
Новичкам, порой, очень сложно начать изучать машинное обучение в виду большого количества новых терминов. А для русскоязычного сообщества вдвойне тяжело, потому что многие понятия представлены на английском. Цель данной статьи стереть эту грань языкового барьера и дать возможность русскоязычному сообществу вникать в термины.
В данной статье продолжаем разбор основных понятий на русском от канала What's AI, из их плейлиста.
В данной статье будут рассмотрены следующие понятия:
- Artificial General Intelligence
- Neural Network
- Computer Vision
- Chatbot
- Image Segmentation
- Object Detection
- RNN
- Transfer Learning
- Data Science
- Data Mining
Если Вы не читали первую часть разбора, то обязательно начните сначала с неё. Как и в прошлый раз для простоты я буду прикреплять оригинальное видео на английском и снизу оставлять комментарии на русском. таким образом вы сможете посмотреть оригинал и прочитать на русском коротко для лучшего понимания.
Общий искусственный интеллект против AI
Artificial General Intelligence (AGI, общий искусственный интеллект) — это термин, призванный заменить оригинальное название AI (искусственный интеллект). Сделано это из-за того, что термин AI используется для всего, что связано с машинным обучением.
AI (ИИ) было создано для обучения делать что-либо. Его основная цель в некотором исследовании в области искусственного интеллекта (ИИ), общих тем в научной фантастике и будущих исследований.
AGI это совершенно другая сущность. Это ИИ, способный обучаться делать различные вещи. Его применением может служить любая задача от редактирования фото до обработки социальных сетей.
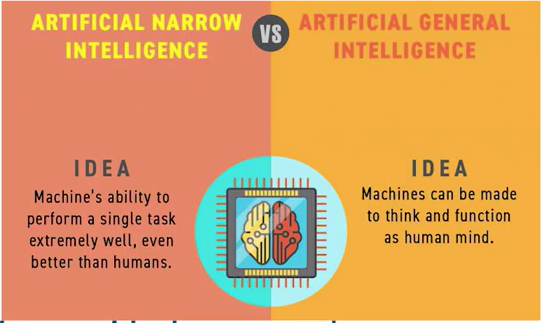
То есть ещё раз. ИИ — для обучения одной конкретной вещи. AGI — для обучения делать несколько вещей.
Для большей специфичности AGI мог бы обучаться, планировать, размышлять, общаться на естественном языке и применять данные навыки для любой задачи. Совсем как человек.
Сегодня системы с машинным обучением дополняют онлайн сервисы, позволяя компьютерам понимать речь, определять лица и места на фото, описывать фото и видео. Недавние открытия и прорывы, такие как AlphaGo, способны вдохновить общество на путь разработки AGI.
AGI пока ещё не разработан. Он больше представлен в научной фантастике и фильмах о будущем. AGI это в основном то, что люди представляют себе, когда речь идёт об искусственном интеллекте.
Что такое Neural Network?
Neural Network (Нейронная сеть) — это сеть нейронов, или как модно сейчас говорить, искусственная нейронная сеть, состоящая из искусственных нейронов.
Данная сеть имитирует нейроны человеческого мозга, используя узлы, соединения и веса, чтобы найти подходящие выходные данные для конкретных входных данных.
Нейронная сеть основана на коллекции соединённых узлов, называемыми искусственными нейронами, которые свободно моделируют нейроны человеческого мозга. Каждое соединение подобно синапсам в мозгу могут передавать сигналы другим нейронам. Искусственный нейрон, получивший сигнал, обрабатывает его и может послать другой сигнал нейронам, соединённым с ним.
Такие системы обучаются, чтобы выполнять задачи на примерах в основном без задания (программно) специальных правил. Например, в распознавании изображений (image recognition), такие сети могут определять изображение, на которых изображён кот, анализируя изображения из обучающего набора, которые промаркированы "кот" и "не кот" и используя эти результаты для идентификации на других изображениях.
Нейронные сети делают это без предварительных знаний о котах, например, что они имеют лапы, хвост и т.д. Они наоборот автоматически генерируют характеристики, полученные из обучающего набора данных. Нейронные сети используют значения пикселей и их соседей в качестве характеристик. Компьютеры не имеют представления о том, на что они смотрят.
Давайте рассмотрим на примере. Пусть есть изображение с котом, которое подаётся на вход нейронной сети. Сеть будет использовать все пиксели изображения в качестве входящих данных.
Далее первый слой нейронов будет работать как наша сетчатка и найдёт простые особенности такие, как края. Далее в зависимости от нейронной сети следующие слои, называемые скрытыми слоями, будут обнаруживать более сложные особенности.
Входящие данные будут распространены по всей сети, которые все вместе будут способствовать нахождению результата. Например, в нашем случае это "кот".
Конечно, "веса" (weights) нейронной сети (какие нейроны использовать для нахождения правильного результата) должны быть заданы и сеть должна быть на них обучена. Это делается, используя "обратное распространение" (backpropagation), которое было объяснено в первой части статьи.
Что такое Computer Vision?
Computer Vision (или Image recognition, Компьютерное зрение) — это область искусственного интеллекта, которая обучает компьютер интерпретировать и понимать "визуальный мир". Данная область включает в себя методы обработки, анализа и понимания цифровых изображений.
Проблема компьютерного зрения кажется простой, потому как она легко решается людьми, даже маленькими детьми. Но для компьютера это совсем другое.
Это в основном остаётся нерешённой проблемой, основанной одновременно на ограниченном понимании биологического (человеческого) зрения и сложности восприятия мира в динамическом и бесконечном разнообразии мира.
Обучение компьютерного зрения и нейробиологии очень тесно связаны друг с другом, чтобы понять как мы "видим" и как мы знаем и понимаем, что "видим". В кратце, цель компьютерного зрения — понять содержимое цифрового изображения.
Понимание содержимого цифрового изображения может затрагивать извлечение описания изображения, которое может быть объектом, текстовым описанием, трёхмерной моделью и.д.
Это огромная область искусственного интеллекта, используемая индустриями, чтобы повышать потребительский опыт, уменьшение цены, повышения безопасности и т.д.
Многие приложения компьютерного зрения используются для обнаружения различных предметов и задач на изображениях. Например:
- Обнаружение предмета: Где находятся на объекты на фото?
- Классификация объектов: Какой категории объектов больше на фото?
- Сегментация объектов: Какие пиксели принадлежат объектам на изображении?
- Идентификация объекта: Какого типа представлен объект на фото?
- Проверка объекта: Присутствует ли интересующий нас объект на фото?
И так далее.
Что такое Chatbot?
Chatbot (чат-бот) — программа с искусственным интеллектом, которая может имитировать разговор с пользователем, используя текстовые сообщения, веб-сайты, мобильные приложения или просто телефон. Подобные программы спроектированы так, чтобы имитировать убедительную беседу подобно человеку.
С точки зрения технологий чат-боты представляет собой только эволюцию систем вопрос-ответ, используя NLP (обработку естественного языка, смотреть предыдущую статью).
Формирование ответов на вопросы в естественном языке — одна из самых распространённых задач в NLP, применяемое во многих приложениях.
Но почему чат-боты так важны?
Чат-боты часто описывают как один и самых продвинутых и многообещающих способов взаимодействия людей и машин.
Но как чат-боту удаётся этого достичь?
Как видно из картинки, чат-бот возвращает ответ, основанный на том, что ввёл пользователь. Этот процесс может показаться простым, однако на практике всё немного сложнее:
- Сначала чат-бот производит обработку: анализирует запрос пользователя;
- Возможность определить намерение пользователя и извлечь данные и сущности (признаки) из запроса пользователя — один из первых шагов чат-бота;
- Далее чат-бот возвращает наиболее подходящий ответ на запрос пользователя, используя NLP.
Чат-боты используются везде: мессенджеры, медицина, политика и другие. В настоящее время они предлагают компаниям новые возможности для улучшения процесса взаимодействия с клиентами и высокую оперативность путём сокращения взаимодействия с клиентами персоналу по типичным вопросам.
Что такое Image Segmentation?
Image Segmentation (Сегментация изображений) — это подобласть искусственного интеллекта и компьютерного зрения (Computer Vision, CV). В основном используется для определения положения объектов на изображении и выделения их границ.
В основном используется для разделения изображения на его области на основе некоторых критериев, когда области значимы и не пересекаются, например, найти кота на изображении и выделить область.
Но перед тем, как производить обнаружение объектов или классифицировать изображение, необходимо понять, из чего состоит изображение. Это и есть цель сегментации изображений.
Мы можем разделить изображение на части, называемые сегментами (как показано на картинке выше). Обрабатывать изображение целиком не является разумным, так как за границами объектов будет информация, не являющаяся полезной для нас. Разбивая изображение на сегменты, мы можем использовать "важные" для нас сегменты. Это, в двух словах, как работает сегментация изображений.
Изображение — это набор различных пикселей. Мы группируем пикселе вместе, которые имеют схожие атрибуты, используя алгоритмы сегментации изображений. Эти алгоритмы создают пиксельную маску для каждого объекта на изображении. Эта техника даёт нам более детальное понимание объектов на изображении, чем Обнаружение объектов (Object Detection), которое мы рассмотрим ниже.
НО для чего нам нужна эта область "Сегментация изображений"? Рассмотрим на реальном примере.
В приложениях по самоуправлению машиной нам необходимо постоянно знать, что "видит" машина и где она находится в каждый момент времени. Мы воссоздаём множество сегментов изображения, чтобы определить, что находится на изображении и что происходить в данный момент времени для безопасного вождения.
Что такое Object Detection?
Object Detection (Обнаружение объекта) — это область искусственного интеллекта и машинного обучения. Также это метод Компьютерного зрения (Computer vision) для определения положения объектов на изображении и видео.
Для человека подобная задача: посмотреть на изображение или видео и выделить объекты на нём — задача, решаемая моментально. Задача Object Detection заключается в том, чтобы поручить это искусственному интеллекту, используя компьютер.
Наша задача определять примерно, что находится на изображении. Точное обнаружение пиксель-к-пикселю всего изображения называется Image segmentation (сегментация изображения), которое было описано выше.
Самый простой способ для Object detection — это двуступенчатая нейронная сеть, называемую R-CNN (Regions with Convolutional Neural Networks, области со свёрточными нейронными сетями).
Сперва сеть определяет положение границ или подмножество на изображении, которое может содержать объект. Далее классифицирует объект, расположенный в этих границах. Эти нейронные сети имеют высокую точность, однако в основном медленнее других.
Другой подход в Object detection — это одноступенчатая свёрточная сеть YOLO (You Only Look Once), которая примерно в 100 раз быстрее лучших двухступенчатых сетей, с потерей качества всего примерно в 4%.
Данная сеть делает предсказания (predictions) о границах по всему изображению, используя anchor boxes (набор предопределённых ограничительных рамок/границ определённой высоты и ширины, подробнее тут на английском)
Object detection — одна из ключевых технологий для современных систем помощи водителям (advanced driver assistance systems, ADAS), которая позволяет машинам определять полосы движения или предупредить о пешеходе. Это также применяется в видеонаблюдении, системах поиска изображений и других.
Упомянутые выше сети будут рассмотрены далее.
Что такое RNN?
RNN (Recurrent Neural Network, RNNs, Рекуррентная нейронная сеть) — это класс искусственный нейронных сетей, специализирующийся на подходах, которые эффективны в обработке последовательной информации.
Основная особенность RNN — способность запоминать результат предыдущих вычислений и использовать их в текущем вычислении. Иными словами запоминать результат обработки на предыдущих итерациях. Это делает RNN-модели удобными для моделирования контекстных зависимостей во входных данных произвольной длины, чтобы создавать правильную композицию входных данных. Что идеально подходит для NLP (обработки естественного языка).
Как только мы подаём последовательность слов в RNN, состояние обновляется для каждого слова из входных данных. В результате "состояние" (state) становится представлением всех слов, которые были обработаны до этого момента. А так как состояние обновляется в последовательном порядке, оно будет содержать информацию о порядке слов, а также о самих словах.
Рассмотрим на примере предложения "Deep Learning is hard but fun" и рассмотрим состояния на каждом шаге, пока RNN обрабатывает это предложение.
- Когда слово "Deep" подаётся на вход RNN, состояние содержит представление только этого слова;
- Далее, когда подаём слово "Learning", состояние будет обновлено, которое содержит представление "Deep + Learning";
- ...
- Далее при прохождении всего предложения, конечное состояние будет хранить репрезентацию слов "Deep + Learning + is + hard + but + fun".
Конечно состояние хранит в себе одновременно как семантическую информацию слов в предложении, так и последовательную информацию о порядке слов. Что идеально подходит для понимания предложения, потому как так работает в нашем мозгу.
RNN находит своё применение в Text Generation (генерация текста), Machine translation (машинный перевод), Image captioning (Описывание изображений), authorship identification (идентификация авторства) и т.д.
Хотя данные приложения не заменять человека, вполне возможно, что при бОльших тренировочных данных и более громоздких моделях, нейронная сеть сможет синтезировать новые изобретения.
Что такое Transfer Learning?
Transfer Learning (Трансферное обучение) — это метод машинного обучения, при котором модель, разработанная для одной задачи, является пере используемой, т.е. становится отправной точкой для второй задачи.
Другими словами, Transfer Learning позволяет использовать накопленный при решении одной задачи опыт для решения другой, аналогичной проблемы. Данная оптимизация предоставляет стремительный прогресс или улучшение производительности при моделировании следующей задачи.
В Трансферном обучении мы сперва тренируем базовую сеть на основном датасете (наборе данных), после чего натренированные признаки переходят второй сети для тренировки на целевом датасете и задаче.
Этот процесс будет работать, если признаки общие, то есть подходящие для первой и второй задачи, в отличие от специфичных только для первой задачи. Данное обучение широко используется в CV (компьютерном зрении) и NLP (обработке естественного языка), т.к. можно взять модель, натренированную на огромном датасете в течение длительного времени. И далее использовать эту модель как отправную точку в Вашей задаче, перетренировав несколько слоёв на своем датасете.
Рассмотрим на примере. Одной из классических задач NLP является задача Sentiment Classification (классификация настроений). Целью является предсказать настроение по полученному тексту.
Настроение может быть: нейтральным, негативным или позитивным. Мы можем использовать вектора слов для решения поставленной задачи.
Но мы не хотим составлять эти вектора сами. Поэтому мы можем использовать натренированную модель, например, Word2Vec от Google для тренировки своей. Эта модель уже будет давать осмысленные вектора для наших слов, что облегчит нам задачу. Это есть самый простой пример применения Трансферного обучения.
Что такое Data Science?
Data Science (Наука о данных) — это смесь различных инструментов, алгоритмов и принципов машинного обучения, направленных на обнаружение скрытых структур из необработанных данных.
Вы уже можете заметить как данная область сильно связана с искусственным интеллектом, т.к. модели обучаются на их данных.
Как видно на изображении Data Scientist проводит не только исследовательский анализ (exploratory analysis) для извлечения признаков, но также использует различные продвинутые алгоритмы машинного обучения для идентификации вхождения конкретного события в будущем.
Data Scientist посмотрит на данные под разными углами, иногда эти "углы" не были известны ранее. Данные люди найдут лучший способ использования имеющихся данных в машинном обучении, наиболее подходящих моделях. Именно поэтому Data Scientist занимает существенную роль в области искусственного интеллекта.
Но чем конкретно занимается Data Scientist?
- Перед тем, как начать проект, необходимо понять различные технические характеристики, требования приоритеты и необходимый бюджет;
- Далее необходимо исследовать, пред обработать и обусловить данные перед моделированием;
- Далее необходимо определить методы и техники для проставления взаимосвязи между переменными;
- На этом этапе Вам необходимо разработать датасет для тренировки и тестирования модели. Вы будете рассматривать достаточно ли существующих инструментов для запуска моделей или нужна более сильная и мощная среда (например, быстрая и параллельная обработка).
- И наконец, Вы предоставите конечные отчёты, инструктажи, технические документы и требования к коду, которые удовлетворяют ключевым особенностям и определите, является ли конечный результат успешным или нет на основе требований пункта 1.
В кратце, Data Science — это обнаружение данных из данных.
Например, анализирует шаблоны просмотра фильмов, чтобы понимать, что вызывает интерес у пользователя. И использует это, чтобы решить, на какие серии необходимо создавать.
Что такое Data Mining?
Data Mining (Интеллектуальный анализ данных) — это процесс извлечения полезной информации из огромного числа данных. Используется для открытия новых, точных и полезных шаблонов в данных, обращая внимание на значение и похожую информацию информацию.
ML (машинное обучение) и Data Mining оба находятся под эгидой Data Science, так как они оба работают с данными. Оба процесса используются для решения сложных задач, в результате чего, многие люди (ошибочно) считают эти 2 термина взаимозаменяемыми.
И это не удивительно, считая, что машинное обучение иногда используется в качестве эффективного средства проведения анализа данных (data mining).
В то время, как данные собранные в анализе данных (data mining), могут использоваться для обучения компьютеров, в то же время это делает границы понимания между этими двумя концепциями размытыми. Более того, оба алгоритма используют одни и те же алгоритмы для нахождения шаблонов в данных. Хотя их желаемый результат абсолютно разный.
Data mining спроектирован для извлечения правил из огромных единиц данных, а машинное обучение учит компьютер, как обучаться и и понимать полученные параметры.
Или можно сказать по-другому. Data mining — это просто метод исследования для определения конкретного результата на основе совокупности собранных данных. С другой стороны есть машинное обучение, которое тренирует систему обрабатывать сложные задачи, использовать собранные данные и экспериментировать, чтобы стать умнее.
Data mining полагается на хранение больших данных (Big Data), которое в последствие используется для прогнозирования в бизнесах и других организациях. Машинное обучение, с другой стороны, работает с алгоритмами, а не с необработанными данными.
Но как Data Mining и машинное обучение работают вместе?
Data mining — это процесс, который объединяет в себя 2 элемента: базу данных и машинное обучение. Первый обеспечивает техники по управлению данными, второй применяет алгоритмы анализа данных.
Поэтому Data mining нуждается в машинном обучении, в то время как машинное обучение не обязательно нуждается в Data mining.
________________
На этом всё :) Остальные понятия рассмотрим в следующих частях.
Ставьте лайк, если статья понравилась и подписывайтесь на канал. Впереди ещё много интересного!