Обработка больших датафреймов с помощью Pandas происходит медленно, поскольку эта Python-библиотека не поддерживает работу с данными, которые не помещаются в доступную память. В результате рабочие процессы Pandas, которые хорошо работают для прототипирования нескольких МБ данных, не масштабируются до десятков или сотен ГБ реального датасета. Поэтому из-за однопоточного выполнения операций в оперативной памяти Pandas не очень подходит для обработки действительно больших наборов данных. с большими наборами данных. Есть альтернатива – Python-библиотека Modin с Pandas-подобным API, которая масштабируется по всем ядрам процессора, используя Dask или Ray движок.
Modin поддерживает работу с данными, которые не помещаются в памяти, так что вы можете комфортно работать с сотнями ГБ, не беспокоясь о существенном замедлении или ошибках памяти. Благодаря поддержке кластера и вне ядра Modin представляет собой библиотеку DataFrame с отличной производительностью на одном узле и высокой масштабируемостью в кластере.
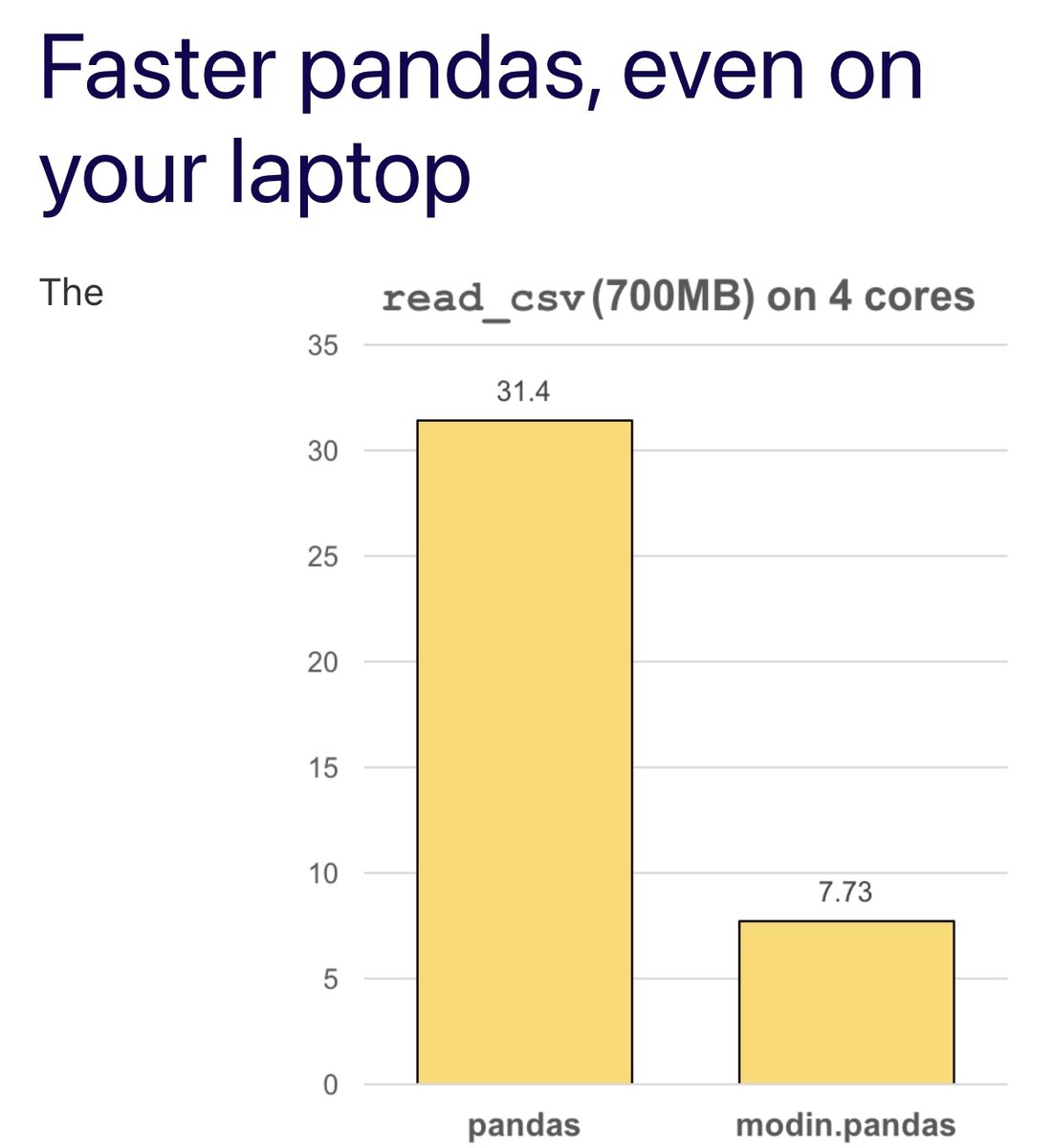
В локальном режиме (без кластера) Modin создаст и будет управлять локальным (Dask или Ray) кластером для выполнения. При этом не нужно указывать, как распределять данные, или даже знать, сколько ядер у системы. Фактически, можно продолжать использовать код с Pandas, просто изменив оператор импорта библиотек с pandas на modin.pandas и получая значительное ускорение даже на одной машине. Modin обеспечивает ускорение до 4 раз на ноутбуке с 4 физическими ядрами.
Документация: https://modin.readthedocs.io/en/latest/index.html
Github: https://github.com/modin-project/modin