Привет, друзья. Сегодня поговорим о письменностях Востока, дальнего и ближнего, и о том, какие возможности нам предоставляет Вим.

Материал про сами письменности Дальнего востока у меня тоже был, была и заметка про корейский алфавит Хангыль в Вим, которая не попала в очередь, а была опубликована. Там много интересного про письменность, раскладку и ошибку в раскладке, на которую автору раскладки указал автор этой заметки.
Начнем с китайского. Китайский язык пользуется "иероглифами": символами, обозначающими слово или понятие, и, как правило, читающимися как один слог. Это делает письменность чрезвычайно сложной для освоения (но я пытаюсь). Фонетика китайского тоже имеет особенность: она тональная. Иными словами, смысл слога зависит от интонации, с которой он произнесен. У нас в языке тоже есть интонация, но она относится ко всему предложению и редко когда сильно меняет смысл. Разве что "он идиот.", "он идиот!" и "он идиот?" в устной речи различаются лишь интонацией.
В китайском же mèn, mén, mēn и měn — четыре разных смысла, и произносятся они по-разному. Я записал эти слоги системой "пиньинь", призванной изображать китайскую речь латиницей.
Вводить иероглифы мы в (консольном) Вим не можем; а вот пиньинь нам доступен.
Это попросту латинский алфавит, но только там много диакритики. Дело в том, что в китайском пять тонов (обычно говорят о четырех, пятый "нейтральный"), так что для каждой гласной надо шесть символов: с одним из надстрочных знаков тона и без такового.
Все эти символы в Юникоде есть, цельные или сборные, но вопрос с клавишами на клавиатуре. Раскладка Вим решает этот вопрос просто: после гласной надо ввести номер тона, от 0 до 5. То есть, ē введем как e1, а вим заменит эту пару на что нужно (это диграф).
Раскладка называется pinyin. Вы можете ознакомиться с ней в $VIMRUNTIME/keymap/pinyin.vim и подключить как любую другую:
:set keymap=pinyin
После этого (это можно в .vimrc сделать) Вы можете набирать тексты пиньинем без всяких проблем. Переключение на пиньинь через <C-^>, обычно это совпадает с <C-6>.
Замечу напоследок, что иероглифы имеют одно очень важное преимущество: язык может сколь угодно сильно отличаться от китайского, но если он записан иероглифами, он будет понятен всякому, кто их знает.
Китайский язык идеально подходит под такую письменность: слова не изменяются. Русский так бы не смог, а вот английский — вполне, надо было бы только ing и s записывать отдельным значком, вместо прошедшего времени (went) писать всегда did go, и придумать что-то аналогичное для причастий (третья форма). Англичане, конечно, иероглифы не приняли и уже не примут, а вот японцы именно так и поступили.
Японская письменность носит статус самой запутанной. Помимо китайских символов, которые называются в Японии кандзи, в ходу еще две слоговые азбуки. Есть и латиница ромадзи.
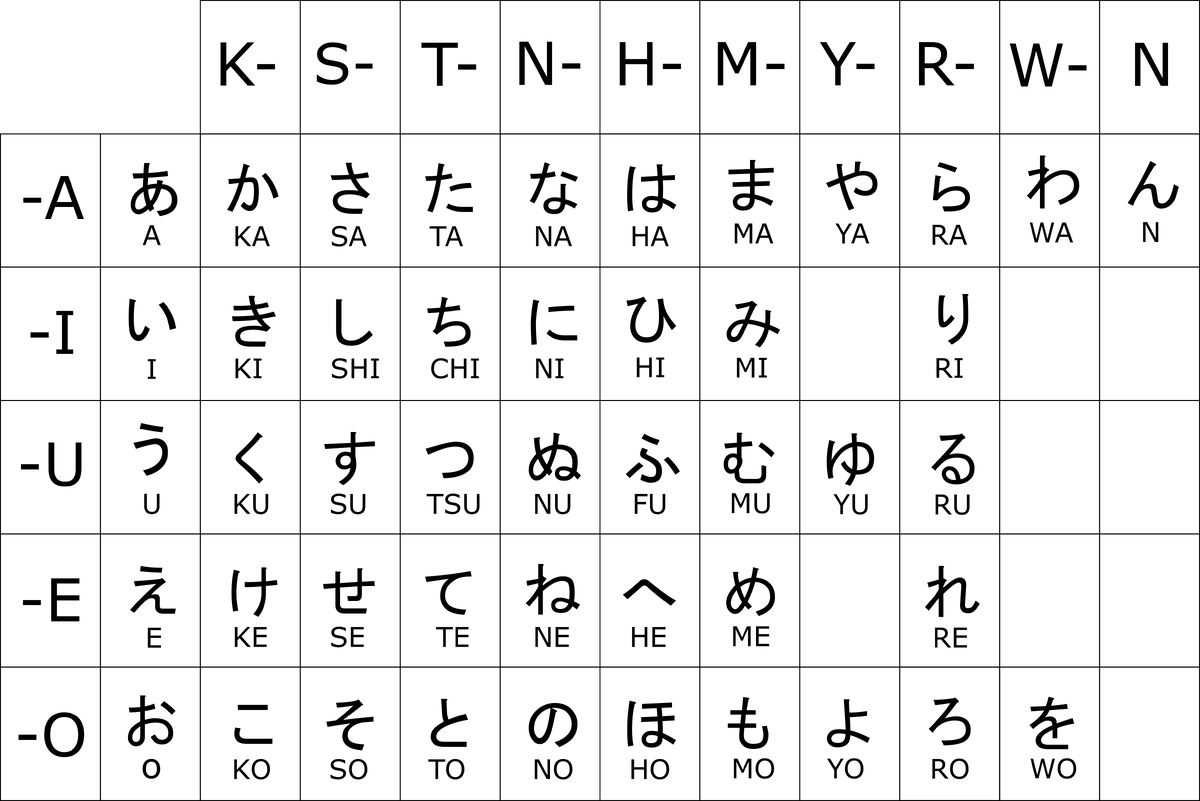
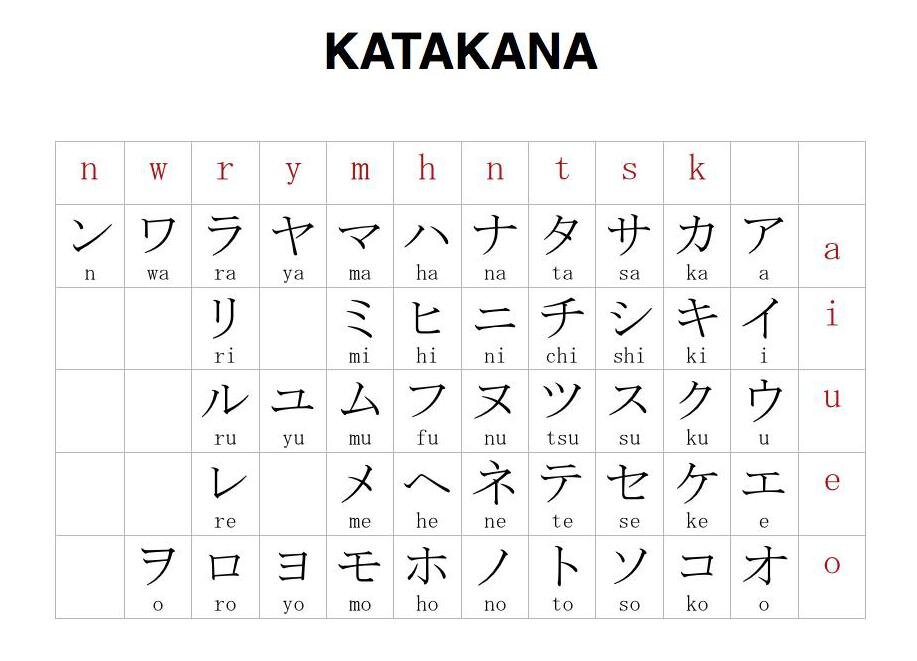
Азбуки, хирагана и катакана (объединенные термином "кана"), дублируют друг друга. Ими записывают всякие частицы, окончания и служебные слова, иногда фонетически какие-то слова, иногда иностранные имена и всё в таком роде. Символы хираганы такие круглые, а символы катаканы немного угловатые.
Кандзи мы вводить (в консоли) не можем, для ромадзи ничего особенного не надо, а вот кану вводить можно. И даже есть два способа.
Во-первых, хирагана и катакана есть в стандартном наборе диграфов Вим. Смотрите справку :help digraph или саму таблицу (:digraphs). В основном, там все интуитивно: диграф ka введет か, диграф Ka — カ, o5 введет お, а o6 (о шесть) — ォ. Символы 5 и 6 соответствуют хиракане и катакане, так же, как * — греческому, + — арабскому и ивриту, = — кириллице.
Есть там, в стандартных диграфах, и тайваньская система бопомофо — значки для звуков китайского языка на базе иероглифов (как и обе каны), но не слоговая, а ближе к алфавитной. Для нее используем символ 4.
Второй способ — это раскладка kana. Можете с ней ознакомиться или включить — аналогично китайской, см. выше. Раскладка определяет по три таблицы символов для каждой каны. Базовых символов около 50; так много потому, что азбуки слоговые. Для каждого слога японского языка свой символ. Но есть еще значок озвончения, и он не просто рядом пишется — он часть символа, так что формально уже вдвое больше.
Первая таблица, которую рекомендовано использовать для звуков японского языка, содержит 102 символа.
Вторая таблица добавляет еще 22 символа, например を (wo).
Третья таблица добавляет еще 101 символ, которые надо использовать, если первых двух таблиц не хватило. Например, там уменьшенные символы вроде ゎ, исторические вроде ゐ (wi) и составные (っか).
Для катаканы всё аналогично, только диграфы надо вводить заглавными.
Корейский язык использует полнофункциональный алфавит хангыль, в котором символы слога комбинируются в двухэтажные структуры. Все они в юникоде есть (их более 11 тысяч), но все они состоят из 40 базовых.
Имеется раскладка hangul, только надо делать паузы, позволяя Виму свернуть символ. Если вы введете буквы с паузой, получите две базовые буквы, а если быстро — то знак слога. С другой стороны, если не сделать паузу после слога, то можно получить другой слог. ПОД вместо ПО, например. Раскладка не фонетическая, а соответствует южнокорейской стандартной клавиатуре.
Корейцы тоже когда-то заимствовали иероглифы, но потом отказались от них. Северная Корея отказалась сразу, а в Южной и сейчас может встретиться иероглиф как сокращение, но редко.
В Монголии используют кириллицу, но раскладка отличается от русской. В Виме есть: mongolian_utf-8.
Про иврит я подробно рассказывал; в раскладке есть всё, включая огласовки.
Про арабский тоже был материал. В Иране тоже используют арабскую вязь, но есть отличия; для персидского есть раскладка: persian.
Неожиданно мощно представлена Шри-Ланка: две раскладки для сингальского, традиционная и фонетическая, и одна для тамильского. Выглядят буквы как магические рисунки, офигенно круто: ඍ , например.
Для тамильского нужен шрифт, в файле раскладки есть ссылка. Странно, потому что в юникоде все эти символы есть. Видимо, дело в том, что это TSCII, аналог нашего ASCII, не-юникодная раскладка.
Деванагари отсутствует. Вообще непонятно, почему!
А вот письменность Тана (thaana) Мальдивских островов есть: thaana-phonetic_utf-8 или просто thaana.
Для турецкого языка (если вы не в курсе, то уже лет сто турки пишут латиницей) есть две раскладки: turkish-f и turkish-q. Вторая — это та же QWERTY, а первая — что-то вроде Дворака.
Есть еще два старотурецких алфавита, orkhon и enisei, у меня этих символов в шрифтах нет и я про них ничего не знаю.
Вьетнамцы тоже пишут латиницей, но она немного странная: буквы обвешаны таким множеством значков, что не сразу и опознаешь. Вим предлагает три раскладки: vietnamese-telex_utf-8, vietnamese-viqr_utf-8 и vietnamese-vni_utf-8.
И всё это у вас есть вот прямо из коробки! Если вы занимаетесь каким-то из этих языков, то имеете возможность на этом языке набирать тексты без всяких проблем.
И это прекрасно, я считаю.