Пару месяцев назад начал обучение нового сотрудника. Человеку сильно захотелось в программирование, пообщались, у него есть талант к обучению и получается запоминать алгоритмические трюки, а главное упорство. Только пока он еще уверен в том, что вот еще немного поучиться и станет супер-специалистом, который деньги лопатой гребет. А когда при очередном созвоне, оказывается, что ему нужно прочитать пару десятков страниц документации, чтобы овладеть нужной техникой, то сразу начинает нудеть – "Это мне что, опять целый день читать и запоминать? А работать когда?"
Слушаю его и так не хочется его разочаровывать. Я программирую уже 17 лет и читать документацию, а также книги мне приходится регулярно по нескольку часов в неделю. Такова природа программирования, компьютерных наук, да и скорей всего любого интеллектуального труда. Ты всегда будешь догонять этот локомотив технологий. Каждый день выходят новые фреймворки, удобные сервисы и полезные рецепты. За всем этим не уследишь, остается только довольствоваться мелкими крохами, которые успеваешь впитать между дедлайнами, бессонными ночами, а еще же жить нужно успевать.
Бывают вещи, на изучение, которых нужно несколько часов. Например, технология SASS для удобной работы со стилями CSS. Конечно, при условии, что вы знаете, что такое CSS.
Но иногда на постижение больших технологий, требуется очень много времени. Сначала ты слышишь про них на какой-нибудь конференции и не придаешь ей значения. Затем знакомые используют эти слова, потом где-то в видео. Наконец, после первых попыток освоения, выясняется, что эта технология основана на чем-то другом, что тебе опять нужно понять.
Такое у меня было и с Kubernetes.
Начнем издалека.
Как думаете в чем успех Google? Почему они смогли как ракета взлететь, поглотить невероятное количество мелких стартапов, умело переварить их и встроить в собственный бизнес?
Конечно, это технологическое превосходство, отличный маркетинг и умение учиться - быстро и тому, что нужно в данный момент.
Одна из ключевых технологий, благодаря, которой они смогли вырасти до мировой корпорации – это технология масштабирования серверных мощностей. Ни один, даже самый мощный компьютер не способен обработать миллиарды запросов в секунду, которые сыплются от пользователей и различных вспомогательных программ. Где-то я читал, что для выдачи результата по одному поисковому запросу требуется энергии столько, что можно чайник вскипятить.
В 2014 году Google открыла доступ к этой супер-технологии для всех – Kubernetes. Причем совершенно бесплатно, любая компания может, используя неограниченное количество серверов наращивать мощности, доступные им для вычислений.
- Зачем, это же породит множество конкурентов? – возразите вы. Но у Google свои соображения на этот счет. Так же, как и многие другие открытые исходники, например Android. Потому что они понимают ключевую идею – если поделиться полезным решением, то взамен они получают еще больше пользы. Они неплохо на этом зарабатывают. Предоставляют серверные мощности в аренду. Примерно, как Amazon, начинали как книжный магазин, а теперь крупнейшая облачная платформа. Масштабируйтесь, пожалуйста, вот вам наши сервера, только платите и все будет в шоколаде.
Но что-то я отвлекся, я хотел вам рассказать, что сейчас активно изучаю технологию микросервисов, которые можно запускать внутри Kubernetes. Ага, чтобы быстро масштабироваться и суметь вырастить свой сервис до мировых масштабов.
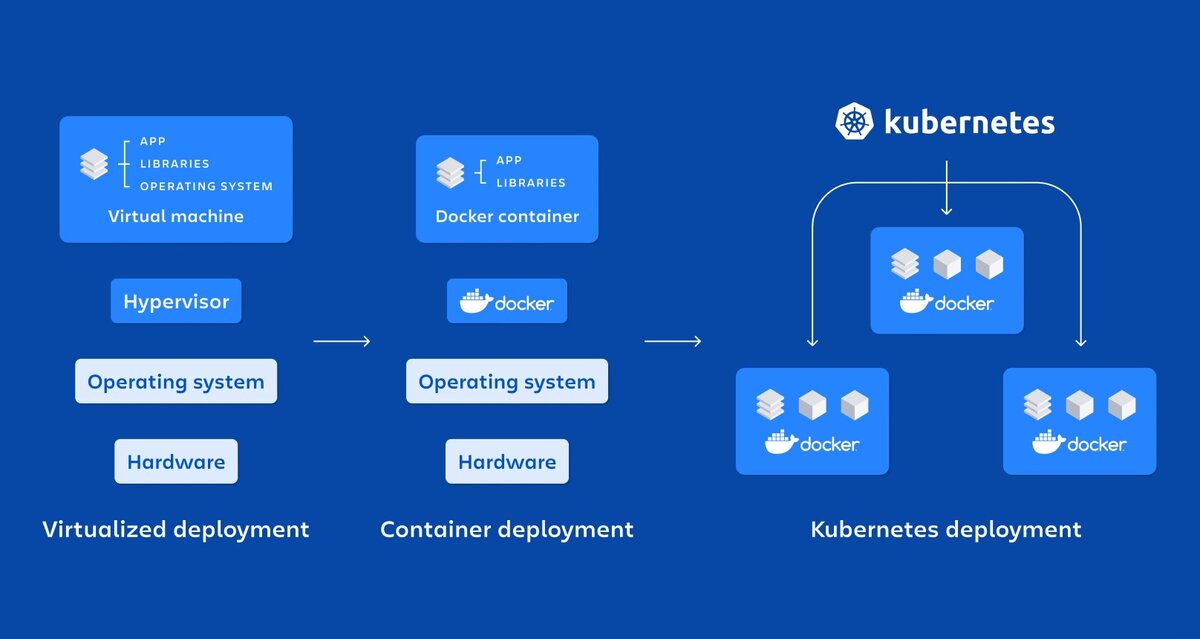
Для этого потребовалось сначала изучить Docker – это технология контейнеризации приложений. Еще одно чудо, на освоение, которого у меня ушло много времени. Если раньше, чтобы на одном сервере работало программное решение, нужно было основательно потрудиться в настройке окружения, вспомогательных библиотек, зависимостей. При этом, часто все эти подготовительные процедуры ломали зависимости других сервисов на этом же сервере. Одному нужен Python 2, а другому Python 3.
Настоящая революция свершилась, когда появилась технология изолирования среды выполнения. С помощью Docker мы можем создать контейнер, который будет обладать своим уникальным набором инструментов, запускать этот контейнер на сервере и самое важно, серверу совершенно не важно, что происходит в этом контейнере. Он полностью защищен от происходящего внутри него. И таких контейнеров можно запускать сколько угодно много, никаких конфликтов.
Выстраивать микросервисы и связывать их – это все равно, что строить фабрику. Где каждый участок отвечает за какую-то свою узкую задачу. Тут мы собираем данные. Затем отправляем их в хранилище. Следующий блок берет эти данные и дополняет их недостающими деталями. Потом реализуем блок, который извлекает эти данные и преобразует их в формат понятный другому модулю. Самое замечательное, все эти кирпичики можно добавлять сколько угодно много. При этом каждый кирпичик совсем не заботиться о том, для чего он все это делает. Ему важно выполнять свою задачу.
Благодаря конейнерам, я не ограничен в выборе технологий. Одно приложение может работать на PHP, другое на Python, а третье на NodeJS. И все это прекрасно умещается на одном сервере, а если потребуется масштабирование, то просто добавляется еще один сервер, вуаля и все это может обрабатывать теперь в два раза больше запросов, нисколько не замедляя своей работы.
И еще одно гигантское преимущество такого изолированного выполнения – это то, что теперь контейнеру тоже не нужно заботиться о том, на каком сервере он выполняется. Ему только мощности процессора подавай, оперативку и место для хранения файлов. Тут и подключается технология Kubernetes. Она способна один контейнер копировать на несколько узлов. Если вдруг один сервер сломается, то все запросы пойдут к другому рабочему серверу. Как Змей-Горыныч, на место отрубленной головы тут же вырастает новая.
Если сегодня у нас десять человек на сайте, а завтра миллион, из-за очень удачной вирусной рекламы, то мы просто поменяем цифру доступных репликаций сервиса с 2 на 100 и все работает отлично, без сбоев и простоев. Потому что теперь наш сайт одновременно работает на 100 серверах.
Вывод
Может кто-то помнит времена, когда файлы качались по модему и на пару дискет в 3 мегабайта можно было потратить бессонную ночь, со всеми этими обрывами и пиликаниями. Тогда никто даже не мечтал о том, чтобы легко перегонять гигабайты информации за несколько минут. Ускорение и увеличение мощностей неизбежно влечет за собой сложность технологий и объемы знаний, которыми нужно овладеть специалисту. Только для того, чтобы знать какую кнопку нажать. При этом пределов этому совершенно не видно, поэтому в будущем людям придется учиться еще больше.
Подозреваю, что нейроинтерфейсы это единственный вариант (пока еще фантастический, также как звучало фантастическим перекачка гигабайта за минуту). Но я не знаю, какие еще варианты изучения всей этой технической информации возможны.



















