
Однажды Упол Эхсан совершил тестовую поездку на самоуправляемом автомобиле Uber. Вместо того чтобы нервничать из-за пустого водительского сиденья, встревоженным пассажирам предлагалось смотреть на экран “пустышку”, который показывал автомобильную панораму дороги: опасности выделены оранжевым и красным цветом, безопасные зоны - синим.
Для Эхсана, который изучает, как люди взаимодействуют с ИИ в Технологическом институте Джорджии в Атланте, предназначенное сообщение было ясным: “Не пугайтесь - вот почему автомобиль делает то, что он делает.” Но что-то в этой странной уличной сцене скорее подчеркивало странность происходящего, чем успокаивало. Это заставило Эхсана задуматься: а что, если самоуправляемая машина действительно может объясниться?
Успех глубокого обучения обусловлен мастерством: лучшие нейронные сети настраиваются и адаптируются для создания самых лучших, а практические результаты опережают теоретическое понимание. В результате детали того, как работает обученная модель, обычно неизвестны. Мы привыкли думать о них как о черных ящиках.
Когда речь заходит о таких вещах, как игра в Го, перевод текста или выбор следующего шоу на Netflix для выпивки, мы не возражаем против этого,. Но если ИИ будет использоваться для принятия решений в правоохранительных органах, медицинской диагностике и беспилотных автомобилях, то нам нужно понять, как он достигает этих решений—и знать, когда они ошибочны.
Людям нужна власть, чтобы не соглашаться или отвергать автоматизированное решение, говорит Айрис Хаули, специалист по компьютерам из Уильямс-колледжа в Уильямстауне, штат Массачусетс. Без этого люди будут отталкиваться от технологии. “Вы можете видеть, как это происходит прямо сейчас с общественным откликом на системы распознавания лиц", - говорит она.
Эхсан является частью небольшой, но растущей группы исследователей, пытающихся сделать ИИ лучше в объяснении самих себя, чтобы помочь нам заглянуть внутрь черного ящика. Цель так называемого интерпретируемого или объяснимого ИИ состоит в том, чтобы помочь людям понять, какие особенности в данных нейронная сеть на самом деле изучает—и, таким образом, является ли полученная модель точной и беспристрастной.
Одним из решений является построение систем машинного обучения, которые показывают их работу: так называемый стеклянные ящики - в отличие от чёрного ящика. Модели стеклянных ящиков, как правило, представляют собой сильно упрощенные версии нейронной сети, в которых легче отслеживать, как различные части данных влияют на модель.
“В сообществе есть люди, которые выступают за использование моделей стеклянных ящиков в любой ситуации с высокими ставками”,-говорит Дженнифер Уортман Воан, специалист по компьютерам из Microsoft Research. Простые модели стеклянных ящиков могут работать так же, как и более сложные нейронные сети на определенных типах структурированных данных, таких как таблицы статистики. Для некоторых приложений это все, что вам нужно.
Но это зависит от области. Если мы хотим учиться на запутанных данных, таких как изображения или текст, мы застряли с глубокими и, следовательно, непрозрачными нейронными сетями. Способность этих сетей устанавливать значимые связи между очень большим числом несопоставимых объектов связана с их сложностью.
Даже здесь машинное обучение стеклянного ящика могло бы помочь. Одно из решений состоит в том, чтобы сделать два прохода по данным, обучая несовершенную модель стеклянного ящика в качестве шага отладки, чтобы выявить потенциальные ошибки, которые вы, возможно, захотите исправить. После очистки данных можно обучить более точную модель черного ящика.
Однако это сложный баланс. Слишком большая прозрачность может привести к информационной перегрузке. В исследовании 2018 года, посвященном тому, как пользователи, не являющиеся экспертами, взаимодействуют с инструментами машинного обучения, Воан обнаружил, что прозрачные модели на самом деле могут затруднить обнаружение и исправление ошибок модели.
Другой подход заключается в том, чтобы включить визуализации, которые показывают несколько ключевых свойств модели и ее базовых данных. Идея заключается в том, что вы можете увидеть серьезные проблемы с первого взгляда. Например, модель может слишком сильно полагаться на определенные характеристики, которые могут сигнализировать о смещении.
Эти инструменты визуализации оказались невероятно популярными за то короткое время, что они существуют. Но действительно ли они помогают? В первом исследовании такого рода, Воан и ее команда попытались выяснить - и выявили некоторые серьезные проблемы.
Команда использовала два популярных инструмента интерпретации, которые дают обзор модели с помощью диаграмм и графиков данных, выделяя то, что модель машинного обучения получила больше всего в обучении. Одиннадцать специалистов по ИИ были наняты из Microsoft, все разные по образованию, должностным ролям и опыту. Они приняли участие в имитационном взаимодействии с моделью машинного обучения, подготовленной на основе набора данных о национальном доходе, взятых из переписи населения США 1994 года. Эксперимент был разработан специально для того, чтобы имитировать то, как ученые используют инструменты интерпретации данных в тех задачах, с которыми они сталкиваются регулярно.
То, что обнаружила команда, было поразительно. Конечно, инструменты иногда помогали людям находить недостающие значения в данных. Но эта полезность была омрачена тенденцией к чрезмерному доверию и неправильному пониманию визуализаций. В некоторых случаях пользователи даже не могли описать, что показывают визуализации. Это привело к неверным предположениям о наборе данных, моделях и самих инструментах интерпретации. И это внушало ложную уверенность в инструментах, что делало участников более увлеченными развертыванием моделей, даже когда они чувствовали, что что-то было не совсем правильно. К сожалению, это было правдой даже тогда, когда вывод был изменен, чтобы показать объяснения, которые не имели смысла.
Чтобы подкрепить результаты своего небольшого исследования пользователей, исследователи провели онлайн-опрос около 200 специалистов по машинному обучению, набранных с помощью списков рассылки и социальных сетей. Они обнаружили такое же замешательство и неуместную уверенность.
Хуже того, многие участники были рады использовать визуализации для принятия решений о развертывании модели, несмотря на признание того, что они не понимали математику, стоящую за ними. "Было особенно удивительно видеть, как люди оправдывают странности в данных, создавая рассказы, которые объясняют их", - говорит Харманприт Каур из Мичиганского университета, соавтор исследования. "Уклон в сторону автоматизации был очень важным фактором, который мы не учли.”
Люди привыкли доверять компьютерам. Это не новое явление. Когда речь заходит об автоматизированных системах от автопилотов самолетов до средств проверки орфографии, исследования показали, что люди часто принимают решения, даже если они явно ошибочны. Но когда это происходит с инструментами, предназначенными для того, чтобы помочь нам избежать этого самого явления, у нас возникает еще большая проблема.
Что мы можем с этим сделать? Для некоторых проблема с первой волной интерпретируемого ИИ заключается в том, что в ней доминируют исследователи машинного обучения, большинство из которых являются опытными пользователями систем искусственного интеллекта. "Обитатели управляют приютом”,- Говорит Тим Миллер из Мельбурнского университета, который изучает, как люди используют системы искусственного интеллекта.
Вот что понял Эхсан, сидя на заднем сиденье "Убера" без водителя. Легче понять, что делает автоматизированная система—и увидеть, когда она совершает ошибку—если она дает основания для своих действий так, как это сделал бы человек. Эхсан и его коллега Марк Ридл разрабатывают систему машинного обучения, которая автоматически генерирует такие обоснования на естественном языке. В раннем прототипе пара взяла нейронную сеть, которая научилась играть в классическую видеоигру 1980-х годов Frogger и обучила ее предоставлять причину каждый раз, когда она делает ход.
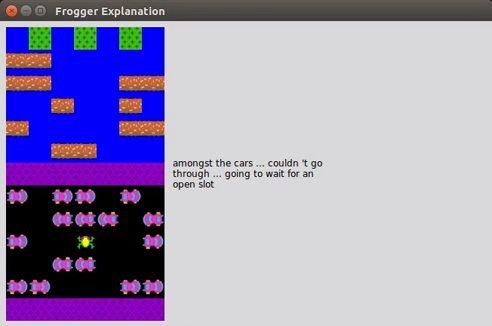
Для этого они показали системе множество примеров того, как люди играли в эту игру, говоря вслух о том, что они делали. Затем они взяли нейронную сеть для перевода между двумя естественными языками и адаптировали ее для перевода между действиями в игре и обоснованиями этих действий. Теперь, когда нейронная сеть видит действие в игре, она “переводит” его в объяснение. В результате получается играющий в лягушку ИИ, который говорит такие вещи, как “я двигаюсь влево, чтобы оставаться позади синего грузовика” каждый раз, когда он движется.
Работа Эхсана и Риделя - это только начало. Во-первых, неясно, всегда ли система машинного обучения сможет обеспечить обоснование своих действий. Возьмём ИИ Alpha Zero. Одной из самых поразительных особенностей программного обеспечения является его способность делать выигрышные ходы, которые большинство игроков-людей не подумали бы попробовать в тот момент в игре. Если AlphaZero сможет объяснить свои ходы, всегда ли они будут иметь смысл?
Причины помогают независимо от того, понимаем мы их или нет, говорит Эхсан: “цель человекоцентричного объяснимого ИИ -не просто заставить пользователя согласиться с тем, что говорит ИИ, но и спровоцировать рефлексию.” Ридл вспоминает просмотр прямой трансляции матча турнира между ИИ AlphaGo и чемпиона Корейского Го Ли Седола. Комментаторы говорили о том, что видел и думал AlphaGo. " AlphaGo так не работал", - говорит Ридл. "Но я чувствовал, что комментарий был необходим для понимания того, что происходит."
Эта новая волна исследователей объяснимого ИИ сходится в том, что если системы ИИ будут использоваться большим количеством людей, то эти люди должны быть частью дизайна с самого начала—и разные люди нуждаются в различных объяснениях. (Это подтверждается новым исследованием Хоули и ее коллег, в котором они показывают, что способность людей понимать интерактивную или статическую визуализацию зависит от их уровня образования.) Подумайте о диагностирующем рак ИИ, говорит Эхсан. Вы бы хотели, чтобы объяснение, которое он дает онкологу, сильно отличалось от объяснения, которое он дает пациенту.
В конечном счете, мы хотим, чтобы ИИ объяснял себя не только ученым и врачам, но и полицейским, использующим технологию распознавания лиц, учителям, использующим аналитическое программное обеспечение в своих классах, студентам, пытающимся разобраться в своих социальных сетях, и всем, кто сидит на заднем сиденье самоуправляемого автомобиля. “Мы всегда знали, что люди чрезмерно доверяют технологиям, и это особенно верно в отношении систем искусственного интеллекта”,-говорит Ридл. “Чем больше вы говорите, что он умен, тем больше людей убеждены, что он умнее, чем они сами.”
Объяснения, которые каждый может понять, должны помочь лопнуть этому пузырю.