В нашем корпоративном блоге вышла моя новая статья “Регулярные выражения для интернет-маркетинга ”. Перенесу сюда, чтобы всегда была под рукой.
Введение
Регулярные выражения это инструмент, который часто помогает мне сводить многочасовую рутинную работу к нескольким минутам. Это автоматизация, о которой мечтают многие специалисты, но мало кто с ней знаком на практике.
В этой статье я расскажу про основной синтаксис регулярных выражений и на примерах покажу как их можно использовать в работе.
Регулярные выражения — это инструмент для поиска в тексте элементов и подстрок, соответствующих заданному при поиске шаблону. Проще говоря — регулярные выражения помогают найти в тексте все места, где встречается нужный набор символов.
https://regex101.com/ — сайт, на котором можно проверить свое регулярное выражение. В статье я привожу скриншоты с работой регулярок с этого сайта.
Сразу предупрежу, что в статье я описываю не все возможности регулярных выражений. Каждое из приведенных мною выражений можно оптимизировать и сократить.
Но именно в таком формате, по-моему, тема регулярных выражений должна быть максимально понятна для новичков.
Синтаксис регулярных выражений
В интернете есть большое количество статей по регуляркам. Многих новичков такие статьи пугают своими размерами, обилием новых терминов, символов и сокращений.
На самом деле, большая часть регулярных выражений, это синтаксический сахар. Он делает работу с регулярными выражениями удобнее. Но обращать внимание на такой сахар стоит уже после того как освоился с ядром. Само “ядро” регулярок состоит из 5 простых правил.
Синтаксический сахар (англ. syntactic sugar) в языке программирования — это синтаксические возможности, применение которых не влияет на поведение программы, но делает использование языка более удобным для человека.
Источник Wikipedia.
Сразу предупрежу, что изначально регулярные выражения чувствительны к регистру. То есть буква “а” и буква “А” это разные буквы. Подробнее о таком поведении, и как его изменить, вы можете прочитать в разделе “Модификаторы”.
1. В какой части текста находится искомая подстрока
Для простоты понимания договоримся что конец текста это переход на новую строку, а начало текста это начало строки.
- Если вы точно не знаете в какой части находится искомый текст, игнорируем это правило;
- Если искомый текст надо найти только в начале строки, используйте знак крышечки ^ ;
- Если искомый текст надо найти только в конце строки, используйте знак доллара $ .
ПРИМЕР : Найдем в тексте слово “яблоко ”:
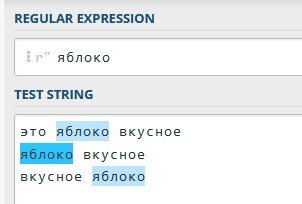
Описание: Поиск везде
Выражение : X
Пример : яблоко
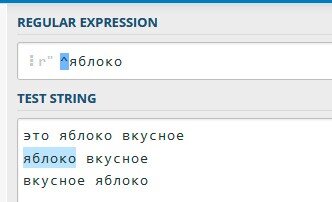
Описание: Поиск в начале
Выражение : ^ X
Пример : ^ яблоко
Описание: Поиск в конце
Выражение : X$
Пример : яблоко$
2. Или, или
Если надо найти подстроку, которая может принимать несколько разных значений, достаточно перечислить все искомые значения в круглых скобках через знак вертикальной черты ( | ) .
ПРИМЕР : Найдем в тексте слово “яблоко ” или “груша ”:
Описание: Или, или
Выражение : (X| Y)
Пример : (яблоко| груша)
3. Проверки
Проверки — это поиск подстроки, с условием, что перед (или после) ней точно должна быть (или не должна быть) другая подстрока. Всего есть 4 типа проверок:
- Позитивная опережающая проверка — найти X при условии, что за ним следует Y.
- Негативная опережающая проверка — найти X при условии, что за ним НЕ следует Y.
- Позитивная ретроспективная проверка — найти X при условии, что перед ним находится Y.
- Негативная ретроспективная проверка — найти X при условии, что перед ним НЕТ Y.
ПРИМЕР : Найдем в тексте слово “яблоко ” с учетом проверок.
Описание: Найти X при условии, что за ним следует Y
Выражение : X(?= Y)
Пример : яблоко(?= сочное)
Что ищем: Сочные яблоки
Описание: Найти X при условии, что за ним НЕ следует Y
Выражение : X(?! Y)
Пример : яблоко(?! сочное)
Что ищем: Не сочные яблоки
Описание: Найти X при условии, что перед ним находится Y
Выражение : (?<= Y) X
Пример : (?<= Зеленое) яблоко
Что ищем: Зеленые яблоки
Описание: Найти X при условии, что перед ним НЕТ Y
Выражение : (?<! Y) X
Пример : (?<! Зеленое) яблоко
Что ищем: Не зеленые яблоки
Обратите внимание, что в примерах регулярных выражений стоят пробелы. Это важно, так как пробел тоже является знаком.
4. Поиск букв, цифр и символов
Как видно из примеров выше, при помощи регулярных выражений можно искать слова целиком.
Но настоящая сила регулярных выражений заключается в том, что они могут найти подстроки, которые содержат любые нужные нам наборы букв, цифр или символов. Даже если мы заранее не знаем их точного порядка.
4.1. Группировки и срезы
Группировка — указание списка (группы) букв, цифр и символов, которые должны присутствовать в искомой подстроке.
Искомая группа объектов перечисляется внутри квадратных скобок [ ] .
Например, регулярное выражение [абв37,] найдет в тексте все места, в которых встречаются буквы “а”, “б”, “в” или цифры “3”, “7” или символ запятой “,”.
Если в искомой строке может быть любая буква алфавита или любая цифра, используется срез.
Срез — указание первой и последней буквы или цифры через тире. При этом будут включены все буквы и цифры, находящиеся между указанными.
Например, регулярное выражение [а-я] найдет в тексте все места, в которых встречаются буквы от “а” до “я”.
Примеры срезов:
Описание: Найдет все кириллические буквы в верхнем регистре.
Выражение : [А-Я]
Описание: Найдет все цифры.
Выражение : [0-9]
Описание: Найдет все латинские буквы в нижнем регистре.
Выражение : [a-z]
Описание: Найдет все кириллические и латинские буквы в верхнем и нижнем регистрах, цифры от 0 до 9 и символы запятой, точки, амперсанд и пробел.
Выражение : [А-яA-z0-9,.& ]
4.2. Количество вхождений
Искомые нами подстроки могут содержать определенное количество букв, цифр или символов. Или вообще их не содержать.
И в этом случае регулярные выражения смогут найти то, что нам нужно:
Описание: Поиск без оператора.
Пример : купить грушу и яблоко
Описание: Одно или ни одного вхождения.
Выражение : X?
Пример : купить грушу( и яблоко)?
Описание: Много или ни одного вхождения.
Выражение : X*
Пример : купить грушу( и яблоко)*
Описание: Одно или много вхождений.
Выражение : X+
Пример : купить грушу( и яблоко)+
Описание: Вхождение 3 раза.
Выражение : X{3}
Пример : а{3}
Описание: Вхождение от 3 и более раза.
Выражение : X{3,}
Пример : а{3,}
Описание: Вхождение от 3 до 6 раз.
Выражение : X{3,6}
Пример : а{3,6}
Описание: Вхождение до 6 раз.
Выражение : X{,6}
Пример : а{,6}
4.3. Отрицание
Если необходимо найти подстроки, с учетом, что в них НЕ должны входить какие-то буквы, цифры или символы, достаточно перечислить необходимые символы в группировке, добавив в начале группировки знак крышечки ^ .
Описание: Найти символы, кроме указанных.
Выражение : [^ X]
Пример : [^ а]
5. Скрытые символы
Выше я обращал внимание на то что, если в искомой подстроке есть пробел, его необходимо указывать явно.
Кроме пробела есть и другие скрытые символы, которые могут быть найдены.
- \n — Перенос на новую строку.
- \r — Возвращение каретки в начало строки. Обычно используется совместно с переносом на новую строку.
- \t — Табуляция.
- \ — Изоляция символа. Например, нужно найти подстроку со знаком звездочки. Достаточно искать \* .
- . — Любой символ.
- .* — Любое количество любых символов.
Модификаторы
Модификаторы (или флаги) — это дополнительные настройки, которые изменяют поведение регулярного выражения.
В большинстве инструментов модификаторы вынесены в отдельные настройки регулярок, или настроены максимально дружелюбно, чтобы понять, что именно пользователь хочет найти.
Пример настройки модификаторов в Notepad++ .
Модификатор Global (глобальный поиск)
Описание :
- С выключенным модификатором останавливается после нахождения первой подходящей подстроки.
- С включенным модификатором найдет все вхождения.
Отображение : /g
Выключенный global модификатор:
Включенный global модификатор:
Модификатор Multiline (мультистроковость)
Описание :
- С выключенным модификатором концом строки будет считать конец всего текста. А началом строки будет считать начало текста.
- С включенным модификатором концом строки будет считать перенос на новую строку. А началом текста будет считать начало новой строки.
Отображение : /m
Выключенный multiline модификатор:
Включенный multiline модификатор:
Модификатор Case insensitive (чувствительность к регистру)
Описание :
- С выключенным модификатором будет считать буквы в верхнем и нижнем регистре разными символами.
- С включенным модификатором будет считать буквы в верхнем и нижнем регистре одним и тем же символом.
Отображение : /i
Выключенный case insetsitive модификатор:
Включенный case insetsitive модификатор:
Примеры использования регулярных выражений
В начале статьи я говорил, что регулярки помогают мне сокращать рутинную работу, поэтому дальше покажу рабочие примеры использования регулярных выражений.
Кейс 1
Задача: Есть интернет-магазин. Необходимо получить информацию о количестве товаров в каждом каталоге. Всего на сайте 2500+ каталогов товаров. Информация о количестве товаров выводится на странице каталога в текстовом блоке, которые имеет вид: “Название каталога N”, где N — это количество товаров.
Решение:
- Получаем список всех каталогов с количеством товаров.
- Видим что в каталоге может быть количество товаров с числом состоящим от 1 до 3 цифр. А название каталога может содержать кириллические и латинские буквы.
- Определяем что количество товаров мы можем получить при помощи регулярного выражения через позитивную ретроспективную проверку + количество вхождений от 1 до 3.
Регулярное выражение: (?<=[А-Яа-яA-Za-z])[0-9]{1,3}
Кейс 2
Задача: Федеральный сайт по продаже специализированного оборудования. Необходимо визуализировать воронку оформления заявки в Google Data Studio.
Решение:
- Выгружаем из Google Analytics данные по url из воронки.
- Видим, что на некоторых этапах воронки в URL добавляется город посетителя. А на некоторых этапах в URL добавляется название товара.
- Добавляем пользовательский параметр с настройкам:
Заключение
Польза регулярных выражений в их гибкости. Ведь все те примеры, что я приводил, можно использовать совместно друг с другом.
Bonus: Сокращения
Как я говорил в начале статьи, у регулярных выражений есть большое количество синтаксического сахара, который помогает делать сами регулярные выражения короче. Но такие вещи могут путать и пугать новичков. Поэтому привожу примеры сокращений в конце основной статьи.
Описание : Найти пробелы, переносы строк или табуляцию.
Регулярное выражение: ( |\t|\r\n)
Сокращение : \s
Описание : Любые символы кроме пробела, переноса или табуляции.
Регулярное выражение: [^( |\t|\r\n)]
Сокращение : \S
Описание : Любые цифры.
Регулярное выражение: [0-9]
Сокращение : \d
Описание : Любые символы, кроме цифр.
Регулярное выражение: [^0-9]
Сокращение : \D
Описание : Любые буквы, цифры и подчеркивание.
Регулярное выражение: [A-zА-я0-9_]
Сокращение : \w
Описание : Любые символы кроме букв, цифр и подчеркиваний.
Сокращение : \W



















