ℹ️Работы по проекту "PG_HAZEL"-завершены.Исследования продолжены в проекте PG_EXPECTOℹ️

Реализация стратегической цели
План
- Производительность и ожидания СУБД в период инцидента
- Комплексный анализ инфраструктуры.
- Корреляционный анализ ожиданий СУБД.
- Рекомендации нейросети DeepSeek по снижению ожиданий.
- Проблемные SQL запросы для оптимизации.
- Анализ проблемного SQL запроса с использованием нейросети DeepSeek.
- Рекомендации по оптимизации проблемного SQL запроса с использованием нейросети DeepSeek.
- Оптимизация проблемного SQL запроса
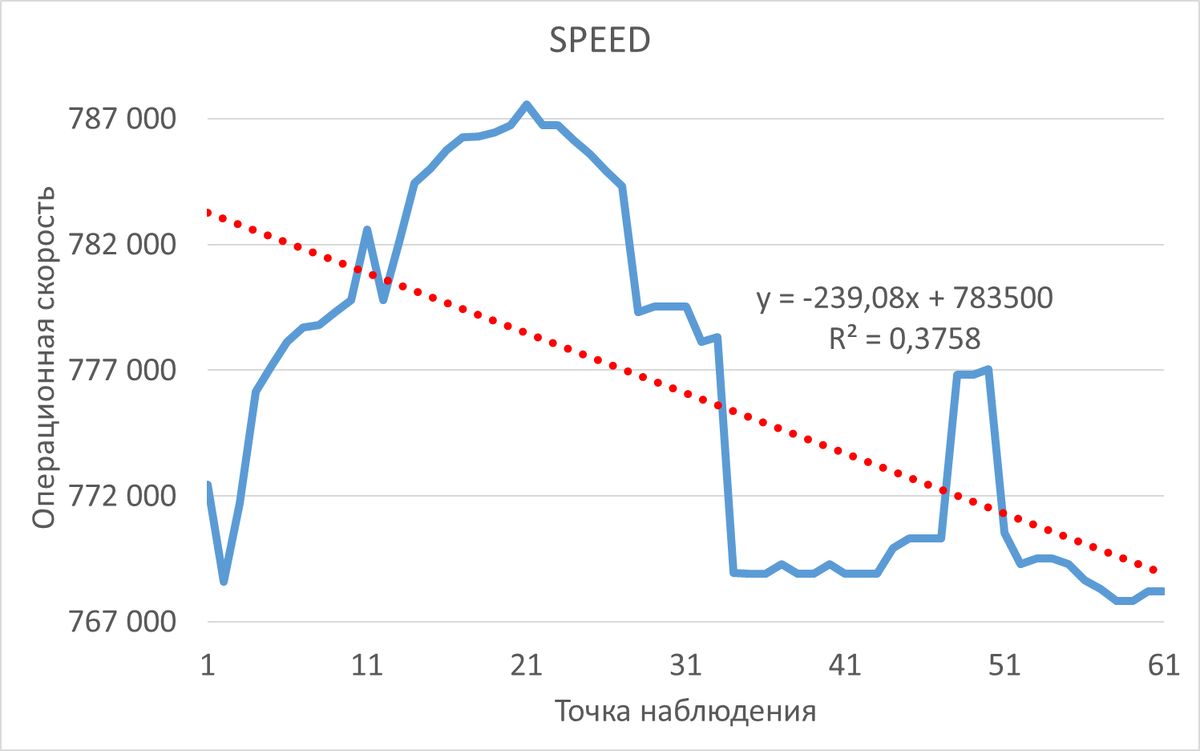
1. Производительности и ожидания СУБД в период перед инцидентом
2. Комплексный анализ инфраструктуры.
Корреляция ожиданий СУБД и метрик vmstat
Анализ метрик iostat для файловой системы /data
Чек-лист CPU
Чек-лист RAM
Результат
- Имеются проблемы производительности диска , используемого для файловой системы /data.
- Переключения контекста могут быть вызваны прерываниями IO.
- Свободная RAM - менее 5%.
3.Корреляционные анализ ожиданий СУБД и выявление проблемных SQL запросов для оптимизации.
Корреляция и типы ожиданий
Ожидания типа IO
Ожидания типа LWLock
Диаграмма Парето(80%) по событиям ожиданий
4.Рекомендации нейросети DeepSeek по снижению ожиданий
4.1 Получение рекомендаций по оптимизации ожиданий
DataFileRead
ParallelHashJoin
BufferMapping
LockManager
BufferContent
В случае отсутствия сохраненной рекомендации - обновить локальную базу знаний по оптимизации событий ожидания:
Вопрос нейросети :
Как уменьшить количество событий ожидания wait_event= YYY для СУБД PostgreSQL?
Ответ - сохранить в локальной базе знаний.
5. Проблемные SQL запросы для оптимизации.
Все проблемные запросы имеют ожидания DataFileRead . Причина - проблемы инфраструктуры.
Запросы имеющие ожидания типа LWLock
Запросы -583459049601560367 , -5849488707035427374 - проанализированы , ранее .
Запрос для оптимизации -4217442339750081997
6. Анализ проблемного SQL запроса с использованием нейросети DeepSeek.
Вопрос нейросети :
Выдели ключевые паттерны из SQL запроса :
Ключевые паттерны в SQL-запросе:
1. Точечная фильтрация по позиции
"table1"."col2" IN (871798)
- Фильтрация по конкретному col1 позиции (в отличие от предыдущих запросов со списками)
- Выборка данных для одной целевой позиции
2. Архитектура мягкого удаления (Soft Delete)
WHERE "table1"."col8" IS NULL
AND "table3"."col8" IS NULL
- Многоуровневая проверка на мягкое удаление
- Применяется к основной и связанным таблицам
3. Составные условия JOIN с бизнес-фильтрацией
LEFT OUTER JOIN ... ON "table1"."col1" = "table3"."table1col1"
AND ("table3"."col8" IS NULL
AND "table3"."col4" NOT IN (65, 66))
- Бизнес-логика в условиях JOIN, а не WHERE
- Исключение специфических workflow статусов (65, 66)
- Комбинация условий удаления и статусов
4. Система архивации записей
"table1"."col9" IS NULL
- Отдельный механизм архивации помимо мягкого удаления
- Дополнительный уровень управления жизненным циклом данных
5. LEFT JOIN для опциональных отношений
- `table2` - опциональная связь (риск ухода может отсутствовать)
- `table3` - опциональная связь с фильтрацией по статусам
6. Иерархическая модель данных
table1 (основа)
├── table2 (опциональный риск ухода)
└── table3 (преемники с фильтрацией)
- Древовидная структура с центральной сущностью table1
7. Паттерн именования алиасов
"table2"."col1" AS "table2.col1"
"table3"."col1" AS "table3.col1"
- Точечная нотация для представления отношений
- Четкое указание источника данных в результатах
8. Статусная модель workflow
- `col4` - управление рабочим процессом
- `col5` - статус кандидата
- `col6` - уровень готовности преемника
9. Экранирование идентификаторов
- Все имена в двойных кавычках для сохранения регистра
- Согласованное именование по всему запросу
Ключевые паттерны запроса
Этот запрос демонстрирует паттерн получения детализированных данных по конкретной позиции в системе управления преемственностью, с акцентом на актуальные, не архивные записи с активными преемниками.
7. Рекомендации по оптимизации проблемного SQL запроса с использованием нейросети DeepSeek.
Вопрос нейросети :
Какие способы оптимизации в СУБД PostgreSQL возможны для SQL запроса:
1. Создание специализированных индексов
Для таблицы `table1`:
-- Составной индекс для условий WHERE
CREATE INDEX CONCURRENTLY col1x_succession_plan_main
ON "table1" ("col2", "col8", "col9")
WHERE "col8" IS NULL AND "col9" IS NULL;
-- Индекс для связи с table2
CREATE INDEX CONCURRENTLY col1x_succession_plan_risk_leaving
ON "table1" ("table2col1")
WHERE "col8" IS NULL;
Для таблицы `col7`:
-- Оптимизированный индекс для JOIN с фильтрацией
CREATE INDEX CONCURRENTLY col1x_col7_filtered
ON "col7" ("table1col1", "col4", "col8")
WHERE "col8" IS NULL AND "col4" NOT IN (65, 66);
-- Альтернативный вариант для лучшей селективности
CREATE INDEX CONCURRENTLY col1x_col7_main
ON "col7" ("table1col1")
INCLUDE ("col4", "col5", "col6")
WHERE "col8" IS NULL;
2. Оптимизация структуры запроса
Рассмотрите рефакторинг условия:
-- Текущий вариант может быть оптимизирован
WHERE "table1"."col8" IS NULL
AND "table1"."col2" IN (871798)
AND "table1"."col9" IS NULL
-- Убедитесь, что порядок условий соответствует индексам
3. Оптимизация JOIN операций
Для больших объемов данных рассмотрите:
-- Разделение запроса на два с использованием CTE
WITH filtered_plans AS (
SELECT "col1", "col2", "table2col1"
FROM "table1"
WHERE "col8" IS NULL
AND "col2" IN (871798)
AND "col9" IS NULL
)
SELECT
fp."col1", fp."col2",
rl."col1" AS "table2.col1",
rl."col3" AS "table2.col3",
s."col1" AS "table3.col1",
s."col4" AS "table3.col4",
s."col5" AS "table3.col5",
s."col6" AS "table3.col6"
FROM filtered_plans fp
LEFT JOIN "table2" rl ON fp."table2col1" = rl."col1"
LEFT JOIN "col7" s ON fp."col1" = s."table1col1"
AND s."col8" IS NULL
AND s."col4" NOT IN (65, 66);
4. Настройки PostgreSQL:
-- Увеличьте work_mem для лучшей сортировки и хэширования
SET work_mem = '256MB';
-- Убедитесь, что effective_cache_size правильно настроен
SHOW effective_cache_size;
5. Дополнительные рекомендации
-Статистика по индексам: Убедитесь, что `default_statistics_target` достаточно высок для точной оценки селективности
- Параллельные запросы: Проверьте настройки `max_parallel_workers_per_gather` для больших таблиц
8. Оптимизация проблемного SQL запроса
Вопрос нейросети :
Какие способы оптимизации в СУБД PostgreSQL возможны для плана выполнения SQL запроса:
Дальнейшие шаги по оптимизации SQL запроса:
- Проведение изменений, предложенных в пунктах 7 и 8.
- Анализ влияния изменений на производительность SQL запроса и СУБД в целом.