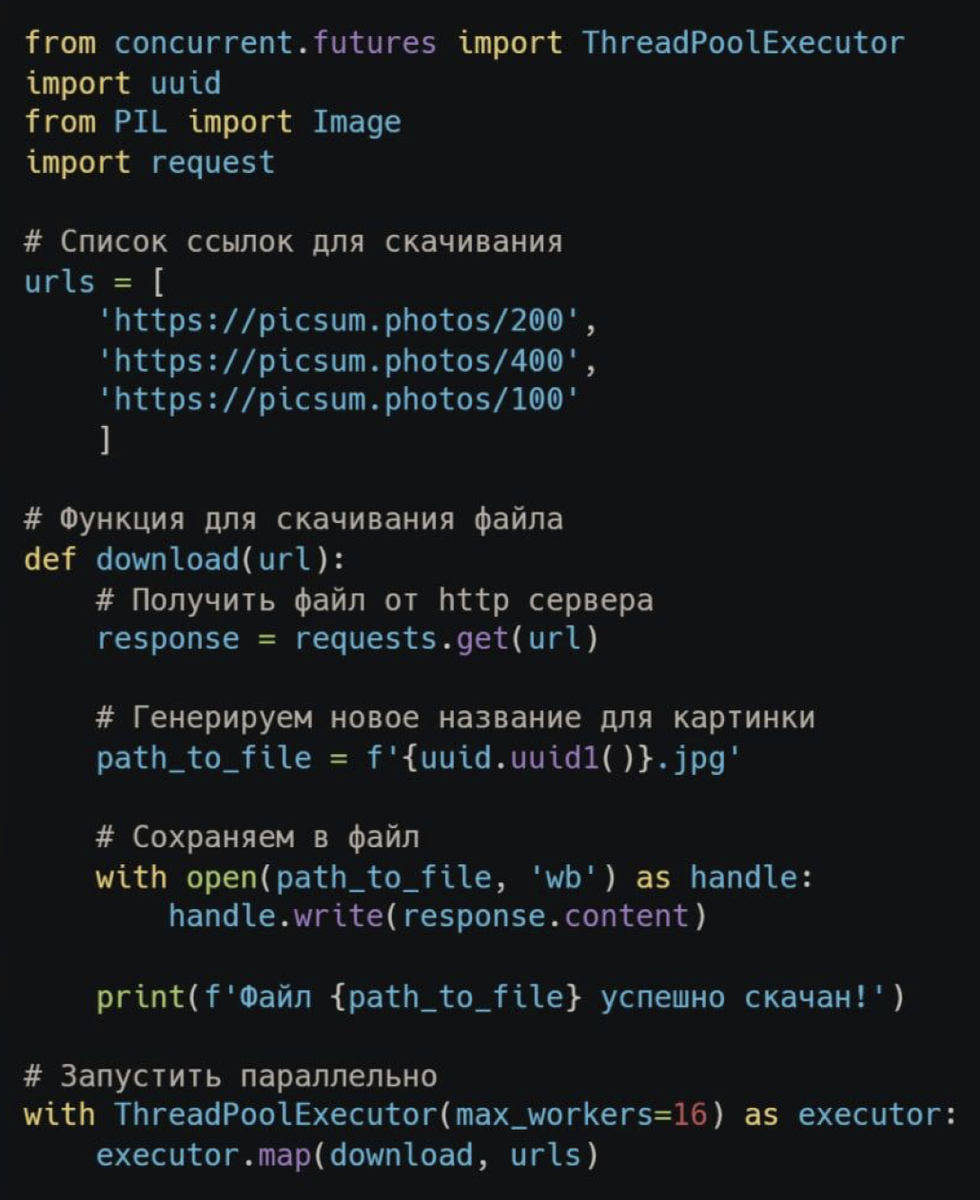
Имея список ссылок на картинки, которые нужно скачать, мы можем это сделать используя простой цикл for, тем самым скачав их последовательно одна за одной.
Но в таких ситуациях как эта (скачивание огромного количества небольших файлов) распараллеливание задачи существенно ускорит процесс.
Для этого воспользуемся функцией ThreadPoolExecutor из стандартного пакета concurrent.futures. Она позволяет запустить нашу функцию, в нескольких екземплярах в параллельных потоках. В конструкторе необходимо указать максимальное количество потоков, которые будут одновременно запущены.
Далее метод .map(download, urls) создает екземпляры нашей функции для скачивания файла, и раскидывает в них элементы списка urls.
Но будьте внимательны: так как скачивание файла — это IO-операция, такой метод не ускоряет вычисления кода. Он лишь позволяет запустить скачивание следующего файла, не дождавшись пока скачается предыдущий.
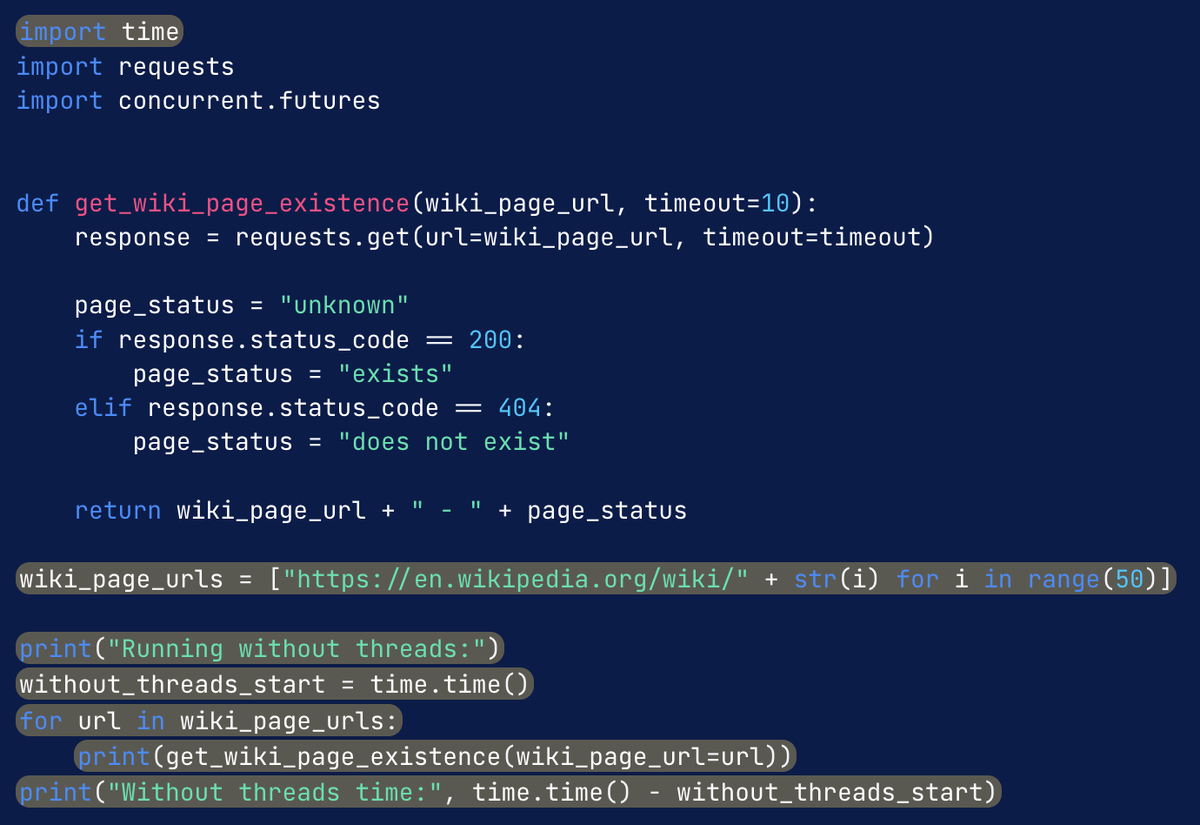
В этом пример кода мы вызываем функцию get_wiki_page_existence с пятьюдесятью разными URL страниц Wikipedia по одной. Мы используем функцию time.time() для вывода количества секунд выполнения нашей программы.
Ознакомиться с интерактивным примером можно тут.
Документация.
#threading
#python