Использование AWS, Python
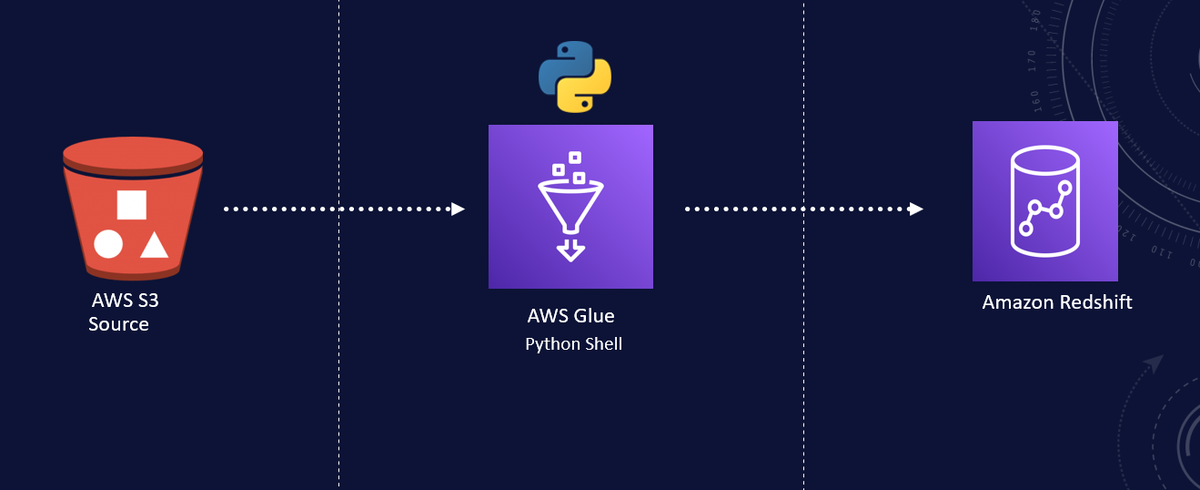
AWS Glue - это полностью управляемая служба ETL от Amazon Web Services. Он предлагает различные среды для выполнения задач ETL. У нас есть возможность использовать AWS Glue Spark или использовать Python Shell jobs. Последний тип заданий может быть более экономичным вариантом для обработки небольших или средних наборов данных. Кроме того, если ваша команда хорошо владеет языком Python, то это не составит труда.
Python shell jobs совместимы с Python версий 2 и 3, а среда выполнения поставляется с предустановленными наиболее популярными приложениями, такими как Numpy, pandas и другие. В Glue мы также можем установить другие дополнительные библиотеки, от которых зависят наши сценарии.
Python shell позволяет нам:
- Создавать хорошо структурированные конвейеры ETL на нашем любимом языке.
- Упростить Python и получить мощь библиотек предварительной сборки
- Создавать и управлять скриптовыми конвейерами данных в виде кода Python
- Отслеживать, контролировать и управлять своими ETL-конвейерами через консоль AWS.
Предварительные требования
Существует несколько предварительных условий для работы с оболочкой Python. Нам понадобится S3 bucket для хранения наших скриптов. Кроме того, нам понадобится AWS CLI, установленный и настроенный на машине разработчика. Вы можете загрузить AWS CLI для вашей операционной системы с этого URL. После установки вы можете настроить его с помощью ключей доступа и секретных ключей.
Мы можем проверить, правильно ли установлен AWS CLI, выполнив команду AWS dash dash version. Если он установлен, это вернет версию AWS CLI.
Создание файла .whl
Первым шагом будет создание файла Python .whl, содержащего необходимые библиотеки. Мы можем создать его в интерфейсе командной строки (CLI). Мы создадим каталог aws_glue_python_shell, а внутри этого каталога создадим файл setup.py. В файле setup.py мы разместим следующий код. В этом файле мы можем перечислить необходимые библиотеки для нашего скрипта.
from setuptools import setupsetup(
name="glue_python_shell_sample_module",
version="0.1",
install_requires=[
"psycopg2"
]
)
Для создания файла мы вводим в терминале следующий код.
python setup.py bdist under wheel
Эта команда создаст файл .whl и различные папки. Мы сосредоточимся на папке dist. Именно здесь мы создадим наш скрипт ETL.
Скрипт ETL
Внутри папки dist создадим наш сценарий ETL с именем etl.py. Этот файл будет содержать сценарий ETL. В самом начале мы импортируем библиотеку psycopg2. Используя psycopg2, мы создаем соединение с базой данных redshift.
Мы будем использовать команду copy для копирования данных S3 в таблицу redshift. Мы вызываем команду copy, затем указываем таблицу и столбцы. В пункте from мы указываем имя объекта S3. Затем мы предоставляем учетные данные в виде роли IAM. Убедитесь, что эта роль связана с кластером redshift. Это файл с разделителями-запятыми, и мы пропускаем первую строку.
Мы создаем курсор из переменной соединения и выполняем команду copy. Это позволит прочитать данные из объекта S3 и сохранить их в указанной таблице Redshift. После завершения выполнения скриптов мы закрываем курсор и соединение:
№ Obtaining the connection to RedShift
con=psycopg2.connect(dbname= 'dev', host='redshift.amazonaws.com', port= '5439', user= 'awsuser', password= '*****')# Copy Command as Variable
copy_command="""copy src_dimproductsubcategory (productsubcategorykey ,productsubcategoryalternatekey ,englishproductsubcategoryname ,spanishproductsubcategorysame,frenchproductsubcategorysame ,productcategorykey )
from 's3://your-s3-bukcet-name/public/DimProductSubcategory/DimProductSubcategory.csv'
iam_role 'arn:aws:iam::8040854000:role/'
DELIMITER ','
IGNOREHEADER 1;"""# Opening a cursor and run copy query
cur = con.cursor()
cur.execute("truncate table src_dimproductsubcategory;")
cur.execute(copy_command)
con.commit()# Close the cursor and the connection
cur.close()
con.close()
Загрузка скриптов в S3
Мы готовы к развертыванию нашего сценария. Давайте скопируем наши сценарии в целевой bucket S3. Мы скопируем файл .whl в папку lib и файл etl.py в папку Scripts. В терминале мы вводим команду copy:
aws s3 cp glue_python_shell_sample_module-0.1-py3-none-any.whl s3://your-s3-bukcet-name/lib/
Мы можем подтвердить это, зайдя в bucket S3 и обновив страницу. Наш файл скопирован. Аналогично мы можем скопировать etl.py в папку Scripts в bucket S3:
aws s3 cp etl.py s3://your-s3-bukcet-name/scripts/
Работа AWS Glue
В консоли AWS Glue мы можем создать задание, используя наш скрипт. Итак, давайте нажмем на Add Job. Укажите имя для этого задания и нам нужно указать роль IAM. Под типом мы выберем оболочку Python и предоставим существующий скрипт для этого задания. Здесь мы выберем путь S3 к нашему файлу etl.py, он находится в папке Scripts.
В разделе безопасность и конфигурация мы зададим путь к библиотеке python. Еще раз нажмите на значок папки, перейдите в папку lib и выберите файл .whl. Сохраним эту работу. Появится сценарий. Здесь мы можем просмотреть его, чтобы убедиться, что все в порядке. Мы обновим хост и пароль, а также предоставим фактический ARN роли IAM. Наше задание сохранено. Однако перед его запуском давайте убедимся, что таблица, которую мы пытаемся заполнить, существует в базе данных. Если ее нет, то нам нужно будет ее создать.
Вернувшись в AWS Glue, давайте выберем задание и запустим его. Отлично, задание поставлено в очередь. Мы можем выбрать задание снова, и пользовательский интерфейс отобразит статус задания. Мы можем нажать на значок обновления, чтобы увидеть обновления. В зависимости от объема данных это может занять некоторое время. Через двадцать с небольшим секунд это задание вернуло статус успеха.
Мы можем просмотреть журнал, перейдя по URL-адресу журнала рядом со статусом задания. Чтобы проверить данные, мы можем перейти в консоль redshift и выполнить оператор select для нашей таблицы. Оператор select возвращает данные, поэтому мы успешно загрузили данные S3 в redshift с помощью задания Python Shell в AWS Glue. В журналах CloudWatch видно, что мы выполнили файл .whl, загрузили библиотеку psycopg2 и установили ее.
Заключение
- Мы успешно выполнили ETL в AWS Glue с помощью оболочки Python.
- Мы показали, как создать файл .whl с зависимостями пакетов.
- Мы реализовали конвейер ETL (Extract, Transform and Load) с помощью Python и AWS Glue.



















