Как соединить данные из разных топиков Apache Kafka с помощью пары SQL-запросов: коннекторы, материализованные представления и потоковая база данных вместо полноценного потребителя. Подробная демонстрация запросов в RisingWave.
Проектирование и реализация потоковой агрегации данных из Kafka в RisingWave
Вчера я показывала пример потоковой агрегации данных из разных топиков Kafka с помощью Python-приложения, которое потребляет данные о пользователях и событиях их поведения на сайтах из разных топиков Kafka и соединяет их по ключевому идентификатору. Сегодня рассмотрим, как решить эту задачу быстрее с помощью потоковой базы данных RisingWave и коннекторов к Kafka. RisingWave – это распределенная реляционная СУБД, которая позволяет работать с потоками данных как с обыкновенными таблицами с помощью SQL-запросов к постепенно обновляемым, согласованным материализованным представлениям. Результаты выполнения запросов можно сохранять в самой RisingWave или передавать их во внешние хранилища, также используя коннекторы. Как это сделать, я показываю в новой статье.
Постановка задачи и исходные данные аналогичны вчерашней демонстрации: в один топик Kafka публикуются данные о пользователях, а в другой – о событиях их пользовательского поведения. Скрипты публикации данных и схемы полезной нагрузки приведены здесь. Архитектура потоковой системы схематично будет выглядеть так:
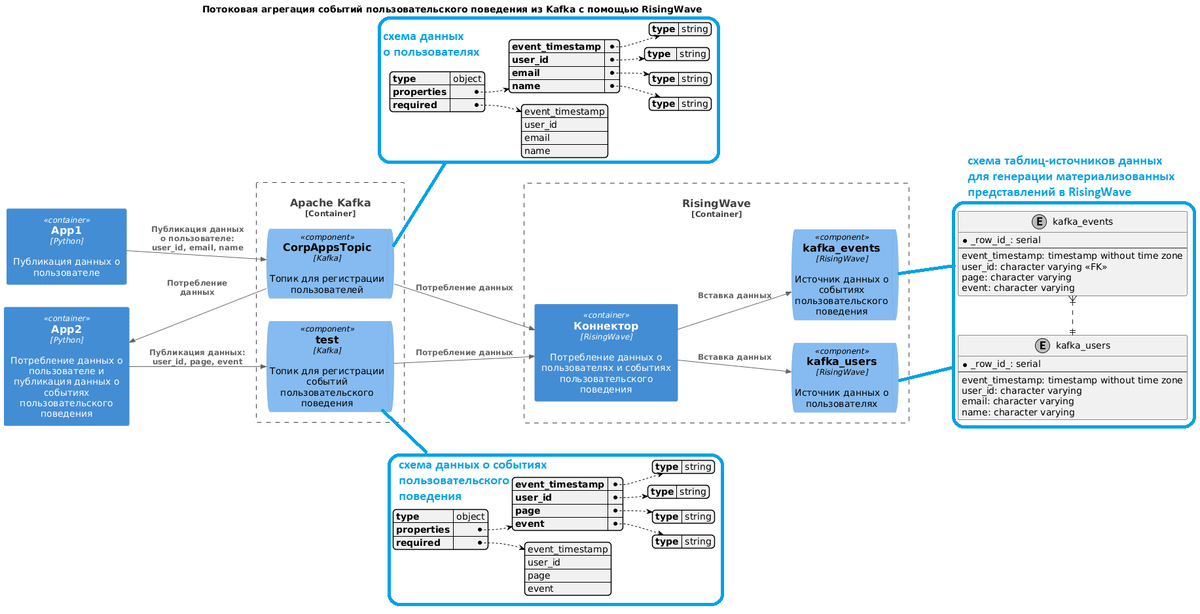
Для реализации этой потоковой системы в RisingWave надо сперва создать источники данных. Это делается с помощью SQL-инструкций. Для потребления данных из Kafka ее следует объявить как источник данных, используя одноименный коннектор. При подключении к источнику задаются не только учетные данные, но и формат полезной нагрузки, в моем случае это JSON. Код в RisingWave для создания источника данных о пользователях, публикуемых в топик Kafka под названием CorpAppsTopic, выглядит так:
Аналогично с помощью SQL-запроса создадим источник данных о событиях пользовательского поведения, публикуемых в топик Kafka под названием test:
После этого можно создать материализованное представление для агрегации данных по видам событий из источника данных о событиях пользовательского поведения:
Наконец, можно считать результаты агрегации:
Аналогично создадим материализованное представление для агрегации событий по веб-страницам, на которых пользователи совершают действия:
И прочитаем данные из этого материализованного представления:
Наконец, выведем информацию о пользователях и количестве событий, которые они совершили. Для этого сперва создадим соответствующее материализованное представление, которое соединяет данные из двух источников по ключу идентификатора пользователя и группирует их по этому же user_id.
Для просмотра результатов потоковой агрегации данных из разных топиков Kafka в RisingWave надо всего лишь сделать SQL-запрос на выборку к соответствующему материализованному представлению.
RisingWave распределяет свои вычисления по легковесным потокам, называемым «стриминговыми акторами», которые одновременно выполняются на ядрах ЦП. Распределяя потоковые данные по ядрам, RisingWave обеспечивает мощные параллельные вычисления с высокой производительностью, масштабируемостью и пропускной способностью. Выполняя потоковые задания обработки данных, RisingWave представляет их как SQL-запросы над непрерывно генерируемыми данными с помощью так называемых узлов. Вычислительные узлы отвечают за прием данных из систем-источников, анализ и выполнение SQL-запросов, а также доставку данных в системы-приемники. Узлы-уплотнители управляют хранением данных и извлечением из объектного хранилища, а также сжимают данные для оптимизации их хранения в БД.
В RisingWave при выполнении плана потокового запроса он делится на несколько независимых фрагментов для обеспечения параллельного выполнения. Каждый фрагмент представляет собой цепочку операторов SQL. Под капотом он выполняется параллельными акторами. Степень параллелизма между фрагментами может быть разной. Параллелизм относится к технике одновременного выполнения нескольких операций или запросов базы данных для повышения производительности и повышения эффективности. Он включает в себя разделение рабочей нагрузки базы данных на более мелкие задачи и их параллельное выполнение на нескольких процессорах или машинах. Просмотреть граф потокового запроса как визуализацию материализованного представления можно в GUI системы.
Если сравнить время на разработку приложения-потребителя, которое выполняет потоковую агрегацию и соединение данных из разных топиков, с использованием коннекторов и материализованных представлений, они сильно отличаются. Использование RisingWave намного ускоряет потоковую обработку и позволяет получить результаты агрегации событий из Kafka намного быстрее и проще. Кроме того, выполнить подобные вычисления может даже непрограммирующий аналитик, просто знакомый с SQL. Поэтому неудивительно, что в последнее время потоковые базы данных, подобные RisingWave, становятся все более популярны. Подробно о таких системах я писала здесь. Впрочем, они имеют довольно ограниченные возможности, не позволяя работать со всеми источниками и приемниками данных, которые могут встретиться в реальной жизни. Таким образом, знакомство с подобными системами – полезный навык для дата-инженера, но он не исключает необходимости разрабатывать полноценные приложения-потребители.
Как делать это эффективно с учетом всех особенностей Apache Kafka, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Копирование, размножение, распространение, перепечатка (целиком или частично), или иное использование материала допускается только с письменного разрешения правообладателя ООО "УЦ Коммерсант"



















