CodeGeeX4-ALL-9B - мультиязычная модель для генерации кода, обученная на GLM-4-9B. Новая версия семейства позволяет поддерживать комплексные функции:
- завершение и генерация кода;
- интерпретатор кода;
- вопросы и ответы по коду на уровне репозитория;
- веб-поиск (при наличии агента)
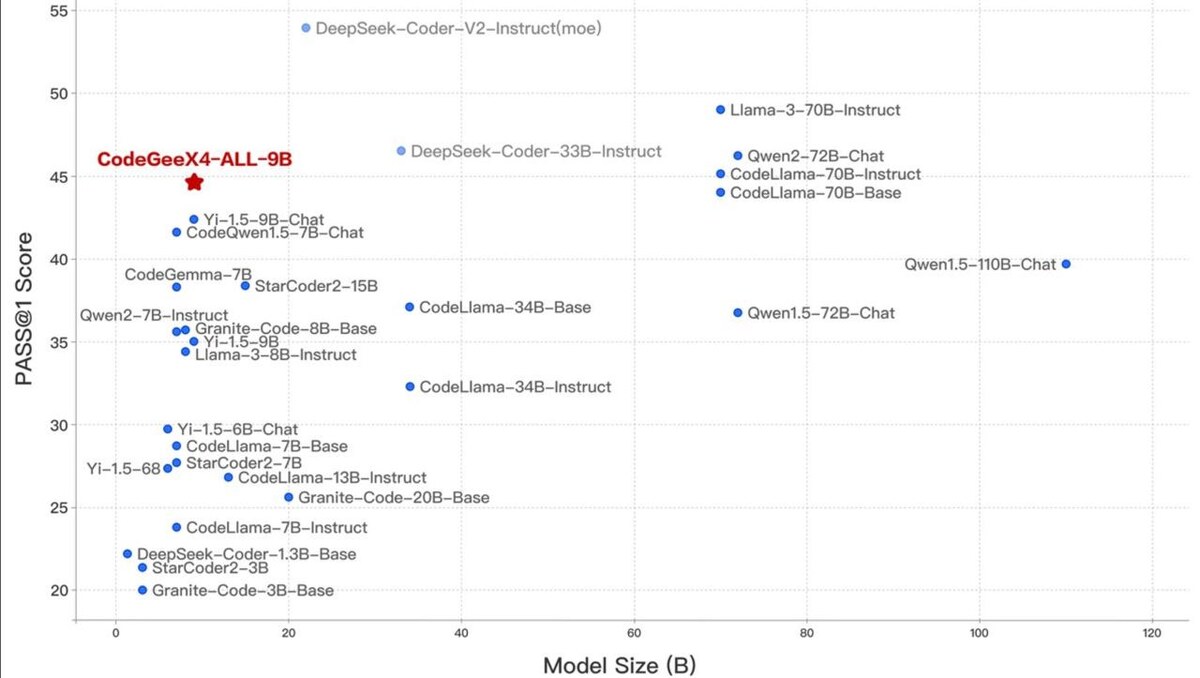
CodeGeeX4-ALL-9B показала конкурентоспособную производительность в общедоступных тестах BigCodeBench и NaturalCodeBench.
По заявлению авторов, это самая мощная модель генерации кода с числом параметров менее 10B, превосходящая в некоторых аспектах более крупные модели общего назначения и обеспечивающая лучший баланс между скоростью вывода и производительности модели.
⚠️ Лицензирование
Модель имеет собственный тип лицензирования:
- бесплатно и неограниченно для для научно-образовательных и исследовательских проектов
- коммерческие проекты должны пройти регистрацию в форме https://open.bigmodel.cn/mla/form и выполнять соблюдение условий
Запустить:
mport torch
from transformers import AutoTokenizer, AutoModelForCausalLM
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("THUDM/codegeex4-all-9b", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
"THUDM/codegeex4-all-9b",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
inputs = tokenizer.apply_chat_template([{"role": "user", "content": "write a quick sort"}], add_generation_prompt=True, tokenize=True, return_tensors="pt", return_dict=True ).to(device)
with torch.no_grad():
outputs = model.generate(**inputs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
🖥 https://github.com/THUDM/CodeGeeX4