Что такое ClickHouse: Полный гид по колоночной СУБД для сверхбыстрой аналитики. Урок 1.
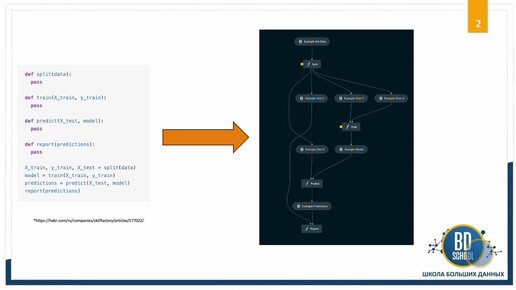
Если ваша работа связана с данными, вы наверняка слышали название ClickHouse. Это не просто очередная база данных, а мощный инструмент, который стремительно меняет подходы к аналитике в IT-компаниях по всему миру. В этой статье мы подробно разберемся, что же такое ClickHouse, почему он феноменально быстр в аналитических задачах и, самое главное, как вы можете начать с ним работать уже сегодня — как локально на своем компьютере, так и в облаке. Миссия: обрабатывать огромные объемы данных с максимальной...