Вы хотите развернуть приложение, которое может быть в облаке или локально, и вы не можете использовать что-либо предварительно созданное просто потому, что оно не дает вам достаточного контроля над всеми его функции использовать. Предположим, например, что вашему приложению для работы требуется графический процессор, и вам также по какой-то причине нужно передать динамические изображение shm. В этой статье рассматриваются две вещи:
1. Как включить доступ к графическому процессору в сервисе docker swarm? (поскольку вы не можете использовать --gpus, как в docker run)
2. Как передать аргумент размера shm при создании службы docker swarm?
Что такое Docker Swarm?
Если вы хотите масштабировать приложение в облаке или локально, то одним из способов сделать это является создание образа докера вашего приложения и его настройка с помощью инструмента оркестровки. Вы наверняка слышали о Kubernetes, верно? Ну, Docker Swarm — это другое. Docker swarm — это инструмент настройкой контейнеров с архитектурой master-worker.
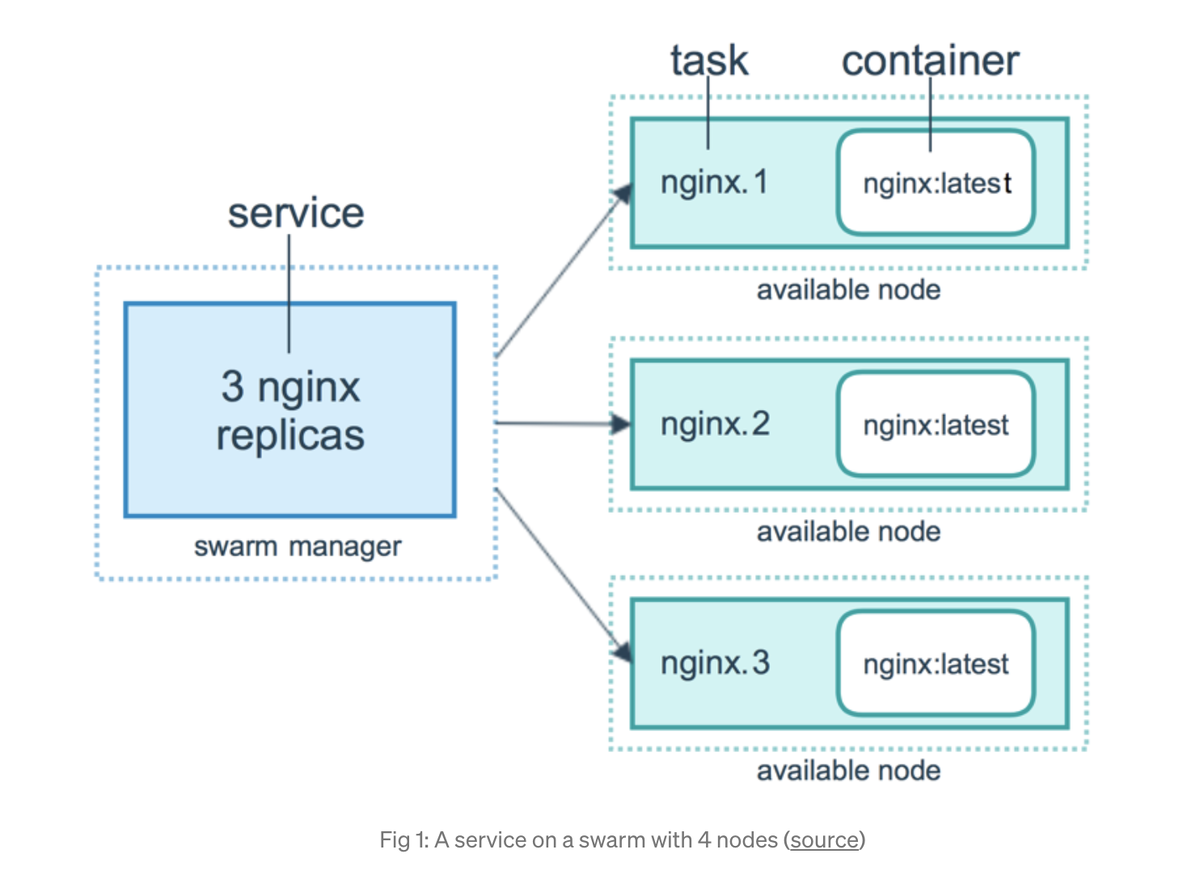
Как видите, Docker Swarm, также называемый кластером, состоит из 4 узлов. Главный узел называется Swarm manager а остальные — workers (рабочими). Взаимодействовать и запускать команды с кластером можно через менеджер .
Я рекомендую просмотреть документацию для получения дополнительной информации, если вы новичок в этом. Давайте быстро перейдем к нашей основной цели этой статьи. Сначала мы возьмем образ докера сервера Triton из каталога Nvidia NGC и модель машинного обучения из их репозитория Github. Позже мы развернем сервер в Docker Swarm . В настоящее время у меня есть одна машина, поэтому я не смогу показать вам настройку с несколькими узлами, но добавление нового узла — это всего лишь однострочная команда.
Конфигурация для настройки графического процессора для Docker Swarm
[Linux-based OS (Ubuntu 20.04 in my case) and Nvidia GPUs (gtx 1660ti, driver version 510.47)]
$ nvidia-smi -a | grep UUID

Обновите файл /etc/docker/daemon.json до этого и включите uuid вашего графического процессора:
{
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
},
"default-runtime":"nvidia",
"node-generic-resources": [
"NVIDIA-GPU=GPU-4b0429cc"
]}
Затем раскомментируйте вторую строку в /etc/nvidia-container-runtime/config.toml, чтобы ваш файл выглядел так:
disable-require = false
swarm-resource = "DOCKER_RESOURCE_GPU"
#accept-nvidia-visible-devices-envvar-when-unprivileged = true
#accept-nvidia-visible-devices-as-volume-mounts = false[nvidia-container-cli]
#root = "/run/nvidia/driver"
#path = "/usr/bin/nvidia-container-cli"
environment = []
#debug = "/var/log/nvidia-container-toolkit.log"
#ldcache = "/etc/ld.so.cache"
load-kmods = true
#no-cgroups = false
#user = "root:video"
ldconfig = "@/sbin/ldconfig.real"[nvidia-container-runtime]
#debug = "/var/log/nvidia-container-runtime.log"
Перезапустите docker service:
$ sudo systemctl restart docker.service
Извлеките образ сервера Triton Inference из каталога Nvidia NGC и создайте каталог модели для сервера. (Сервер Triton Inference — это всего лишь пример приложения, которое можно организовать на docker swarm/k8s, использующем GPU.)
Создайте Docker Raw:
$ sudo docker swarm init --advertise-addr <ip-of-any-network-interface>
Эта команда инициализирует кластер докеров с этой машиной в качестве менеджера .
Примечание: вы можете использовать команду ifconfig, чтобы узнать IP для разных сетевых интерфейсов.
Запустите службу с доступом к графическому процессору.
Для доступа к GPU используется аргумент --generic-resource "NVIDIA-GPU=0" , а для размера shm --mount type=tmpfs,target=/dev/shm .
Как видно из картинки, мы успешно создали службу, которая имеет доступ к графическому процессору и может использовать неограниченный объем общей памяти. Теперь вы можете масштабировать систему до нужных вам размеров и кластер увеличится.
Ссылки:
https://gist.github.com/tomlankhorst/33da3c4b9edbde5c83fc1244f010815c
https://github.com/triton-inference-server/server
https://docs.docker.com/engine/swarm/