Анализ различных статистических показателей, представленных временными рядами, это необходимая часть современных научных прикладных исследований в науке о даннных
Пакет Python для постраения уравнения SDE из данных временных рядов.
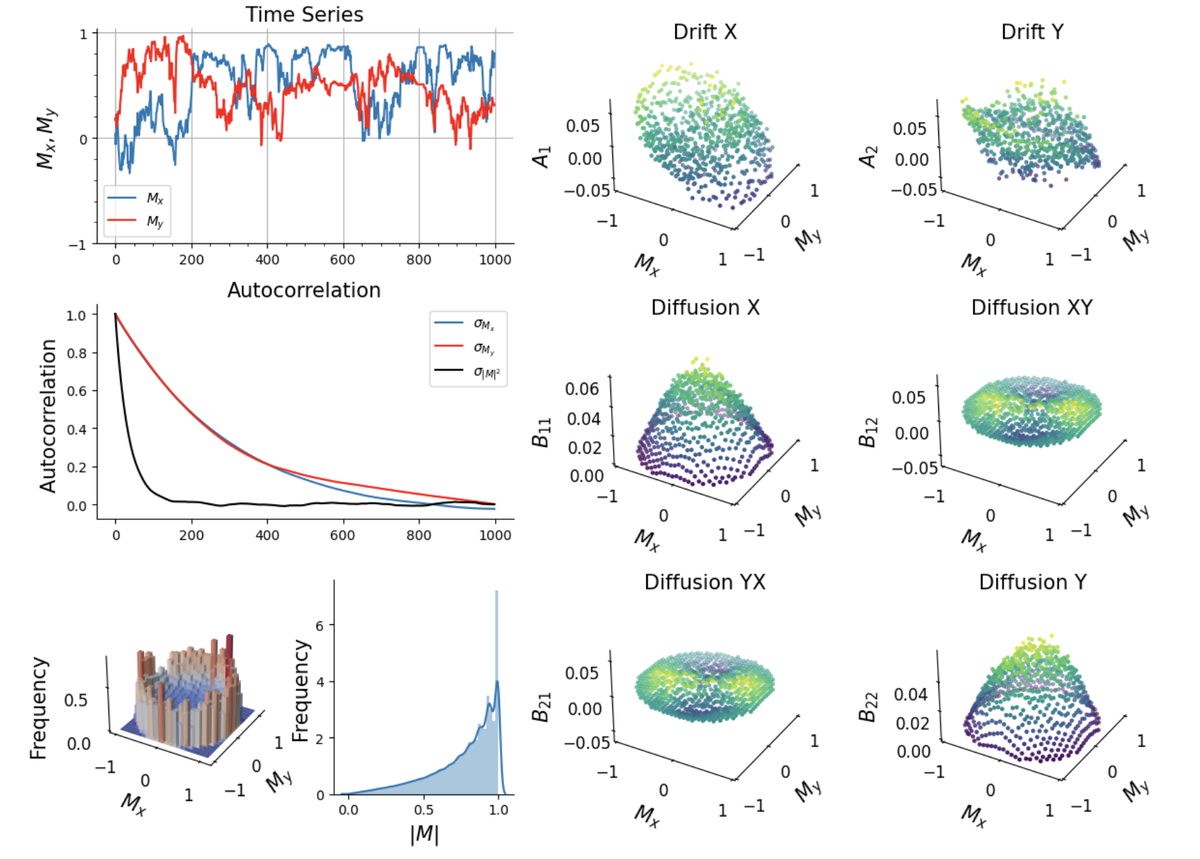
PyDaddy — это полезнный и простой в использовании пакет Python для получения стохастических дифференциальных уравнений на основе данных из временных рядов. PyDaddy который принимает временной ряд переменной состояния (x) в качестве входных данных и выводит SDE в форме:
где η(t) — некоррелированный белый шум.
Функция f называется дрейфом и управляет детерминированной частью ураавненния.
g2 называется диффузией и определяет стохастическиую фуннкцию динамики.
В PyDaddy реализованы специальные функции визуализации и анализа данных, которые помогают пользователю интерпретировать свои данные.
Установка
PyDaddy доступен для установки через PyPi, и в anaconda и работает с python3.
pip install pydaddy
или
pip install git+https://github.com/tee-lab/PyDaddy.git
Через anaconda
conda install -c tee-lab pydaddy
Кроме того, пакет также можно установить, клонировав/загрузив репозиторий git и запустив файл setup.py.
git clone https://github.com/tee-lab/PyDaddy.git
cd PyDaddy
python setup.py install
Функции PyDaddy
- Аализ временных рядов в пару строк кода
- Способен различать системы с похожим поведением в устойчивом состоянии.
- Создает интуитивно понятное представление данных и полученного результата.
- Поддерживает данные временных рядов как со скалярными, так и с векторными значениями .
- Помогает понять изменения в порядке дрейфа и распространения в различных временных масштабах.
- Генерирует интерактивные, дрейфовые и диффузионные данные для заданного пользователем диапазона или списка временной шкалы.
Инициализация объекта pydaddy
Чтобы начать анализ, нам нужно создать объект pydaddy с нашим набором данных. Это позволит паукету вычислить дрейф в данных и создать сводный график визуализации. Чтобы инициализировать объект pydaddy, нам нужно передать следующие аргументы:
data: данные временных рядов могут быть одномерными или двумерными. Для пример будет иметь дело с 1D данными. pydaddy предполагает, что выборки расположены равномерно. data передается в виде массивов Numpy
t: Это может быть либо скаляр, обозначающий временной интервал между выборками, либо массив, обозначающий отметку времени каждой выборки.
Ниже приведены некоторые полезные необязательные аргументы (подробное описание каждого необязательного аргумента см. в документации).
В этом примере используется образец набора данных, загруженный с помощью функции. load_sample_dataset Подробнее о форматах данных и загрузке/сохранении данных см.
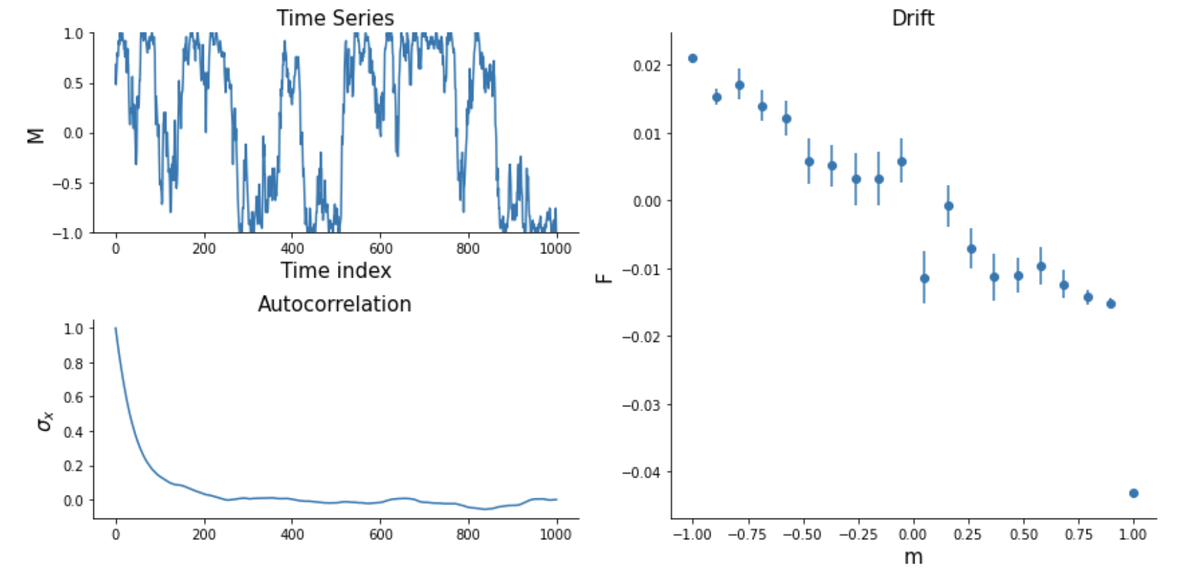
Еще пример:
ddsde.summary()
Документация: https://pydaddy.readthedocs.io/
#dataanalytics #software #datascientist #javascript #iot #java #coder #ml #analytics #webdevelopment



















