Наверняка вы натыкались на видеоролики в YouTube: вот Нью Йорк 1911 года, было так: плохое качество, много шума и мало цвета, МАГИЯ и стало 4K-разрешение и 50/60 кадров в секунду. Или улица Тверская в 1896 году - ЩЁЛК - и она преображается!
На этих записях люди не скачут по кадру как в комедиях Чарли Чаплина или вайнах с Instagram. А вполне себе плавно перемещаются как мы с вами в жизни. Всё потому что фреймрейт этих видео был увеличен до 60 fps - c пятнадцати в исходниках.
Как такое возможно? Нейросети в помощь, но что если я скажу, что сегодня каждый дома сможет сделать такое?
Сегодня мы расскажем вам как работает самый продвинутый алгоритм интерполяции кадров, разберемся в сути технологии и, главное, научимся делать это дома на своём компьютере!
Старые методы интерполяции
В конце прошлого года мы уже делали ролик про крутые алгоритмы Google, которые прокачивают видео. И самым интересным был алгоритм интерполяции кадров под названием DAIN.
Он позволяет увеличивать частоту кадров любого видоса в два и более раз практически без видимых искажений. Настоящая магия!
Но почему мы снова об это говорим? Да потому, что один прекрасный человек сделал для него простую и понятную графическую оболочку. И теперь каждый желающий сможет запустить нейросеть на своём компьютере.
Уже масса людей выложили свои эксперименты в сеть. Есть даже плейлист с такими видосами.

Но естественно, интерполяция кадров - не новая задача. Все, кто монтировал видео, помнят плагин Twixtor. Да и в каждом современном телевизоре, по умолчанию, включена это дурацкая функция плавного движения. Те, кто выключает её на всех телевизорах, даже в гостях, даже без спроса, даже вопреки воли хозяев - красавцы.
Все эти методы интерполяции основаны на вычислении оптического потока. Сравнив положения каждого пикселя на соседних кадрах можно вычислить вектор движения объекта.
Всё просто, когда движения в кадре мало. Например, какой-либо объект движется в одной плоскости на статичном кадре.
Но когда сцена динамичная - начинаются проблемы. Движется объект, движется фон. Компьютеру сложно понять, где начинается один объект и закачивается второй. Поэтому вместо замедления получается желе из пикселей.
Но как минимизировать такие ошибки? Ответ на этот вопрос может дать вот такое простое схематичное изображение работы алгоритма DAIN.
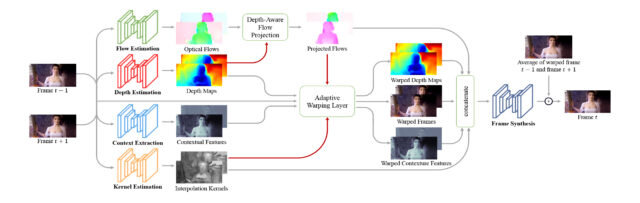
Итак, движемся по схеме слева направо. Для работы алгоритма требуется всего-навсего два соседних кадра в качестве исходных данных.
Потом в дело вступают 4 промежуточные нейросетки, каждая из которых генерирует свой тип данных.
1. Оптический поток
Первая нейронка, отвечает за вычисление, уже знакомого нам, оптического потока. Тут нет ничего особенно. А вот дальше начинаются инновации.
Вторая нейронка, на основе тех же кадров вычислят примерную карту глубины. Ага, вот девушка, она у нас на переднем плане. Вот её границы, а всё что сзади - фон.
2. Карта глубины
Получив дополнительные данные о глубине кадра, мы видим проекцию потока пикселей в трёхмерном пространстве. А это позволяет определить более четкие границы движения.
Это основная фишка алгоритма DAIN, который так и расшифровывается Depth-Aware Video Frame Interpolation, т.е. интерполяция кадров с учетом глубины.
В общем-то на этом этапе уже можно было остановиться и разогнать учёных по домам! Только этого нововведения хватило бы чтобы уделать все конкурирующие алгоритмы. Но они не остановились. Поэтому переходим к третьей нейронке!
3. Контекстные особенности
Часто бывает такое, что от кадра к кадру объект сильно меняется. Например, человек на одном кадре может стоять в профиль, а на втором анфас. И для интерполяции это становится большой проблемой. Как нарисовать промежуточное состояние?
Чтобы в таких случаях не получилось месива из пикселей нужна третья нейронка, которая изучает контекстные особенности объектов.
Условно говоря, она понимает, ага тут были какие-то контрастные области значит в промежуточном кадре надо бы их сохранить. И чёрт-побери сохраняет!
Вот пример: слева простая интерполяция, а справа с учётом контекста и карты глубины. Это наука, ребята! Погнали дальше.
4. Ядра интерполяции
Итак, у нас уже есть много информации по двум соседним кадрам: это оптический поток, карта глубины и контекстные особенности. Но нам надо как-то использовать эти данные для создания промежуточного состояния. То есть вычислить нечто среднее между ними.
И тут как раз вступает четвёртая нейронка. Она предполагает, где будут находиться объекты в промежуточном кадре и генерирует некий скелет на который натягиваются данные с предыдущих этапов.
5. Объединение
На этом подготовительная работа заканчивается и все данные попадают, куда бы вы думали? В пятую нейросеть, которая и генерирует промежуточный кадр!
Да схемка замороченная и очень ресурсоёмкая. Но! Результаты получаются феноменальные. Иногда просто невозможно отличить искусственный кадр от настоящего.
Инструкция
И тем удивительнее, что пользоваться этим чрезвычайно сложным алгоритмом проще простого. Что надо сделать?
Для начала скачаем приложение с сайта разработчика. Сразу оговорюсь, что пока доступна только версия под Windows, для нормальной работы которой будет необходима видеокарта NVIDIA с 4-8 Гб памяти. Приложение очень прожорливо до видеопамяти.
Устанавливаем приложение, а дальше выбираем, где лежит исходный файл и в какую папку сохранить результат. В общем-то и всё.
Единственный момент, если вы получаете сообщение о нехватке памяти, пробуйте нажать на галочку: Split frames into sections.
Либо можно задаунскейлить видео на выходе - галочка Downscale Video.
Вариантов применения такого алгоритма масса!
Можно повысить плавность любимого мультфильма или сделать крутейший слоу-моушн, а можно пойти дальше. Только представьте, если нейронный модуль телефона будет восстанавливать потерянные кадры в видеостримах. Или даже маскировать просадки FPS в играх!
Ну а если вы аниматор или делаете стоп-моушн - то эта штука вообще меняет правила игры.
И всё это доступно совершенно бесплатно! Для каждого желающего!
Правда автору приложения можно сделать поощрение, также известное как донат на Patreon.