Практическая демонстрация потокового SQL-конвейера, который преобразует данные, потребленные из Apache Kafka, и записывает результаты в Elasticsearch, используя Debezium-коннекторы и задания Apache Flink в облачной платформе Decodable.
Потребление сообщений из Apache Kafka
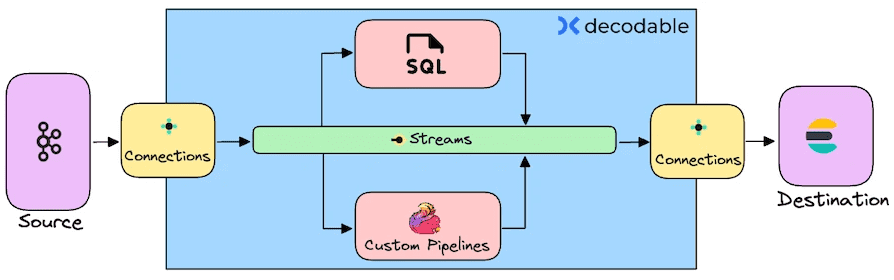
Я уже показывала пример интеграции Apache Kafka и Elasticsearch с помощью sink-коннектора, а также конвейер с ClickHouse Cloud. Сегодня совместим некоторые из этих прежних работ, чтобы протестировать облачную платформу Decodable на базе Apache Flink и Debezium. Она является полностью управляемым сервисом, который обеспечивает обработку данных в реальном времени. С Decodable можно получать данные из различных источников и направлять их в разные системы-приемники, а также преобразовывать и дополнять эти потоковые данные с помощью SQL или языка программирования на основе JVM (Java, Scala). Я буду использовать именно SQL в качестве основного средства построения потокового конвейера, суть которого состоит в извлечении данных из топика Kafka, их преобразовании и записи в Elasticsearch.
Как обычно, данные в Kafka, развернутой на платформе Upstash, буду публиковать с помощью простого Python-приложения, запускаемого в Google Colab, со следующим исходным кодом:
Этот Python-скрипт каждые 3 секунды генерирует и публикует в Kafka клиентские обращения от компаний или частных лиц: заявки на покупку товаров в интернет-магазине или вопросы по работе магазина.
Схема полезной нагрузки сообщения в формате JSON выглядит так:
Далее получим эти данные с помощью Debezium-коннектора в платформе Decodable. Поскольку Decodable основана на Apache Flink, она использует именно его термины при создании потокового конвейера. В частности, сперва нужно создать коннекторы к источникам и приемникам данных, настроив учетные записи подключения к внешним системам. Decodeable создает сетевые подключения к ресурсам, которые указаны в подключениях. Я создала 2 коннектора: Kafka как источник данных и Elasticsearch как приемник.
Преобразование потока данных и публикация в Elasticsearch
Предположим, нужно отправлять в индекс Elasticsearch под названием apps_index не все подряд обращения, а только те, которые являются заявками на покупку, а также количество позиций в каждой заявке. Чтобы сделать это, необходимо создать новый поток, который извлекает данные из исходного потока from_test_kafka, немного преобразует и обогащает их с помощью следующего SQL-запроса:
Протестировав и настроив источник и приемник данных, следует запустить оба подключения и сам настроенный конвейер, чтобы он работал непрерывно.
Статистика по принятым из источника и отправленным в приемник данным отображается в свойствах созданного конвейера.
Проверить, что данные, потребленные из Kafka, попадают в систему-приемник, т.е. Elasticsearch, можно из интерфейса самой это NoSQL-СУБД с помощью API поиска, отправив POST-запрос к /apps_index/_search с полезной нагрузкой для просмотра всех результатов:
Более наглядный вид содержимого индекса показывает веб-интерфейс панелей Kibana, интегрированный с Elasticsearch
Разумеется, вся информация о публикации и потреблении данных отображается в GUI веб-развертывания Kafka.
Разумеется, для практического использования полученной из Kafka информации, конвейер должен включать больше операций преобразования данных. В частности, чтобы построить поминутную или почасовую гистограмму получения заявок в Kibana, необходимо преобразовать типы полей индекса, чтобы поле producer_timestamp было не строкой, а датой и временем. Кроме того, следует преобразовать поле content, рассматривая его как документ, чтобы выполнять поиск по названию и количеству заказанных продуктов, а также строить по ним различные визуализации. Для этого SQL-запрос, преобразующий поток исходных данных из Kafka, будет намного сложнее.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Статья: https://bigdataschool.ru/blog/news/kafka/from-kafka-t..
Курсы: https://bigdataschool.ru/courses/apache-kafka-develop.. https://bigdataschool.ru/courses/apache-kafka-basics https://bigdataschool.ru/courses/apache-kafka-adminis.. https://bigdataschool.ru/courses/arenadata-streaming-..
Наш сайт: https://bigdataschool.ru
Копирование, размножение, распространение, перепечатка (целиком или частично), или иное использование материала допускается только с письменного разрешения правообладателя ООО "УЦ Коммерсант»