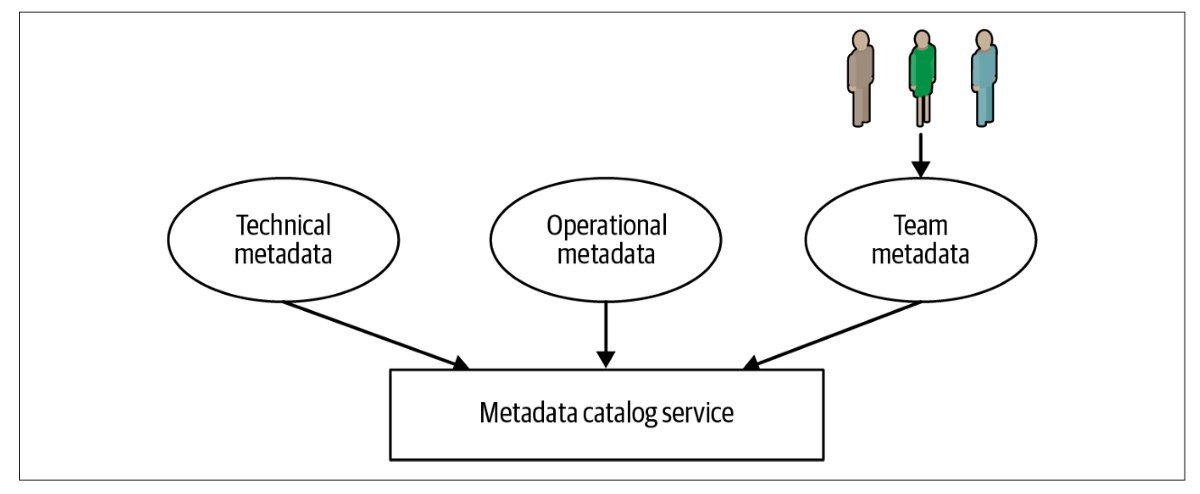
Маркируйте их метаданные и разделите на 3 категории: технические (логические и физические), операционные (статистика происхождения и профилирования данных) и метаданные команды от Data Scientist’ов и аналитиков.
Чтобы лучше понять каждый набор данных, задайте следующие вопросы:
1. Что логически представляют данные? Что означают атрибуты? Это источник истины или получен из другого набора данных?
2. Какова схема данных? Кто этим управляет? Как это было преобразовано?
3. Когда он последний раз обновлялся? Данные многоуровневые? Где предыдущие версии? Можно ли доверять этим данным? Насколько надежно качество данных?
4. Кто и/или какая команда является владельцем? Кто пользователи?
5. Какие механизмы запросов используются для доступа к данным? Версии наборов данных?
6. Где находятся данные? Где это тиражируется и в каком формате?
7. Как физически представлены данные и можно ли получить к ним доступ?
8. Существуют ли аналогичные наборы данных с общим похожим или идентичным содержанием как в целом, так и для отдельных столбцов?
Когда у вас есть ответы на эти вопросы по всем наборам данных, можно создать службу каталога метаданных, которая является важным строительным блоком платформ Data Lake / Data Mesh / Data Lakehouse. Эта служба обычно собирает метаданные после того, как наборы данных были созданы или обновлены различными конвейерами, не мешая владельцам или пользователям наборов данных.
https://medium.com/wrong-ml/why-is-understanding-datasets-hard-in-the-real-world-6eec47cafaa1