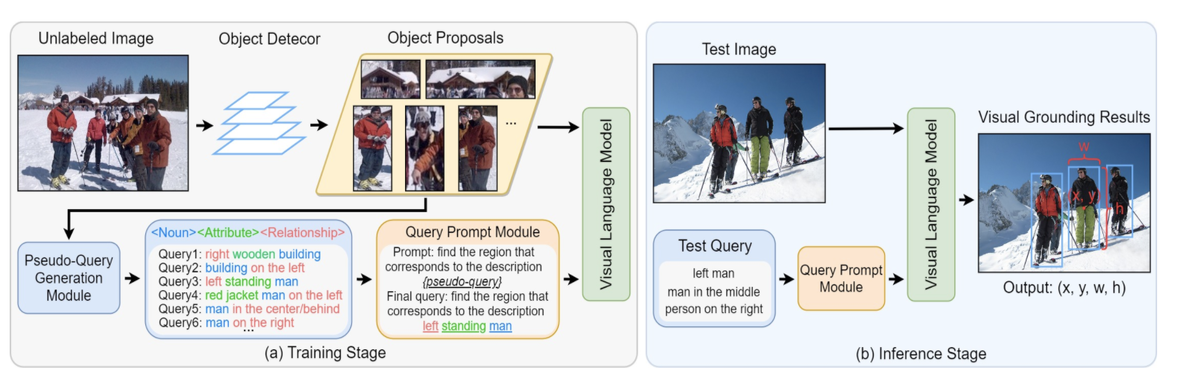
Мы представляем новый метод, названный Pseudo-Q, для автоматической генерации псевдоязыковых запросов для обучения моделей машинного обучения. Наш метод использует готовый детектор объектов для идентификации визуальных объектов из немаркированных изображений. Обширные экспериментальные результаты показывают, что наш метод имеет два заметных преимущества над другими методами : (1) он может значительно снизить затраты человека на разметку данных, в наших тестах удалось снизить время на подготовку данных на 31% для датасета RefCOCO, без ухудшения производительности исходной модели при полностью контролируемой настройке, и (2) без настроек в коде, метод достигает превосходной или сопоставимой производительности по сравнению с современными методами мл на всех пяти наборах данных, с которыми мы экспериментировали.
Подготовка данных
1.Вы можете скачать изображения из данного источника и поместить их в папку ./data/image_data:
https://github.com/lichengunc/refer
https://bryanplummer.com/Flickr30kEntities/
RefCOCO и ReferItGame
Flickr30K Объекты
2. Сгенерированные пары можно загрузить с Tsinghua Cloud: https://cloud.tsinghua.edu.cn/f/5b8dc3dc289c49c18740/?dl=1
mkdir data
mv pseudo_samples.tar.gz ./data/
tar -zxvf pseudo_samples.tar.gz
Предварительно подготовленные модели
1. Вы можете загрузить модели DETR из Tsinghua Cloud. Эти контрольные точки следует загрузить и переместить в каталог контрольных точек.
mkdir checkpoints
mv detr_checkpoints.tar.gz ./checkpoints/
tar -zxvf checkpoints.tar.gz
2. Контрольные точки, обученные на наших псевдообразцах, можно скачать с Tsinghua Cloud
mv pseudoq_checkpoints.tar.gz ./checkpoints/
tar -zxvf pseudoq_checkpoints.tar.gz
Подробнее: https://github.com/leaplabthu/pseudo-q
Статья: https://arxiv.org/abs/2203.08481v1



















