию параллелизма
- Устранение избыточности - удаление неиспользуемых индексов и объектов
Универсальные рекомендации:
- Начинать с настройки памяти - как наиболее эффективный способ
- Анализировать конкретные запросы - через EXPLAIN и мониторинг
- Балансировать системные ресурсы - учитывать общую нагрузку
- Регулярно проводить обслуживание - для поддержания здоровья БД
Все рекомендации направлены на снижение конкуренции за ресурсы и оптимизацию распределения памяти, что является универсальным подходом для решения проблем с производительностью в PostgreSQL.
Семантический анализ SQL запросов, вызывающих события ожидания типа IO(DataFileRead)
🎯 Общие категории запросов:
1. Операции с аудитом и логированием
- Множественные INSERT INTO "auditLog" с похожей структурой
- UPDATE "public"."auditLog" - обновление записей аудита
2. Работа с планами развития (Improvement Plan)
- Запросы к таблицам: improvementPlan, improvementPlanGoal, improvementPlanGoalToCourse
- Сложные JOIN с связанными сущностями: курсы, сессии, провайдеры
- Фильтрация по periodYear, empCodeId, empCodeToPositionId
3. Управление организационной структурой
- Рекурсивные запросы с WITH RECURSIVE для иерархии подразделений
- Работа с таблицами: orgUnit, structureLink, empCodeToPosition
- Связи между позициями и организационными единицами
4. Работа с файлами и уведомлениями
- SELECT FROM "FileInfo" с JOIN к fileCategory
- INSERT INTO "notification" - создание уведомлений
- INSERT INTO "task" - управление задачами
5. Управление кадровым резервом (Succession Planning)
- Запросы к SuccessionPlan с связями к riskLeaving и successors
- Фильтрация по positionId и статусам workflow
🔄 Смысловые совпадения и паттерны:
Структурные паттерны:
- Шаблон мягкого удаления: почти все запросы используют "deleteDateTime" IS NULL или "isDeleted" = false
- Версионность данных: частые обращения к versionId, versionBeginDateTime
- Сложные JOIN: большинство запросов объединяют 3+ таблицы
Бизнес-контекст:
- Управление сотрудниками: запросы связаны с empCode, position, person
- Учебные процессы: курсы, сессии, планы развития
- Рекрутинг: заявки, кандидаты, предложения о работе
Технические особенности:
- Пагинация: использование LIMIT и ORDER BY
- Агрегации: COUNT, GROUP BY для статистики
- CTE (Common Table Expressions): сложные аналитические запросы
Типы операций:
- Чтение: 80% запросов - SELECT с различной сложностью
- Запись: INSERT в лог, уведомления, задачи
- Обновление: редкие UPDATE операций
Все запросы отражают работу HR-системы с акцентом на управление развитием сотрудников, организационной структурой и процессами найма.
Семантический анализ SQL запросов, вызывающих события ожидания типа IPC (BgWorkerShutdown, ParallelFinish, ExecuteGather, BufferIO)
🎯 Общие категории запросов:
1. Сложные JOIN-запросы с множественными связями
- Запросы объединяют 3+ таблицы через INNER JOIN и LEFT OUTER JOIN
- Пример: запрос к plans с соединениями к plans_meta, positions, plans_statuses, plans_meetings, plans_attributes
2. Рекурсивные запросы и CTE (Common Table Expressions)
- Использование WITH для создания временных результатов
- Рекурсивные запросы для иерархических данных организационной структуры
- Пример: запрос с orgUnitIds и responsible CTE
3. Работа с планами и задачами
- Запросы к таблицам plans, tasks, plans_tasks
- Сложные структуры с атрибутами и метаданными
4. Управление кадровым резервом (Succession Planning)
- Дублирующиеся запросы к SuccessionPlan с разными наборами positionId
- Связи с riskLeaving и successors
- Фильтрация по статусам workflow (65, 66)
🔄 Смысловые совпадения и паттерны:
Структурные паттерны:
- Шаблон мягкого удаления: "deleteDateTime" IS NULL, "deleted_at" IS NULL, "archiveDate" IS NULL
- Фильтрация по статусам: workflowStatusId NOT IN (65, 66) - исключение определенных статусов
- Массовые операции: positionId IN (85986, 81928, ...) - работа с наборами ID
Бизнес-контекст:
- HR-процессы: управление преемственностью, планами развития, задачами
- Организационная структура: иерархия подразделений, менеджеры, роли
- Система оценок: запросы к рейтингам сотрудников
Технические особенности:
- Сложные SELECT: много столбцов с алиасами, вложенные структуры
- Агрегации: COUNT(*), array_agg() для группировки данных
- Сортировка и лимиты: ORDER BY ... DESC LIMIT для получения последних записей
Производительность IPC:
- Межпроцессное взаимодействие: сложные запросы могут создавать нагрузку на координацию процессов
- Параллельные операции: рекурсивные запросы и агрегации могут использовать несколько рабочих процессов
- Блокировки ресурсов: операции с общими структурами данных
Все запросы характеризуются высокой сложностью и связаны с обработкой организационной иерархии и бизнес-процессов, что объясняет возникновение ожиданий типа IPC (Inter-Process Communication).
Семантический анализ SQL запросов, вызывающих события ожидания типа LWLock(ParallelHashJoin, LockManager, BufferMapping, BufferContent)
🎯 Общие категории запросов:
1. Массовые операции UPDATE
- Крайне большой UPDATE с 1000+ параметрами к таблице user
- UPDATE к таблице auditLog с множественными условиями WHERE
2. Сложные SELECT с множественными JOIN
- Запросы к SuccessionPlan с LEFT OUTER JOIN к riskLeaving и successors
- Сложные запросы к планам задач с 5+ JOIN операциями
- Запросы к ImprovementPlanGoalToCourse с пагинацией (LIMIT 200)
3. Операции вставки (INSERT)
- Многократные INSERT в auditLog и outbox_v1
- Операции с возвратом данных через RETURNING
4. Системные операции
- Повторяющиеся SET TimeZone='<+00>-00'
- Запросы к системным представлениям и outbox-очереди
🔄 Смысловые совпадения и паттерны:
Паттерны блокировок LWLock:
- Массовые операции: UPDATE с огромным количеством параметров создает длительные блокировки
- Конкуренция за ресурсы: одновременные операции к одним таблицам (auditLog, SuccessionPlan)
- Сложные транзакции: запросы с множественными JOIN могут удерживать блокировки долгое время
Бизнес-контекст:
- HR-процессы: управление преемственностью, планы развития, аудит действий
- Фоновые процессы: работа с outbox-очередью для асинхронной обработки
- Управление пользователями: массовые обновления статусов пользователей
Технические особенности:
- Условия фильтрации: "deleteDateTime" IS NULL, "archiveDate" IS NULL, workflowStatusId NOT IN (65, 66)
- Пагинация: LIMIT 200, LIMIT 500 OFFSET 5083075500 (очень большое смещение)
- Сортировка: ORDER BY "ImprovementPlanGoalToCourse"."id" ASC
Проблемные операции для LWLock:
- Длительные UPDATE: массовое обновление 1000+ записей в одной транзакции
- Частые INSERT: интенсивная запись в таблицы аудита и outbox
- Сложные SELECT: запросы с 5+ JOIN операциями, которые блокируют метаданные
Все запросы характеризуются операциями, которые могут создавать конкуренцию за легковесные блокировки (LWLocks), особенно при высокой параллельной нагрузке, что объясняет возникновение ожиданий этого типа.