Всем привет. Это подготовительная статья перед написанием парсера, в этой статье говорится что такое парсер, что он делает, обсуждаются и пишутся необходимые компоненты перед написанием парсера.
Парсер - это Часть программы, преобразующей входные данные в некий структурированный формат, нужный для задач последующего их анализа и использования. Технически, парсер выполняет синтаксический анализ данных.
Наш парсер будет преобразовать поток токенов, который нам выдаст лексер, в Abstract Syntax Tree ( AST ). Также парсер должен проверять поток токенов на ошибки.
AST - это конечное помеченное ориентированное дерево, в котором внутренние вершины сопоставлены (помечены) с операторами языка программирования, а листья — с соответствующими операндами. Таким образом, листья являются пустыми операторами и представляют только переменные и константы.
Вот изображение AST:
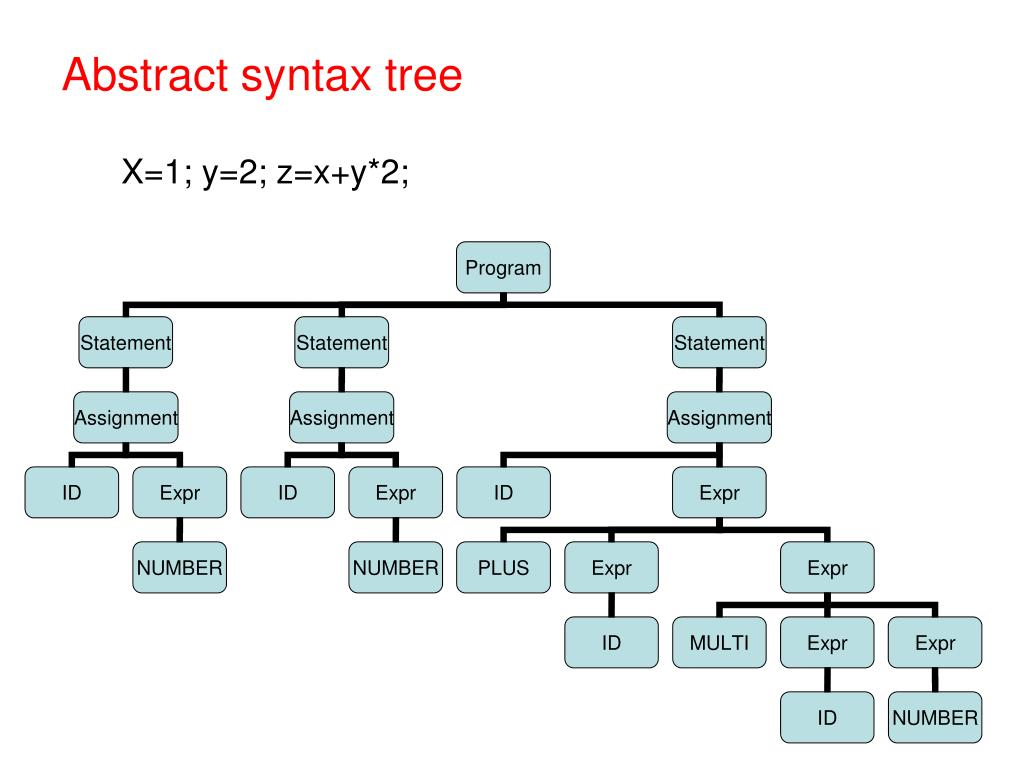
И тут встает вопрос а как сделать такой алгоритм который сможет сгенерировать дерево из полученных токенов и еще проверить ошибки.
Алгоритмов есть много, но мы соберем свой велосипед.
Для начала нужно сделать необходимые вещи для парсера, а это точная грамматика конструкций языка, система ошибок кода, и AST.
Давайте я вам покажу какая будет точная грамматика у конструкций языка:

Данное фото сверху означает что у узла if будут узлы потомки arguments и statement. Не трудно догадаться что в arguments будут аргументы, а в statement сам код который должен выполнится если будет верно условие.
Также это относится и к другим конструкциям. Также потомков у аргументов и statement может и не быть.
Но внимательный читатель может сказать: Но куда делись математические конструкции типа (i = 5; i++ + i++;), которым тоже нужна грамматика ?
Но я ему отвечу вот что, со всеми этими операциями уже можно работать локально, то есть для них отдельно написать маленькую сводку грамматики, может быть даже придется сделать отдельный маленький парсер (под математику уж точно).
А теперь давайте приступим к коду.
Давайте подправим класс Node. В него нужно добавить:
private Node parent;
public Node Parent
{
get
{
return parent;
}
}
И в функцию AddChild нужно добавить:
node.parent = this;
Теперь нужно поговорить о системе ошибок.
Для начала создадим файл и напишем в нем перечисление ErrorEnum, оно будет вот таким:
enum ErrorEnum
{
no_find_programm_error,
unavaible_name_programm_error
}
Данное перечисление служит для типов ошибок, и оно будет пополнятся с ростом языка.
Затем еще создадим файл, в котором будет класс Error. Он будет вот таким:
class Error
{
private ErrorEnum typeError;
private string stringValueError;
public ErrorEnum TypeError
{
get
{
return typeError;
}
}
public string ValueError
{
get
{
return stringValueError;
}
}
public Error(ErrorEnum typeErr, string val)
{
typeError = typeErr;
stringValueError = val;
}
}
Данный класс служит для того что хранить в себе тип ошибки и строковое значение которое уже может спокойно понять человек.
Теперь нужно еще создать файл, в котором будет SystemParserError. Также нужно подключить пространство имен System.Collections.Generic для списка ошибок. Вот таким будет класс.
class SystemParserError
{
private List<Error> errors;
public IEnumerable<Error> Errors
{
get
{
return errors;
}
}
public int CountErrors
{
get
{
return errors.Count;
}
}
public SystemParserError()
{
errors = new List<Error>();
}
public void Error_c(ErrorEnum typeError, string valueError)
{
errors.Add( new Error(typeError, valueError) );
}
}
Данный класс инкапсулирует список ошибок и позволяет очень легко добавить туда ошибку.
Теперь нужно сделать класс AST. А он будет очень простым. Опять же создадим файл и напишем там класс AST а он будет таким будет:
public class AST
{
private Node nodeAST;
public Node NodeAST
{
get
{
return nodeAST;
}
}
public AST(string nameProgramm)
{
nodeAST = new Node(Token.var_t, "AST");
}
}
Ну на этом все в следующей статье, а может быть и в статьях мы будем писать уже парсер.