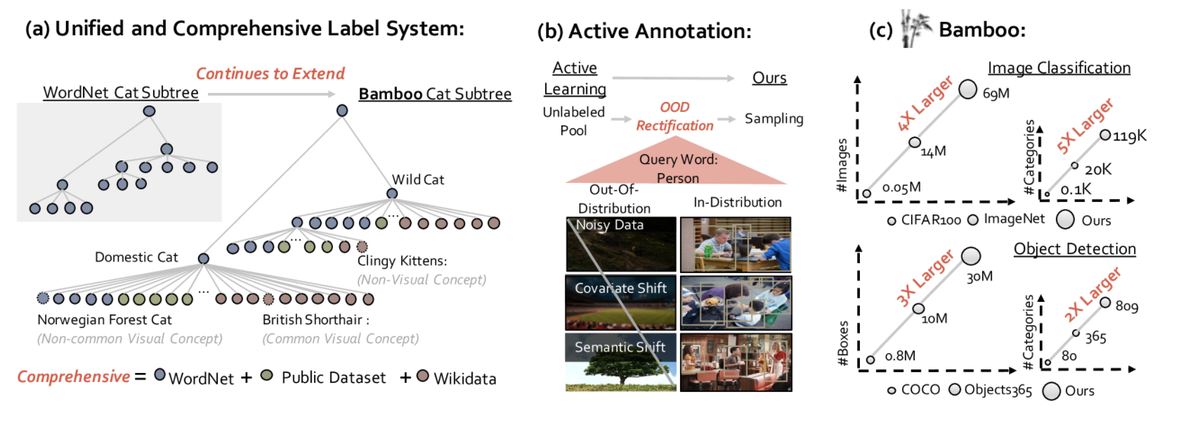
Крупные наборы данных играют жизненно важную роль в компьютерном зрении. Существующие наборы данных либо собираются в соответствии с эвристическими системами маркировки, либо собираются вслепую без дифференциации на категории, что делает их неэффективными и немасштабируемыми. Вопрос о том, как систематически собирать, аннотировать и создавать мегамасштабный набор данных, остается открытым. В этой статье мы выступаем за активное и постоянное создание высококачественного набора данных для компьютерного зрения на основе комплексной системе маркировки. В частности, мы предоставляем Bamboo Dataset, мегамасштабный и информационный набор данных как для классификации, так и для обнаружения объектов. Bamboo стремится заполнить всеобъемлющие категории аннотациями классификации изображений 69M и аннотациями ограничивающей рамки 170 586 объектов. По сравнению с ImageNet22K и Objects365, модели, предварительно обученные на Bamboo, достигают превосходной производительности при выполнении различных задач распознавания образов(прирост на 6,2% при классификации и прирост на 2,1% при обнаружении объектов). Кроме того, мы предоставляем ценные данные после масштабного предварительного обучения из более чем 1000 экспериментов. Благодаря своей масштабируемости как в системе распознавания, так и в конвейере аннотаций, Bamboo будет продолжать расти и улучшаться от коллективных усилий сообщества, которые, как мы надеемся, проложат путь для улучшения моделей компьютерного зрения
Код и модель: https://github.com/davidzhangyuanhan/bamboo
Документация: https://opengvlab.shlab.org.cn/bamboo/home
Paper: https://arxiv.org/abs/2203.07845
.