Обзор метода LoRA: плюсы и минусы
Введение
Адаптация больших языковых моделей (LLM) под конкретные задачи требует огромных вычислительных ресурсов. Полное дообучение (full fine-tuning) — это дорого, долго и не всегда необходимо. Поэтому появляются параметро-эффективные методы обучения (Parameter-Efficient Fine-Tuning, PEFT), такие как LoRA (Low-Rank Adaptation).
LoRA позволяет обучать только небольшое количество параметров, оставляя базовую модель неизменной. Это значительно снижает требования к памяти и ускоряет обучение.
В этой статье разберем:
✅ Как работает LoRA?
✅ Какие у него плюсы и минусы?
✅ Чем LoRA отличается от других методов адаптации?
✅ Примеры кода для использования LoRA в LLM.
1. Как работает LoRA?
Проблема стандартного fine-tuning
Полное дообучение изменяет все параметры модели, что требует:
🔹 Много памяти (VRAM / RAM) – для хранения и обновления всех весов.
🔹 Больших вычислительных ресурсов – для обучения всех параметров.
🔹 Долгого времени обучения – миллиарды параметров обновляются на каждой итерации.
Идея LoRA
LoRA предлагает изменять не всю модель, а только небольшие дополнительные матрицы (ранговые адаптации).
📌 Как это работает?
- Вместо обновления всей матрицы весов W (размером d × k)
- LoRA добавляет две маленькие матрицы A (d × r) и B (r × k)
- Итоговое обновление: W' = W + A * B
🔹 W остается неизменной – LoRA просто добавляет небольшие корректировки!
🔹 Количество обучаемых параметров уменьшается в 1000 раз.
📌 Пример использования LoRA в PyTorch

🔹 В этом коде добавляется ранговая адаптация вместо полной замены параметров.
2. Плюсы и минусы LoRA
Преимущества LoRA
✅ Экономия памяти (VRAM, RAM)
- LoRA требует в 10–100 раз меньше памяти, чем полный fine-tuning.
- Модель не дублируется, а просто получает корректировки.
✅ Скорость обучения
- В 3–5 раз быстрее, чем full fine-tuning.
- Не нужно хранить градиенты всех параметров модели.
✅ Уменьшенные вычислительные затраты
- Можно обучать даже на потребительских GPU (8–16GB VRAM).
- Позволяет fine-tuning без использования многокарточных систем.
✅ Универсальность
- LoRA совместим с различными LLM (Llama, GPT, Falcon, T5).
- Легко интегрируется в Hugging Face Transformers.
✅ Отсутствие катастрофического забывания
- Базовая модель не изменяется – сохраняет старые знания.
Минусы LoRA
❌ Ограниченная адаптация
- LoRA не подходит для сильного изменения поведения модели.
- Например, для перевода модели с английского на китайский лучше использовать полный fine-tuning.
❌ Требует интеграции в архитектуру модели
- LoRA не работает "из коробки" для всех моделей.
- Необходимо изменять определенные слои (Q, V в трансформере).
❌ Может ухудшать качество на сложных задачах
- Иногда LoRA не дает такого же качества, как полный fine-tuning.
- Это особенно заметно на задачах, где требуется глубокая перестройка модели.
3. Как использовать LoRA в Hugging Face Transformers?
LoRA легко интегрируется в Hugging Face PEFT (Parameter-Efficient Fine-Tuning).
📌 Пример использования LoRA с Llama-2:
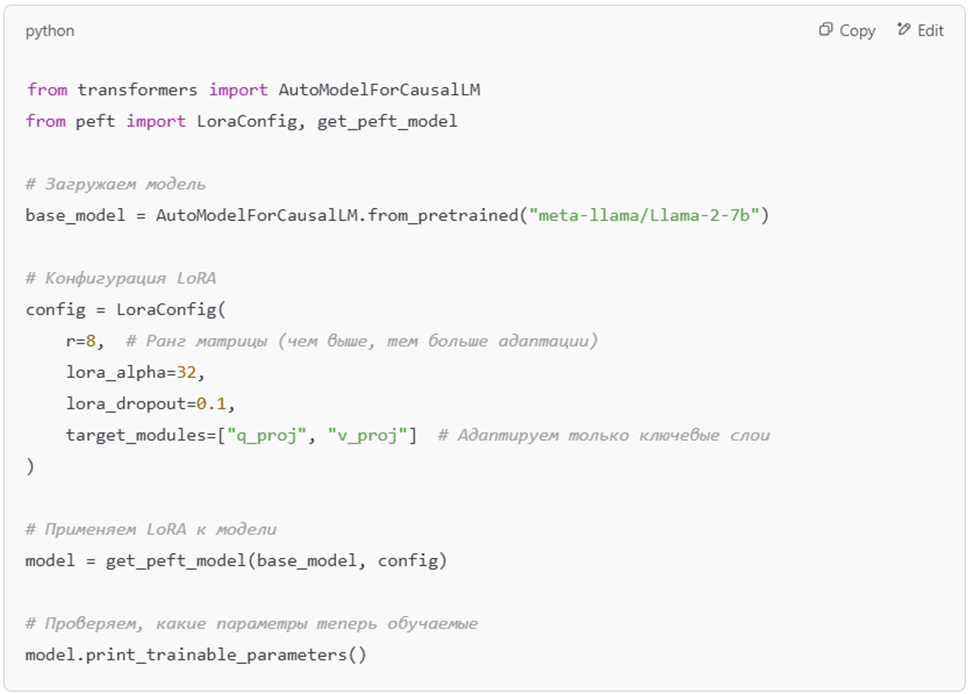
🔹 Теперь обучаем только 0.1% параметров вместо 100%!
🔹 Модель адаптируется без потери старых знаний.
4. LoRA vs другие методы адаптации
LoRA vs Prompt Engineering
🔹 Prompt Engineering – подходит для простых изменений (например, изменение стиля ответа).
🔹 LoRA – для более сложных адаптаций без дообучения всей модели.
LoRA vs Adapter Layers
🔹Adapter Layers позволяют лучше кастомизировать модель, но требуют больше вычислений, чем LoRA.
Выводы
🚀 LoRA – мощный инструмент для адаптации LLM без огромных затрат!
✅ Снижает потребление памяти и ускоряет обучение.
✅ Подходит для применения на обычных GPU.
✅ Хорошо адаптирует LLM под специфические задачи.
🔹 Когда использовать LoRA?
✔ Для задач, где важна эффективность и экономия ресурсов.
✔ При адаптации моделей без потери оригинальных знаний.
✔ Когда полное дообучение слишком дорого.
🔹 Когда LoRA не подходит?
❌ Когда требуется полностью изменить поведение модели.
❌ Если задача требует очень высокой точности.
🎯 LoRA – это баланс между адаптацией и эффективностью!
Больше статей, глубоко раскрывающих тонкости обучения больших языковых моделей (LLM) на специализированных датасетах и их кастомизации под конкретные задачи, читайте на нашем канале по следующим ссылкам:
Как бороться с проблемами смещения (bias) и недостаточного объема данных- https://dzen.ru/a/Z6o5NsAFhAdFoxfp
Выбор и подготовка специализированного датасета для обучения LLM: методы сбора, разметки и очистки данных- https://dzen.ru/a/Z6o6ElSRfBqKJ6IW
Выбор и подготовка специализированного датасета для обучения LLM- https://dzen.ru/a/Z6o4oGfDPh4V9OG0
Примеры кастомизации LLM под разные задачи: медицина, финансы, юридическая сфера и др.- https://dzen.ru/a/Z6o325PpvHkGw-8T
Что такое дообучение LLM и чем оно отличается от обучения с нуля- https://dzen.ru/a/Z6o299L6LFgFT0iJ
Обзор типов кастомизации LLM: дообучение, адаптация с LoRA, инжиниринг промптов- https://dzen.ru/a/Z6o2N6yfbxrS_Nck
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
Почему стоит выбрать нас:
- Индивидуальный подход: мы создаем решения, адаптированные под уникальный дизайн вашего бизнеса.
- Высокое качество: наши разработки обеспечивают точность и надежность работы.
- Инновационные технологии: использовать передовые технологии и методы, чтобы предложить вам лучшее из мира ИИ.
- Экономия времени и ресурсов: автоматизация процессов и внедрение умных решений помогают снизить затраты и повысить производительность.
- Профессиональная поддержка: Наша команда экспертов всегда готова обеспечить качественную поддержку и консультации на всех этапах проекта.
В использовании искусственного интеллекта уже сегодня — будущее для вас!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru