Использование предварительно обученных моделей значительно улучшило нейронный машинный перевод (NMT). В отличие от ранних алгоритмов машинного перевода, где предварительно обученные модели обычно используют однонаправленный декодер, в этой статье показано, что предварительное обучение модели последовательностей, но двунаправленным декодером, может привести к заметному повышению производительности как для авторегрессионного, так и для неавторегрессионного NMT. В частности, мы представляем модель CeMAT, условную маскированную языковую модель, предварительно обученную на больших двуязычных и одноязычных корпусах на многих языках. Мы также представляем два простых, но эффективных метода улучшения CeMAT: метод согласованного переключения и и динамическое двойное маскирование. Мы проводим обширные эксперименты и показываем, что с помощью CeMAT можно добиться значительного повышения производительности. Для неавторегрессионного NMT модель может давать постоянный прирост производительности до 5,3 BLEU. Это первая работа по предварительной подготовке единой модели для настройки обеих задач NMT.
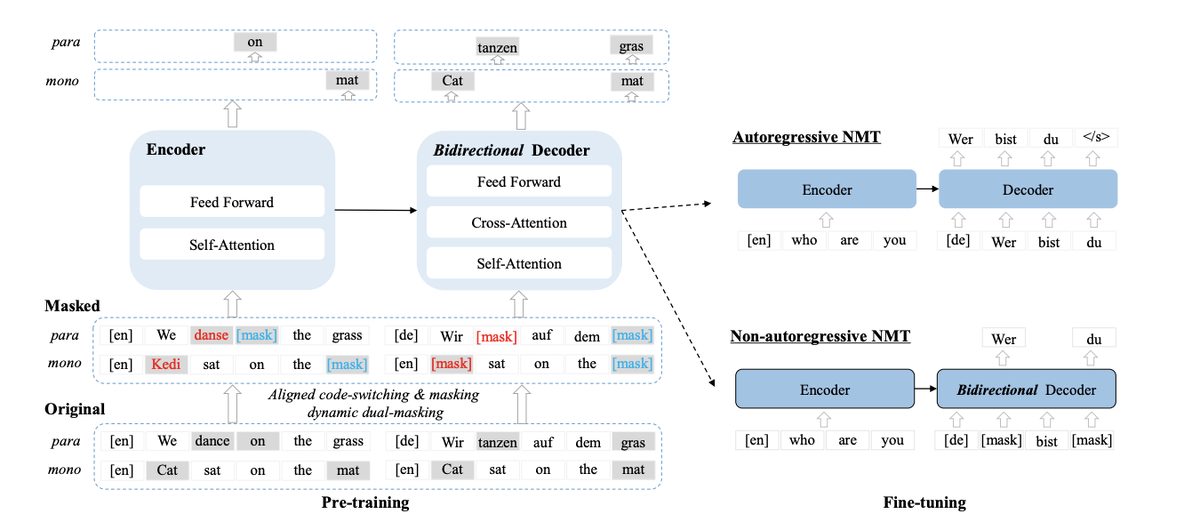
Рис. 1. Структура CeMAT, состоящая из кодера и двунаправленного декодера.
Код, данные и предварительно обученные модели доступны:
Код: https://github.com/huawei-noah/Pretrained-Language-Model/CeMAT