В недавней научной статье исследователи представили вывод, который на первый взгляд может показаться парадоксальным. Они провели эксперимент на модели RoBERTa, широко используемой в обработке естественного языка.
Обычный метод обучения модели на новом языке требует большого объема текстов на двух языках для сопоставления значений слов. Этот подход требует значительных вычислительных ресурсов и не всегда эффективен.
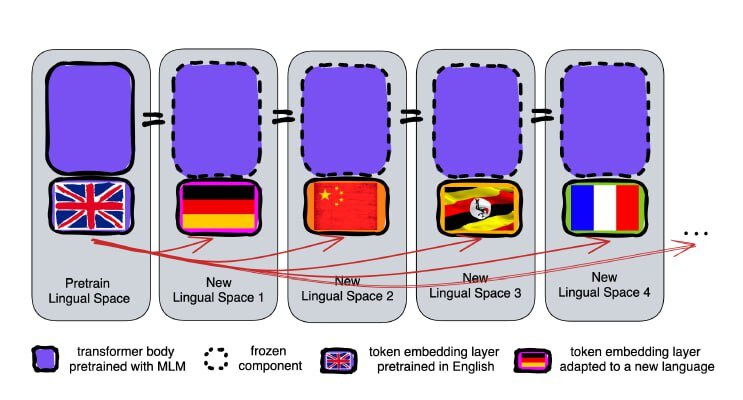
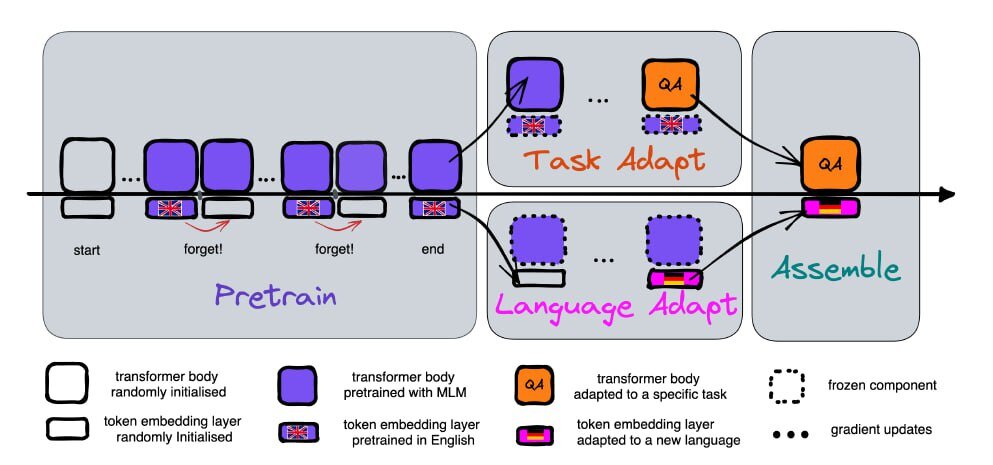
Исследователи предложили новый подход, удаляя слой векторного представления (embedding) перед обучением модели на новом языке, оставляя при этом другие слои нетронутыми. Слой embedding содержит информацию о конкретных словах в языке, в то время как более глубокие слои содержат абстрактные представления о языке. Удаление этого слоя перед обучением позволяет модели обучаться более эффективно.
Изначально модель, использующая этот подход, показала небольшое снижение производительности по сравнению с традиционным методом. Однако, когда исследователи начали обучать модели на других языках, используя меньшие наборы данных, эта модель оказалась более устойчивой. Точность стандартной модели снизилась значительно, в то время как модель с "забыванием" показала более высокую точность.
Это означает, что модель с "забыванием" учится аналогично тому, как учатся люди, абстрагируя и обобщая информацию, вместо того чтобы запоминать каждый детальный момент. Этот подход соответствует наблюдениям о том, что человеческая память не так эффективна в хранении больших объемов детальной информации, как в анализе и обобщении опыта. 🧠💡