Что такое РНН?
Рекуррентная нейронная сеть - это тип нейронной сети глубокого обучения, которая запоминает входную последовательность, сохраняет ее в состояниях памяти / состояниях ячеек и предсказывает будущие слова / предложения.
Почему РНН?
RNN хорошо работают с входными данными в виде последовательностей. В качестве примера рассмотрим: «Мне нравится есть мороженое. Мой фаворит - шоколад ____ ».
Для людей очевидно, что заполнить пробел словом «мороженое», но машина должна понимать контекст и запоминать предыдущие слова в предложении, чтобы предсказать следующее слово. Вот где полезны RNN.
Распознавание речи (Google Voice Search), машинный перевод (Google Translate), прогнозирование временных рядов, прогнозирование продаж и т. Д.
Архитектура и работа РНН
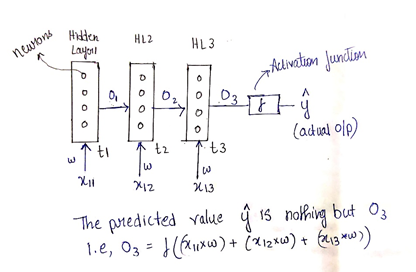
Рассмотрим x11, x12, x13 как входы, а O1, O2, O3 как выходы скрытых слоев 1, 2 и 3 соответственно. Входные данные отправляются в сеть через разные интервалы времени, поэтому предположим, что x11 отправляется на скрытый слой 1 в момент времени t1, x12 @ t2 и x13 @ t3.
Кроме того, предположим, что веса при прямом распространении одинаковы.
Выходной сигнал O3 зависит от O2, который, в свою очередь, зависит от O1, как мы видим ниже.
O1 = f (x11 * w) → где w - вес, а f - функция активации.
O2 = f (O1 + x12 * w)
O3 = f (O2 + x13 * w)
Наконец, выход O3 - это фактический выход, обозначенный ŷ
Теперь функция потерь будет вычисляться как (y - ŷ) ^ 2. Цель состоит в том, чтобы уменьшить функцию потерь до точки, в которой мы получаем y = ŷ, чтобы достичь глобального минимума, который устанавливает соответствующий вес, который должен быть добавлен в сеть. Это достигается при обратном распространении с помощью оптимизаторов для корректировки весов.
Пример применения цепного правила дифференцирования при обратном распространении:

Двунаправленный RNN
Пример: «Я ____ голоден, и сегодня я могу съесть 3 большие пиццы за один раз». Итак, забудьте о машинах, люди не могут предсказать подходящие слова для пробела, не прочитав все предложение. В этом сценарии мы используем двунаправленные рекуррентные нейронные сети, которые не только предоставляют информацию из прошлого, но и содержат информацию из будущего.
Концепция двунаправленной RNN заключается в соединении двух скрытых слоев, которые имеют одинаковый ввод и производят вывод. Изобретение состоит в том, что выходные данные, которые мы получаем для конкретного интересующего скрытого слоя, будут содержать информацию из прошлого, а также из будущего. См. Архитектуру ниже
Чтобы было понятно, для прогнозирования выхода ŷ13 у нас есть O1, O2 (от прямого направления), а также O | 3 (от обратного направления). Недостаток Bi-RNN в том, что он медленный.
Недостатки RNN -
1. Проблема исчезающего градиента - это происходит, когда мы используем определенные функции активации.Таким образом, во время обратного распространения обновление веса будет очень маленьким от слоя к слою, и в какой-то момент новый вес, который нужно добавить, станет равным старому весу, поэтому изменений нет, и обучение сети затруднено.
2. Проблема взрывающегося градиента. В этом случае обновление веса настолько велико, что сеть не может учиться на тренировочных данных, поэтому глобальные минимумы никогда не могут быть достигнуты.
Следовательно, LSTM (Long Short-Term Memory) и GRU (Gated Recurrent Units) служат лучше.
LSTM - долгая краткосрочная память
· LSTM решают проблему исчезающего градиента.
· LSTM имеют 2 состояния, то есть скрытое состояние и состояния ячеек, как предполагается для RNN, которые имеют только скрытое состояние.
· LSTM забывают некоторую информацию, которая не важна при изменении контекста, таким образом, работая очень эффективно даже для длинных предложений, чего нельзя сказать о RNN.
Архитектура и работа LSTM Основными компонентами LSTM являются:
1. Ячейка памяти
2. Входной слой
3. Forget Gate
4. Выходной слой
Ниже представлена структура LSTM. Давайте разберемся в операции
1. Forget Gate
Здесь входные данные ht-1 и xt передаются в функцию активации сигмоида, которая выводит значения от 0 до 1. 0 означает полностью забыть, а 1 означает полностью сохранить информацию. Мы используем сигмовидную функцию.
Примечание: bf - это смещение, а Wf - общий вес двух входов.
2. Входной слой
Этот этап нужен, чтобы выявить новую информацию и добавить к состоянию ячейки. Это делается в 2 этапа.
Шаг 1: Сигмоидный слой выводит значение от 0 до 1 на основе входных данных ht-1 и xt. как показано на диаграмме выше. В то же время эти входные данные будут переданы на слой tanh, который выводит значения от -1 до 1 и создает векторы для входных данных.
Шаг 2: умножаем выходной сигнал сигмовидного слоя и слоя tanh.
Теперь состояние ячейки обновляется с Ct-1 (предыдущий вывод ячейки LSTM) до Ct (текущий вывод ячейки LSTM), как мы видим выше.
3.Выходной слой
Сначала состояние ячейки передается через функцию tanh, и одновременно мы отправляем входные данные ht-1 и xt на уровень сигмоидной функции. Затем происходит умножение, и ht является выходом этой ячейки памяти и передается в следующую ячейку.
Закрытый рекуррентный блок
Для более быстрых вычислений и меньшего потребления памяти используются GRUs. LSTM работают лучше, когда точность является ключевым моментом. У GRUs нет состояний ячеек, только скрытое состояние.
Архитектура и работа GRU
Основными компонентами GPU являются:
1. Слой обновления (z)
2. Слой сброса (RT)
Схема ниже представляет GPU
1.Слой обновления - объем информации, который необходимо передать вперед
Где W (z) - это вес, связанный с xt, U (z) - это вес, связанный с вводом из предыдущего состояния, который равен ht-1, а σ - функция активации сигмоида.
Выходной zt будет между 0 и 1 в зависимости от того, какая информация будет передана.
2. Reset Gate - решает, какое количество информации нужно забыть.
Где W (r) - это вес, связанный с xt, U (r) - вес, связанный с вводом из предыдущего состояния, который равен ht-1, а σ - функция активации сигмоида.
Выходное значение rt будет между 0 и 1, в зависимости от того, какая информация будет забыта.
Теперь важным шагом является добавление в сеть компонента памяти, называемого слоем сброса. Этот слой сброса извлекает важную информацию или суть и присваивает значение = 1, а остальным всем предложениям будет присвоено значение = 0 Математически мы вычисляем, как показано ниже,
Наконец, мы используем следующую формулу
Используя эту формулу, мы вычисляем текущее состояние ht, которое будет передаваться в следующие ячейки.
Последовательность для последовательного обучения
Идея последовательного обучения состоит в том, что входные данные, полученные на одном языке, преобразуются в другой язык. Пример: Английский → сомалийский.
Типы последовательного обучения
1. Последовательность в последовательность - Выходы равны количеству входов.
2. Последовательность в вектор - один выход дается для 'n' входов.
3. Вектор в последовательность - для 1 входа получено 'n' выходов.
4. Из вектора в вектор - для одного входа принимается один выходной сигнал.
На диаграмме ниже представлена архитектура четырех вышеуказанных методов обучения.
Кодеры - Декодеры / Модель нейронного машинного перевода Сутскевер
Не всегда входная и выходная последовательность имеют одинаковую длину. Пример -
В приведенном выше переводе мы видим, что в английском языке 3 символа, а в сомали - 2 символа. В этом сценарии используются кодеры и декодеры.
Архитектура и работа Кодерров-декодеров
Кодеры - это входные сети, которые состоят из ячеек LSTM или GRU, а декодеры - это выходные сети, которые также состоят из ячеек LSTM или GRU.
Кодировщик - мы вводим слова A, B, C в сеть кодировщика и получаем вектор контекста «w», который суммирует информацию о входах.
Примечание. Когда сеть достигает <EOS>, процесс останавливается.
Декодер - вектор контекста «w» отправляется в сеть декодера, как мы видим на диаграмме выше. Для каждого входа в сеть декодера мы получаем выход (X, Y, Z).
Окончательный выходной сигнал сети декодера сравнивается с входной последовательностью и вычисляется функция потерь. Эта функция потерь сводится к точке фактический результат = прогнозируемый результат с использованием оптимизаторов в обратном распространении.
Недостаток кодировщика и декодера - вектор контекста суммирует всю входную последовательность, но не все слова во входной последовательности будут полезны для включения в сводку. Это преодолевается с помощью модели на основе внимания.
Attention Models.
Концепция. Представьте, что вы слушаете речь, и в конце речи вы не запомните каждое слово, произнесенное говорящим, но вы сохраните суть или краткое содержание речи. Это концепция Attention models( моделей внимания).
Архитектура и модель работы Attention Models
У нас есть нейронная сеть между кодером и декодером. Выход нейронной сети будет входом в декодер. На этом этапе мы также должны понимать, что выходом нейронной сети будет тот, который имеет максимальное внимание или фокус, или слово, которое важно для предсказания среди полученных входных данных.
Чтобы узнать о сложных концепциях, обратитесь к замечательным статьям, указанным ниже:
Transformers — http://jalammar.github.io/illustrated-transformer/
BERT — http://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time/
GTP 3 — http://jalammar.github.io/how-gpt3-works-visualizations-animations/
Спасибо за прочтение!