Как открывать матрицу и запускать branch-and-bound в TNT я написала в предыдущей статье. Пожалуйста, прочитайте ее, прежде чем приступать к материалу в этой статье. Несмотря на то, что в branch-and-bound находятся все самые экономные деревья, и при небольших матрицах лучше использовать его, в матрицах с более чем 30 таксонами, TNT начинает виснуть. В большинстве случаев придется применять эвристические алгоритмы.
Набор данных взят из моей статьи Namyatova & Cassis (2013).
Тут я рассмотрю, как их запускать. В главном меню надо опять выбрать Analyze, и теперь давайте посмотрим, что скрывается за заголовком "Traditional search".
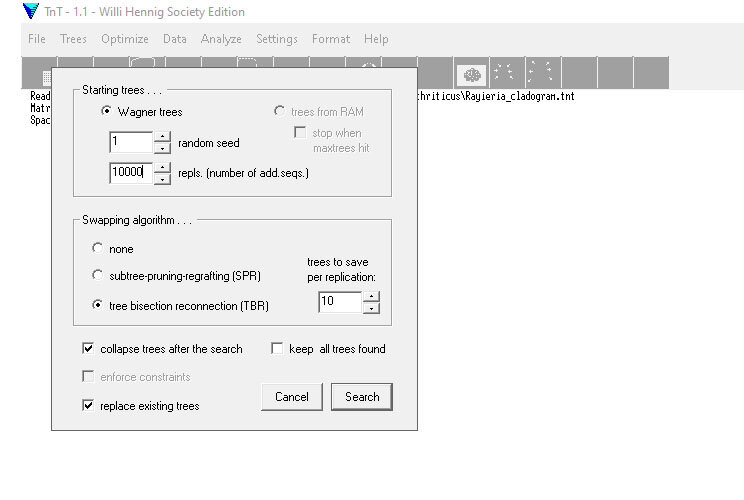
Появляется окно с настройками. Наверху у нас стоит галка на Wagner trees. Что это такое, я уже объясняла в другой раз. Тут можно выбрать, начинать ли анализ с Вагнеровского дерева, или с дерева, которое сохранено с предыдущего анализа. Поскольку у нас не было никакого анализа, то и выбора тоже нет.
Следующее - это random seed. Это случайный номер, который создает последовательность присоединения ветвей в Вагнеровском дереве. Если вы запускаете анализ более одного раза, то рекомендуется менять это число случайным образом. Иначе анализ будет каждый раз запускаться с того же самого вагнеровского дерева, что приведет к похожим результатам. Сейчас я запускаю анализ первый раз, поэтому могу оставить на 1.
Далее предлагается установить количество репликаций. То есть сколько раз будет построено вагнеровское дерево и последующий обмен ветвей на нем. Кто-то считает, что 1000 достаточно, но для финального варианта обычно ставят 10000. Если большая матрица, и вам хочется быстро посмотреть на предварительные результаты, то можно запускать на 1000. Обычно результаты 1000 и 10000 репликаций отличаются только поддержками.
Потом предлагается выбрать алгоритм обмена ветвями. Считается, что TBR получше, поэтому оставим его. И также можно выбрать, сколько сохранять лучших деревьев после каждой репликации. По умолчанию - 10, я обычно так и оставляю.
Опять предлагается collapse tree after the search, то есть схлопнуть ветви, которые не поддержаны признаками хотя бы для одной оптимизации. Я установила здесь галку, потому что я считаю, что такой результат более достоверный. Вы можете также сохранить все найденные деревья, возможно, это нужно будет для последующих анализов. Ну и если у вас до этого уже был анализ и деревья сохранены в памяти, нужно обязательно поставить галку в месте "replace existing trees". После этого можно нажать Ok.

Появится такое окно, которое показывает прогресс анализа. Вначале номер репликации или повтора (4142), алгоритм (TBR), длину текущего дерева (146), длину лучшего дерева (144), ну и время анализа.
Далее программа выдает результат.
У нас опять получилось одно дерево с длиной 144.
Оно точно такое же, что и дерево, получившееся при применении алгоритма branch-and-bound.
Чтобы выйти из формата просмотра дерева, надо опять в главном меню выбрать Trees и убрать галку с View.
Теперь посмотрим, что такое New Technology Search. Для этого в главном меню опять надо выбрать Analyze и нажать на New Technology Search. Откроется окно с еще более сложными настройками. И, честно, признаюсь, что не знаю лично ни одного человека, который бы понимал их все.
Слева все возможные алгоритмы, я про них рассказала в статье по этой ссылке. Вы можете выбрать что-то одно, несколько или все. Ratсhet считается самым лучшим из них. Для каждого алгоритма есть свои настройки. Если используете Ratchet, то лучше увеличить количество репликаций. По умолчанию их 10, можно поставить на 1000 или 10000. Я выберу все алгоритмы, и в Ratchet поставлю 10000 репликаций.
Справа предлагается выбрать алгоритм, который ищет субоптимальное дерево, которое используется уже как основа для четырех алгоритмов слева. В Goloboff et al. (2008) написано, что Driven search и Random addition sequences строят субоптимальное дерево с нуля, только первый более умный. Ну и если у вас уже есть какие-то деревья в памяти, то можно использовать их (RAM). Я выберу Driven search и увеличу Init. addseq до 20. Это сколько раз будет строиться субоптимальное дерево, которое потом будет использоваться для всех анализов, которые вы отметили галками.
Опять можно изменить Randon Seed и схлопнуть неподдержанные хотя бы при одной оптимизации ветви. Я это тоже выберу. Что такое Auto-constrain я так и не поняла. Вероятно, можно оставить по умолчанию.
Если нажать на Search, то появится вот такое окно с прогрессом поиска.
Replication соответствует Init. addseq, то есть 20 в этом случае. В итоге получилось тоже самое дерево, что и при предыдущих двух анализах.
Какой алгоритм использовать? В TNT я обычно использую Traditional search, просто потому что его настройки для меня более понятные, и легче объяснит свой выбор в статье.
Когда-то я пыталась использовать New Technology search, но мне смутило то, что на некоторых матрицах после него получается другое дерево, не такое, как в Traditional Search в TNT и в Ratchet в Winclada. Поскольку настройки там не очень понятные и вообще-то эти алгоритмы, особенно Ratchet, созданы для очень больших матриц в несколько сотен таксонов (Nixon 1999), которых у меня обычно не бывает, то я решила просто в TNT его не использовать. Однако знаю людей, которые используют его и часто, хотя толком тоже не могут объяснить мне, как они выбирают настройки и по сути просто оставляют все по умолчанию.
Однако, в этот раз я запустила на одном и том же наборе данных три разных анализа, и каждый раз получился один и тот же результат. Кстати, обратите внимание, что TNT укореняет по умолчанию на первый таксон в матрице.
Что я посоветую начинающим?
1) Если матрица небольшая, до 30 таксонов, то использовать implicit enumiration.
2) Если матрица больше, то обязательно посчитать ее с помощью Traditional search при 10000 итераций.
3) Также можете использовать New Technology Search (с настройками, которые вы решите наилучшими для себя, изучив матчасть), но обязательно сравнить результаты с Traditional Search. Если они совпадают, то все ок. Для более точного результата, запустить анализы несколько раз при разных random seed.
4) Запустить также дерево в Nona (Winclada) и сравнить результаты. Об этом в следующей статье.
В этот раз у нас получилось всего одно дерево. Однако обычно их больше. Как с ними работать и сохранять в TNT, я тоже расскажу в последующих статьях.
Goloboff, P. A., Farris, J. S., & Nixon, K. C. (2008). TNT, a free program for phylogenetic analysis. Cladistics, 24(5), 774-786.
Namyatova, A. A., & Cassis, G. (2013). Systematics, phylogeny and host associations of the Australian endemic monaloniine genus Rayieria Odhiambo (Insecta: Heteroptera: Miridae: Bryocorinae). Invertebrate Systematics, 27(6), 689-726.
Nixon, K. C. (1999). The parsimony ratchet, a new method for rapid parsimony analysis. Cladistics, 15(4), 407-414.