Введение
Мы рассмотрели идею k-Fold кросс-валидации и как ее реализовать на Python. В частности, мы сосредоточимся на настройке гиперпараметров, а не на оценке производительности модели. Давайте начнем!
Пошаговое объяснение
В этом примере мы будем использовать набор данных Iris и метод K ближайших соседей, наша цель - предсказать подвид цветка на основе егохарактеристик . Мы пройдем этот процесс шаг за шагом.
1. Импортируем пакеты
Первое, что мы делаем, - это импортируем нужные нам пакеты.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_validate
from prettytable import PrettyTable
2. Чтение данных
Не забудьте сохранить данные Iris в том же каталоге, что и ваш скрипт Python, вы можете скачать данные здесь.
data = pd.read_csv('IRIS.csv')
3. Быстрый просмотр да
data.head()
То, что мы увидим, - это первые 5 строк набора данных. В частности, у нас есть 4 характеристики цветка Iris (ширина и длина чашелистика, ширина и длина лепестка), а целевой атрибут - последний столбец (мы хотим предсказать, к какому подвиду принадлежит цветок Iris).
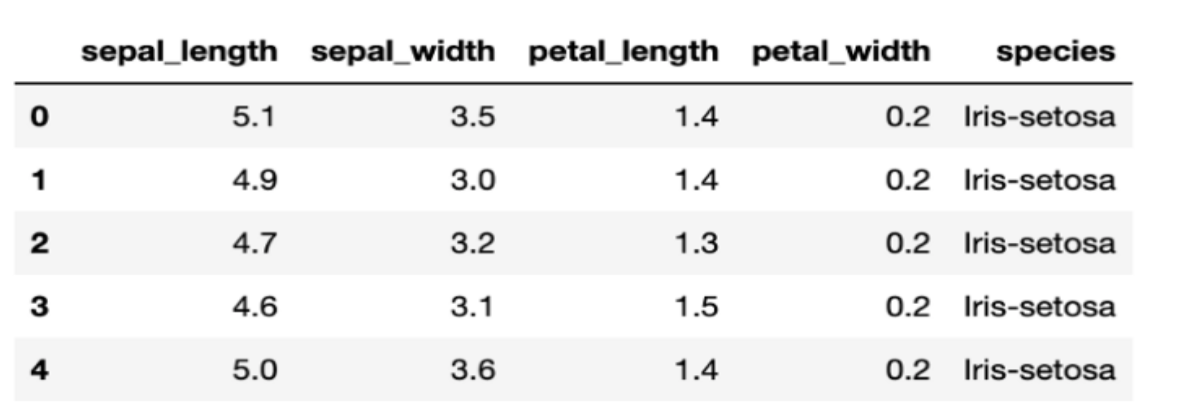
Конечно, мы можем провести дополнительную проверку. Допустим, мы хотим посмотреть статистическую сводку по всем числовым столбцам, просто используем data.describe().
4. Метод Train/Test split
Чтобы сделать нашу оценку производительности обоснованной, нам нужно разделить данные на обучающий и тестовый наборы, мы будем использовать разделение 80/20 (80% - обучение, 20% - тестирование). Помните, что тестовый набор используется ТОЛЬКО при тестировании.
Характеристики (независимые атрибуты) - это первые 4 столбца, а цель предсказания - последний столбец. Таким образом, мы сначала создаем две переменные, characteristics и target.
Затем мы используем функцию train_test_split чтобы разделить набор данных. Первый параметр - это зависимые переменные, второй - независимая/целевая переменная.Параметр test_size означает долю данных, используемых при тестировании. Мы делаем его 0,2, так как выбираем разделение 80/20.
characteristics = data.iloc[:,:4] # the first 4 columns
target = data.iloc[:,-1] # the last column
x_train, x_test, y_train, y_test = train_test_split(characteristics, target, test_size=0.2, random_state=2727)
5. Перекрестная проверка для настройки гиперпараметров
В этом примере мы допускаем, что p равно [1, 2, 3], n_neighbors равно [2, 3, 4, 5, 6]. О значение этих параметров можно почитать здесь. В этой части мы хотим найти самую эффективную модель предскзания с определенной комбинацией гиперпараметров.
myTable = PrettyTable(["p (distance)", "Number of neighbors", "Avg accuracy"])
for row in hyperparameter_score_list: myTable.add_row([row[0], row[1], round(row[2],3)])
print(myTable)
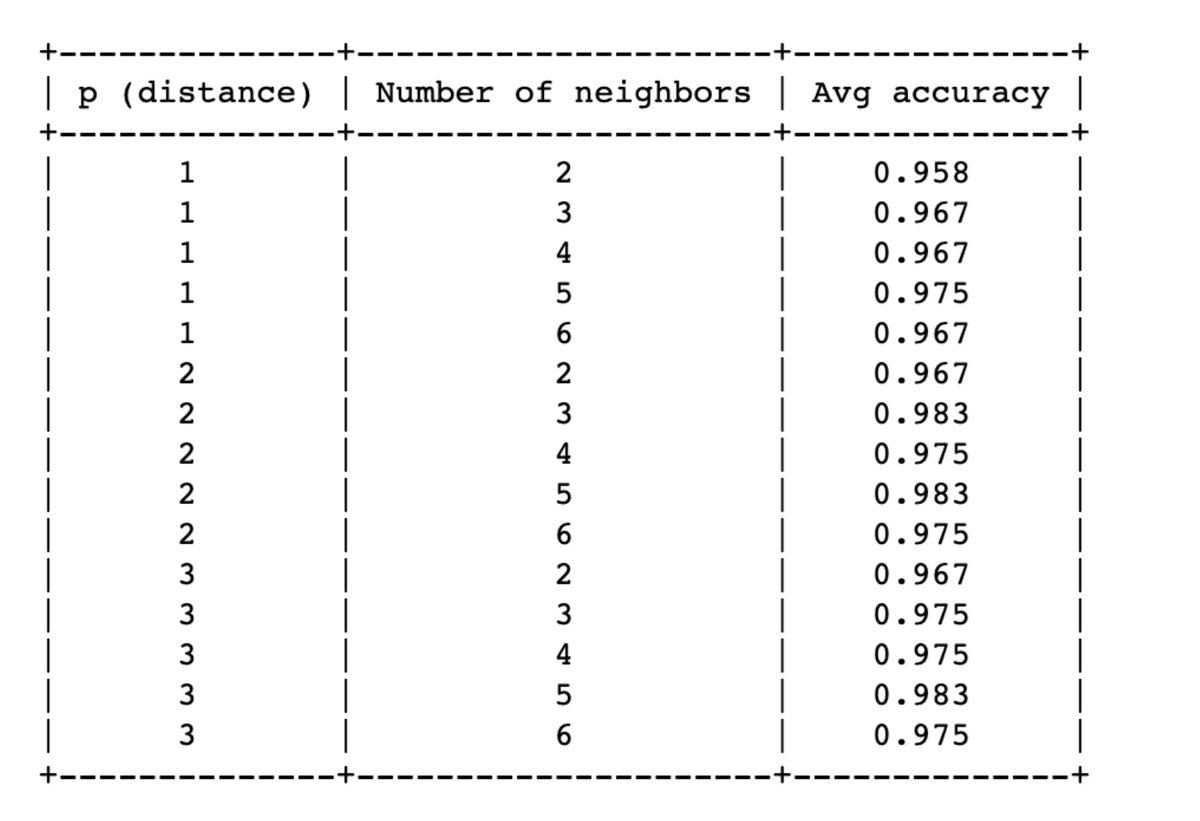
Ясно, что несколько комбинаций гиперпараметров имеют самую высокую среднюю точность - 0,983. Для простоты мы случайным образом выбираем p=2, n_neighbors=3 как наши лучшие параметры.
7. Оценим производительность модели на тестовом наборе данных
Это ПОСЛЕДНИЙ шаг! Мы выбрали гиперпараметры, которые лучше всего работают среди всех кандидатов, поэтому теперь мы подбираем модель с этими параметрами.
Затем мы используем модель для прогнозирования тестового набора и возьмем точность предсказания алгоритма в качестве окончательной оценки производительности модели. Это может быть сделано с помощью метода score в подобранной модели.
knn = KNeighborsClassifier(p=2, n_neighbors=3)
knn_best_model = knn.fit(x_train, y_train)
print("Best Model Testing Score: ", knn_best_model.score(x_test, y_test))
Финальная точность оказывается равной 0,933! Это показывает, что мтеод K ближайших соседей с p=2, n_neighbors=3 довольно хорошо работает с тестовым набором данных. Следует отметить, что точность предсказания не является идеальной, вам все равно нужно изучить другие показатели производительности, чтобы определить, подходит ли модель для вашей работы или ннет.
Код
Я собрал весь код вместе ниже, чтобы вы могли попытаться запустить и понять его, и я надеюсь, что эта статья поможет вам немного лучше понять кросс-валидацию k-fold .