Лямбда выражения, потоки, std::async и параллельные алгоритмы в C++
Содержание:
- Лямбда и std::thread
- Лямбда и std::async
- Лямбда и параллельные алгоритмы в C++17
- Захват this
- Заключение
В статье о лямбда выражениях (в одной из тех, что была на прошлой неделе), легко продемонстрировать пример, когда лямбда работает внутри потока (текущего). Но как быть со случаями, когда необходима асинхронность исполнения? С какими проблемами вы можете здесь столкнуться, чтобы узнать читайте статью.
Лямбда и std::thread
Начнем с std::thread. Наверно вы уже знает, что std::thread принимает вызываемый объект (callable object) в качестве аргумента конструктора. Это может быть обычный указатель на функцию, функтор или лямбда выражение. Простой пример:
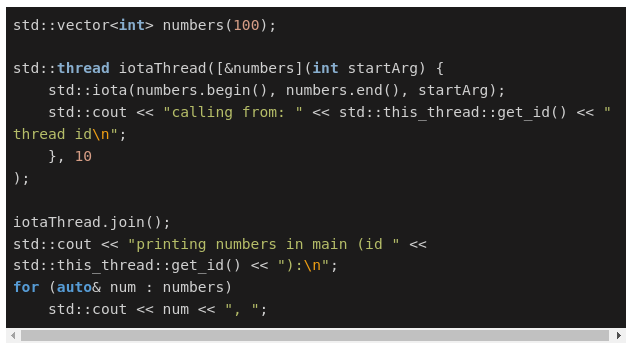
Мы создаем один поток с лямбда выражением. std::thread это класс, имеющийгибкий конструктор, в который мы можем даже передать значение для аргумента.В нашем коде 10 - это значение, передаваемое в лямбда выражении, как startArg.
Этот код простой, потому что мы можем управлять исполнением потока и присоединиться к нему, также мы знаем, что как только мы увидим напечатанный текст, результат std::iota будет готов. Важно помнить, что лямбда выражения позволяют с легкостью и удобством создавать потоки, но наша цель асинхронное выполнение потоков. А это значит, что все проблемы, связанные с передачей обычных функций, будут здесь. Взгляните на следующий пример:
Мы создаем пять потоков и каждый поток выполняет супер продвинутые вычисления, используя доступную всем потокам переменную counter. Вы можете надеяться, что все пять значений counter будут равны 500, но увы, результат будет не определен. После непродолжительных тестов в Visual Studio 2019 были получены следующие результаты (результаты разных запусков):
Решить данную проблему, обычно встречающуюся при работе с многопоточностью, мы можем воспользовавшись одним из механизмом синхронизации. В примере, мы используем atomic (см concurrency support library из STL), как наиболее быстрый и легкий в использовании способ решить данную проблему.
Код выше из примера работает, как и ожидалось, операция инкремента сейчас атомарна (не рассинхронизирована при выполнении). Это значит, что counter инкрементируется, и другие потоки не могут нарушить это действие. Если мы не будем никак синхронизировать потоки, то они смогут читать текущее значение counter в один момент времени и затем изменять его (инкрементировать), что заканчивается неопределенным поведением. Синхронизация потоков делает код безопасным, но приходится платить цену в виде производительности. Но это тема другой статьи и долгих дискуссий. Как мы можем видеть, создавать потоки из лямбда выражений удобно. It’s local to your executing thread (Рядом с вашим потоком исполнения) и вы можете работать с ним (лямбда выражением) так же как с обычной функцией или с функтатором (functor object).
И сейчас вопрос для Вас: вы используете лямбда выражения для создания потоков?
Частенько код потока более запутанный, чем три или пять строчек лямбда выражения. Может быть в этом случае лучше написать внешнюю функцию для потока? Что вы думаете? Какие у вас правила на этот случай?
Теперь попробуем другой подход для решения данной проблемы, что доступен в C++.
Лямбда и std::async
Второй путь, который вы можете использовать в многопоточности, идет через std::async. Мы получили в распоряжение эту функциональность вместе с потоками в C++11. Это высокоуровневое API, которое позволяет вам установить и вызвать вычисления с полной или отложенной(lazy evaluation) асинхронностью.
Взглянем на измененный пример с iota в стиле async:
На этот раз, вместо потоков, мы полагаемся на механизм std::future. Это объект, который управляет синхронизацией и гарантирует, что результат вызова будет готов.
В нашем случае мы запланировали выполнение лямбда выражения через std::async, затем необходимо вызвать .get() для завершения вычислений, так как get() является функцией блокировки.
Однако код выше немного жульничает в том, что использует future<void> и vector захватываемый, как ссылка в лямбда выражении . Как альтернативу вы можете создать std::future<std::vector<int>>:
Здесь стоит остановиться.
Код выше будет работать, но std::async/std:future за годы существования заработали смешанную репутацию. Он выглядит как рабочий, но не стоит делать поспешных выводов, так как данный подход будет работать только в простых случаях, но с более сложными сценариями начинаются проблемы, такие как:
- расширяемость
- слияние задач
- невозможность отмены/присоединения
- это не простой тип
- и множество других вопросов
Я не использую этот фреймворк в реальных проектах, не буду притворятся, я здесь не эксперт. Если вы хотите узнать больше по данной теме, прочтите или посмотрите следующие ресурсы:
Лямбда и параллельные алгоритмы из C++17
После обсуждения поддержки потоков в C++11, мы можем переместиться к другому стандарту: C++17. На 2020 г. вы имеете супер легкую в использовании технику, что позволяет вам распараллеливать большинство алгоритмов из стандартной библиотеки. Все что вам нужно сделать, это передать специальный первый аргумент в алгоритм, для примера:
Мы имеет следующие параметры:
Для примера, мы можем распараллелить поиск четных чисел и скопировать их с помощью фильтра (код плохой и подозрительный):
Вы заметили, что тут есть проблемы?
Мы можем исправить проблему синхронизации с помощью мьютексов и блокировок после каждого push_back. Но код будет после этого эффективным? Если фильтр - это простой и быстро исполняемый код, то в результате вы можете получить куда меньшую производительность, чем версия параллельного выполнения.
Не говоря уже о том факте, что при параллельном выполнении вы не знаете, в каком порядке элементы будут копироваться в vector<int> output.
Параллельные алгоритмы относительно легки в использовании, просто передайте первый аргументы и вы получите рост скорости... но легко забыть, что вам еще нужно работать с параллельным кодом, учитывая все меры предосторожности.
Захват this
Перед тем как мы закончим, хотелось бы обратить внимание на важную деталь: как правильно захватить указатель this.
Давайте взглянем на следующий код:
Как вы думаете, что случится когда мы попробуем вызвать nameCallback()?
*барабанная дробь*
Неопределенное поведение!!!
Для примера, в моем отладчике в Visual Studio, получилось вот такое исключение.
прим. ред. - так как блог посящен Linux/Unix то привожу пример результата работы кода на LinuxMint скомпилированного g++ 9.4.0
terminate called after throwing an instance of 'std::logic_error'
what(): basic_string::_M_construct null not valid
Это происходит, потому что в nameCallback мы пытаемся получить доступ к члену структуры User. Однако объект данного типа был удален, когда мы вызвали pJohn.reset(), а затем мы попробовали получить доступ к удаленному участку памяти.
В этом случае, мы можем исправить на код используя фишку C++17, что позволяет захватывать *this как копию экземпляра. В таком случае лямбда будет содержать безопасную копию this, не смотря на то, что объект удален.
Маленькая ремарка: копия создается, когда вы создаете лямбда объект, это не то место где вы его вызываете (спасибо JFT за комментарий).
Теперь после всех изменений код работает, как мы ожидаем.
Конечно не всегда возможно изменить код как в примере, но в множестве случаев, вам и не понадобится копировать this. Одно из мест, где можно увидеть подобный пример - это callbacks для события в пользовательском интерфейсе, для QT например.
Вам нужно будет следить за тем, чтобы экземпляр объекта присутствует и еще жив.
Заключение
На протяжении всей статьи мне хотелось предупредить о некоторой сложности в случае, когда вам необходимо захватить переменные: использование после удаления и проблемы синхронизации (потоков).
Лямбда делает захват объекта из внешней области видимости легким и вы можете забыть применить правильный механизм синхронизации для захваченного объекта, или просто проверить «жива ли ссылка» на объект. Однако если вы пишете код для потоков в виде раздельных функций, тогда «захват переменной» становится более сложной задачей, но вы становитесь более осведомленным в проблемах синхронизации.
Старайтесь делать код читабельным при написании потоков.
Автор оригинального текста: Bartlomiej Filipek
Оригинальная статься (https://www.cppstories.com/2020/05/lambdas-async.html/?m=1)