Если вы работаете с текстовыми данными, изучите эти методы Pandas.
Текстовые данные обычно несут больше информации, чем числа.
Как бы мне ни нравилось работать с числами, текстовые данные постоянно присутствуют в моем рабочем процессе. Я не измерял и не анализировал их, но мне кажется, что количество текстовых данных у меня больше, чем числовых.
Наиболее существенное различие между текстовыми и числовыми данными заключается в том, сколько и предварительной обработки они требуют.
Числовые данные обычно приходят в формате, который можно напрямую использовать в анализе или моделировании данных. Если это не так, они требуют нескольких небольших штрихов, чтобы быть готовыми к работе.
С другой стороны, текстовые данные могут поступать в различных форматах. Более того, различные наблюдения одного и того же атрибута могут быть представлены не в стандартном формате.
В Python текстовые данные представлены в виде строк. Строка - это последовательность символов Юникода. В отличие от некоторых других языков программирования, в Python нет символьного типа данных, поэтому один символ - это строка длиной 1.
К счастью, Pandas упрощает и ускоряет работу с текстовыми данными. В этой статье мы рассмотрим методы Pandas, используемые для этой цели.
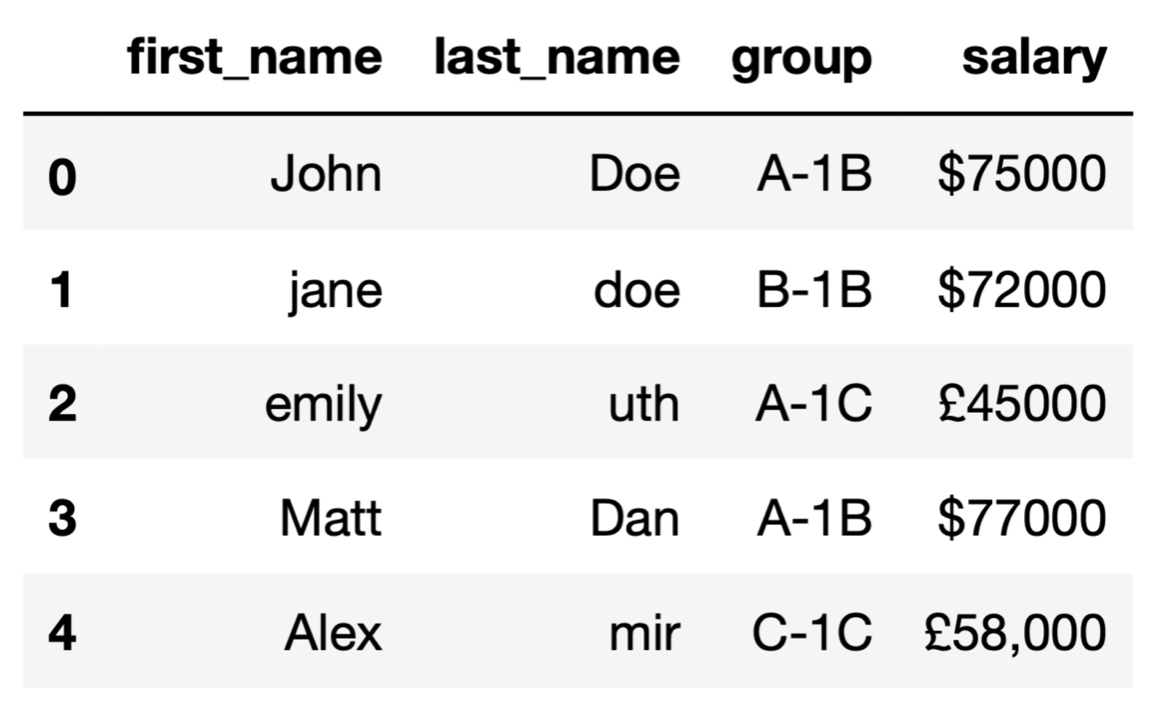
Сначала создадим пример DataFrame, заполненный текстовыми данными.
import pandas as pd
df = pd.DataFrame({
"first_name": ["John","jane","emily","Matt","Alex"],
"last_name": ["Doe","doe","uth","Dan","mir"],
"group": ["A-12","B-15","A-18","A-12","C-15"],
"salary": ["$75000","$72000","£45000","$77000","£58,000"]
})
df
Строковый тип данных
По умолчанию строки хранятся с типом данных "объект". Это может привести к проблемам в работе так как нестроковые данные также могут храниться с этим типом данных. Поэтому в Pandas версии 1.0 был введен новый тип данных для строк: "StringDtype".
Доступ к строковым методам Pandas можно получить через аксессор str.
Разделение строк
Строка может содержать несколько частей информации. Например, типичный адрес содержит информацию об улице, городе и штате. В нашем макете DataFrame колонка группы состоит из двух частей, объединенных дефисом. Если мы хотим представить группы в двух отдельных столбцах, мы можем разделить его.
df["group"].str.split("-")
# output
0 [A, 1B]
1 [B, 1B]
2 [A, 1C]
3 [A, 1B]
4 [C, 1C]
Name: group, dtype: object
Выходные значения представляют собой списки, содержащие каждый элемент, созданный после разбиения. Мы можем создать отдельные столбцы с помощью параметра expand.
df["group"].str.split("-", expand=True)
# output
0 1
0 A 1B
1 B 1B
2 A 1C
3 A 1B
4 C 1C
Name: group, dtype: object
Теперь на выходе получается DataFrame, поэтому мы можем использовать его для создания новых столбцов.
df["group1"] = df["group"].str.split("-", expand=True)[0]
df["group2"] = df["group"].str.split("-", expand=True)[1]
df
Объединение(комбинирование)
Так же, как мы разделяем строки, нам иногда нужно их объединить. Давайте создадим столбец name, который будет включать как имя, так и фамилию. У нас есть два варианта:
Метод кошки
+ оператор
# метод 1
df["first_name"].str.cat(df["last_name"], sep=" ")
# метод 2
df["first_name"] + " " + df["last_name"].
# output of both 1 and 2
0 John Doe
1 jane doe
2 emily uth
3 Matt Dan
4 Alex mir
dtype: object
Обратите внимание на то, что символы в этих столбцах записаны в смешанном регистре. Python считает, что "Doe" и "doe" - это не одно и то же. Таким образом, прежде чем объединить их, нам нужно сделать их либо в нижнем регистре, либо в верхнем. Другая альтернатива - набрать их заглавными буквами, что означает, что только первая буква будет в верхнем регистре.
# lowercase
df["first_name"].str.lower() + " " + df["last_name"].str.lower()# output
0 john doe
1 jane doe
2 emily uth
3 matt dan
4 alex mir
dtype: object
----------------------------------------------------------------
# capitalize
df["first_name"].str.capitalize() + " " + df["last_name"].str.capitalize()# output
0 John Doe
1 Jane Doe
2 Emily Uth
3 Matt Dan
4 Alex Mir
dtype: object
Мы можем использовать результат, полученный выше, для создания нового столбца. Я хочу, чтобы столбец name был первым, поэтому я воспользуюсь функцией insert, которая позволяет создать столбец в определенном месте.
name = df["first_name"].str.lower() + " " + df["last_name"].str.lower()
df.insert(0, "name", name)
df
Индекс
Иногда нам необходимо извлечь числовые данные из строк. Типичным примером такого случая является столбец "Зарплата". Нам нужно удалить знаки валюты и запятую.
Мы уже упоминали, что строки - это последовательность символов, поэтому для доступа к символам мы можем использовать индексирование. Поскольку знаки валют являются первыми символами, мы можем удалить их, выбрав символы, начиная со вторых.
df["salary"].str[1:]# output
0 75000
1 72000
2 45000
3 77000
4 58,000
Name: salary, dtype: object
В одном из значений в качестве разделителя тысяч используется запятая. Мы можем удалить ее с помощью метода replace.
df["salary"].str[1:].str.replace(",","")# output
0 75000
1 72000
2 45000
3 77000
4 58000
Name: salary, dtype: object
Запятая была заменена на пустую строку, что равносильно ее удалению. Еще одна замечательная вещь, которую мы видим в приведенном выше примере, заключается в том, что несколько операций со строками могут быть выполнены за один шаг.
Если мы хотим использовать эти очищенные значения зарплаты для создания числового столбца, нам также нужно изменить его тип данных. Давайте сделаем все это за один шаг.
df["salary_numeric"] = df["salary"].str[1:].str.replace(",","").astype("int")
df.dtypes
# output
name object
first_name object
last_name object
group object
salary object
group1 object
group2 object
salary_numeric int64
dtype: object
Кодирование категориальных значений
Мы очистили строковые столбцы, но этого может быть недостаточно, если мы хотим использовать их в модели машинного обучения. Некоторые алгоритмы не принимают строковые значения, поэтому нам необходимо преобразовать их в числовые значения с помощью кодирования меток или одноточечного кодирования.
Кодирование меток - это просто замена строк на числа. Давайте выполним кодирование меток для столбца "group1". Мы можем вручную заменить значения на числа, но это довольно утомительная работа. Кроме того, количество отдельных значений велико, поэтому этот метод нецелесообразен.
Лучший вариант - изменить тип данных этого столбца на категорию, а затем использовать коды категорий.
df["group1"] = df["group1"].astype("category")
df["group1_numeric"] = df['group1'].cat.codes
df[["group1", "group1_numeric"]]
Каждая категория заменяется номером. Однако, если среди категорий нет иерархии, кодирование меток неприменимо для некоторых алгоритмов. В приведенном выше примере категории C может быть придано большее значение.
В таких случаях следует использовать однократное кодирование, что означает создание нового столбца для каждого отдельного значения. Функция get_dummies может быть использована для однократного кодирования столбца или столбцов.
pd.get_dummies(["group1"])
Значение в столбце "group1" равно A, тогда значение в столбце A становится 1, и так далее.
Спасибо, что читаете нас!
!