Допустим, мы получили какую то филогению. Как узнать, насколько она хороша и с какими таксонами есть проблемы? Для этого есть поддержки ветвей. Они по сути показывают, как устойчивы те или иные ветви. Хорошие поддержки говорят о том, что много признаков поддерживают ветвь и, скорее всего, она заслуживает доверия. Низкие поддержки говорят о том, что эту ветвь поддерживает мало признаков, либо есть серьезная несогласованность разных признаков в случае этой ветви. Таким образом, есть вероятность, что в результирующем дереве эта ветвь присутствует по случайности, из-за неправильной кодировки признаков (в случае морфологии) или искажений в выравнивании (в случае молекулярных данных).
Поддержки очень важны для обсуждения филогении, потому что никто всерьез не будет воспринимать рассуждения или гипотезы насчет какой-то ветви, у которой поддержки низкие или отсутствуют. Без них приличные журналы обычно не публикуют филогении.
Для морфологических филогений есть два типа поддержек:
(1) Статистические. Это bootrstrap, jacknife и symmetric resampling supports. Они варьируют от 0 до 100% ( или от 0 до 1).
(2) Bremer Supports или Decay Index. Поддержки Бремера или индекс распада. На практике от 1 до 10 (очень редко бывает больше).
Статистические поддержки
Статистический обсчет заключается в том, что во всех трех случаях немного видоизменяется матрица и на основе новой матрицы считается филогения. Суть в том, чтобы протестировать, насколько стабильна какая-то ветвь, и исчезнет ли она, если матрица немного изменится и какой-то признак в ней присутствовать не будет.
Затем сохраняется информация о том, какие ветви появляются в результирующем дереве (деревьях). Я так понимаю, что в TNT сохраняется информация только о тех ветвях, которые остаются в строго согласованном дереве (Pol & Goloboff 2020). Но, насколько я знаю, так же могут учитывать и те ветви, которые остаются на majority rule дереве (это должно происходить при подсчете бутсрапов в Maximum Likelihood).
Такой обсчет проводится обычно не менее 1000 раз (а лучше 10000 раз). В конце для каждой ветви выводится информация о том, в каком проценте случаев эта ветвь была на результирующих деревьях. Например, если мы 100 раз видоизменили матрицу, каждый раз провели анализ, и какая-то ветвь появились в результате анализа каждый раз, то ее поддержка 100% (1). Если она появилась только в половине случаев, то ее поддержка - 50% (0.5).
При подсчете Bootstrap поддержек один или несколько признаков случайным образом удаляются, и на их место копируются другие признаки из этой же матрицы. Другой способ, который приводит к тому же результату - это просто случайным образом выбирать признак за признаком из оригинальной матрицы, пока не будет достигнуто такое же количество признаков, как в оригинальной матрице. Таким образом, в видоизмененной матрице какие-то признаки из оригинальной матрицы могут присутствовать более одного раза, а другие отсутствовать.
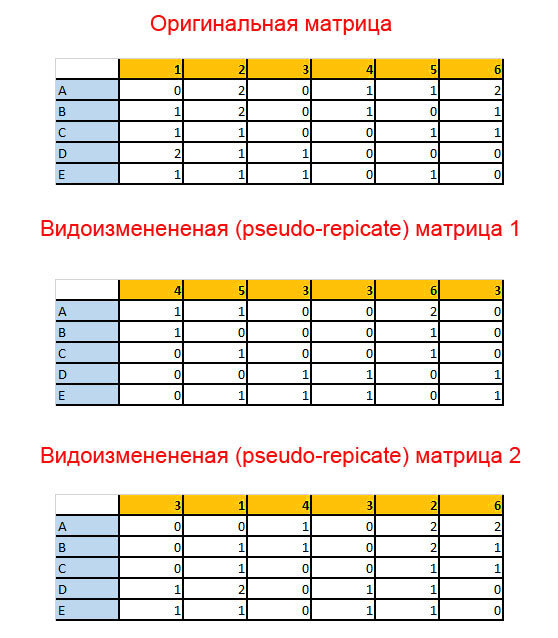
На этой картинке голубым отмечены таксоны, оранжевым - признаки. В оригинальной матрице признаки идут по порядку. В двух других случаях я использовала генератор случайных чисел, чтобы выбрать признаки из оригинальной матрицы. Так и работает бутстрап, только таких псевдореплицированных матриц надо 1000 или больше (Russo & Selvatti 2018).
Бутстрап поддержки также используются при обсчете выравниваний с помощью алгоритма Maximum Likelihood.
Для подсчета Jacknife поддержек один или несколько признаков случайным образом удаляются, и таким образом мы имеем дело с матрицей меньшей по размеру, чем оригинальная, где какие-то признаки отсутствуют. Все остальное также, как и при обсчете бутстрапов.
В TNT еще есть так называемые symmetric resampling, которые либо удаляют признак, либо увеличивают его вес. Для тех, кому интересны подробности, то вот ссылка на статью Goloboff et al. 2003. Насколько я поняла, этот вид поддержек имеет преимущество перед Bootstrap и Jacknife, если некоторые признаки имеют больший вес, либо являются аддитивными, то есть у них переходы из состояния в состояния неравноценны (про это я расскажу чуть позже).
Для парсимонии поддержки от 90 до 100 считаются высокими, от 75 до 89 считаются хорошими, и от 50 до 75 считаются плохими. Если у ветви поддержка менее 50, то считается, что ветвь не поддержана.
Для Maximum Likelihood оценка бутстрапов зависит тоже от модификации анализа, но в целом, то что ниже 70% уже считается неподдержанным.
Bremer Supports (Decay index)
Тактика подсчета поддержек в этом случае совсем иная, однако суть в том же - измерить стабильность ветвей полученной филогении.
Допустим, в результате анализа у нас получилось 10 равноэкономных деревьев с длиной 75. Мы строим строго согласованное дерево, то есть все ветви, которые отсутствуют хотя бы в одном из этих деревьев, схлопываются, образую политомию. Все оставшиеся ветви будут с поддержкой Бремера равной 1.
Затем мы берем все субоптимальные деревья, то есть это те деревья с длиной на 1 больше, чем у самых экономных деревьев, то есть с длиной 76, а также наше строго согласованное дерево, полученное на предыдущем этапе. И теперь уже строим строго согласованное дерево из всех этих деревьев. Какое-то количество ветвей опять схлопнутся, образуя политомию. Все оставшиеся ветви будут с поддержкой Бремера 2.
Затем идем еще на шаг дальше, и берем все деревья длиной 77, а также строго согласованное дерево с предыдущего этапа (то есть построенного на основе деревьев с длиной 75 и 76), и опять строим строго согласованное дерево. Теперь уже у оставшихся ветвей будет поддержка Бремера 3.
И так далее, пока все ветви не схлопнутся
Поддержка Бремера = 1 не считается за поддержку, потому что она автоматические есть у всех ветвей, которые остались в строго согласованном дереве, построенном на основе всех самых экономных деревьев. Поддержки Бремера 2 и 3 - это хотя бы какие-то, но небольшие. Поддержки 4 и больше уже считаются хорошими, и поддержка 10 - это редкость.
Думаю, что теперь стало понятно, откуда такое название Decay index (Индекс распада). Мы смотрим, когда распадаются ветви, и в соответствии с количеством шагов, которые приводят к политомии, присваиваем этой ветви поддержку.
Вполне логичный вопрос будет о том, какие поддержки выбрать. Ответ в том, что не обязательно выбирать, для морфологической матрицы можно посчитать все. Для молекулярных данных, как я уже писала, в Maximum Likelihood автоматически считаются бутстрапы, ну а для Байесова анализа там совсем другая частная история.
Goloboff, P. A., Farris, J. S., Källersjö, M., Oxelman, B., Ramıacute; rez, M. N. J., & Szumik, C. A. (2003). Improvements to resampling measures of group support. Cladistics, 19(4), 324-332.
Pol, D., & Goloboff, P. A. (2020). The impact of unstable taxa in coelurosaurian phylogeny and resampling support measures for parsimony analyses.
Russo, C. A. D. M., & Selvatti, A. P. (2018). Bootstrap and rogue identification tests for phylogenetic analyses. Molecular Biology and Evolution, 35(9), 2327-2333.