Language Interpretability Tool (LIT) - это интерфейс и инструментарий на основе браузера для интерпретируемости моделей. Это платформа с открытым исходным кодом для визуализации и понимания моделей НЛП, разработанная исследовательской группой Google.
LIT поддерживает такие модели, как регрессия, классификация, seq2seq, языковое моделирование и структурированные прогнозы.
Он не зависит от платформы и совместим с TensorFlow, PyTorch и другими.
Компоненты LIT переносимы и могут легко использоваться в записной книжке Jupyter или автономном скрипте.
Installation/Running LIT
Обратитесь к руководству по дальнейшей установке и запуску демонстрационной версии, как настроить и запустить LIT на локальном сервере. LIT - Руководство по установке (pair-code.github.io)
Как использовать LIT для анализа различных типов моделей?
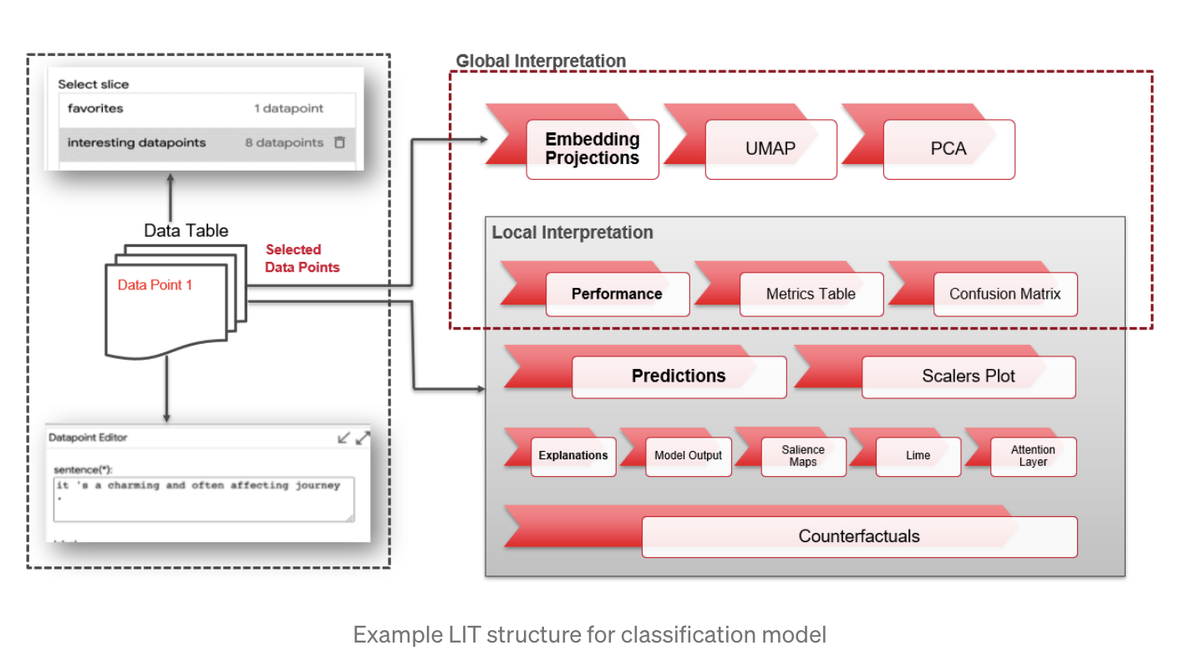
Основные компоненты LIT
Общий макет: LIT состоит из внутреннего интерфейса Python и внешнего интерфейса TypeScript.
Основные компоненты пользовательского интерфейса: -
Глобальные настройки: - для выбора нескольких моделей, выбора набора данных и конфигурации макета.
Строка главного меню: - для изменения цвета, выбора срезов, сравнения наборов данных.
Секция верхнего модуля: - для выбора данных
Нижняя часть модуля: для локального объяснения, интерпретируемости, создания новых точек данных.
DataTable / Datapoint Selections-LIT отображает загруженный набор данных и результаты его модели по набору выбранных моделей. Пользователи могут погрузиться в подробные результаты, выбрав точки данных из набора данных.
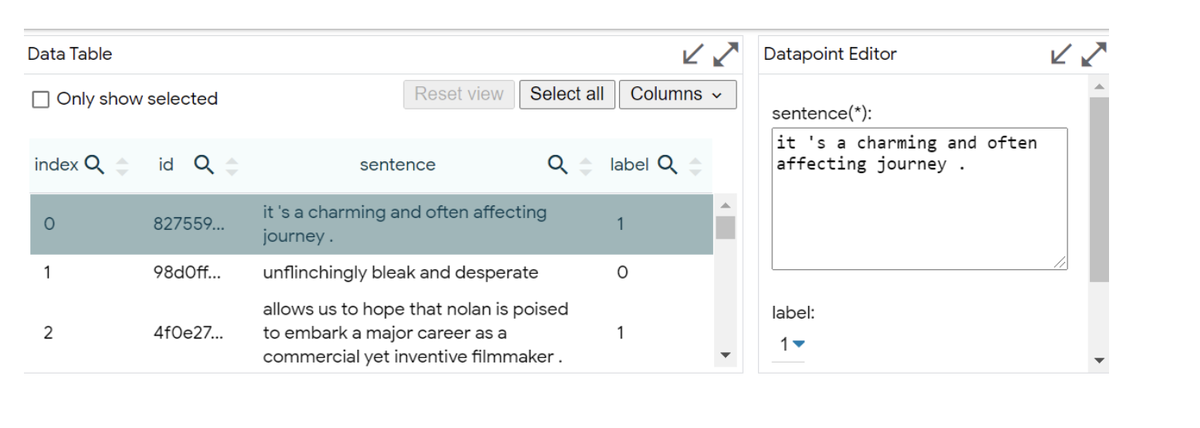
Редактор точек данных - с помощью редактора точек данных мы можем редактировать выбранную точку данных, если она выбрана. Также можно создать новую точку данных с помощью кнопки «Создать новую точку данных». Любое редактирование существующей точки данных должно быть сохранено как новая точка данных для исследования, чтобы точки данных оставались неизменными для простоты использования.
Редактор срезов - вы можете сохранить выбранные точки данных / точки данных в компоненте редактора срезов для сравнения с другими моделями / точками данных, это как закладка, которую вы можете повторно посетить в будущем, чтобы сравнить результаты.
Модули глобального объяснения проблемы классификации.
В LIT есть разные типы модулей для объяснения модели.
Модули будут автоматически отображаться, если они применимы к текущей модели и набору данных; например, модуль, показанный ниже, относится только к результатам классификации.
Встраиваемая проекция - Встраивающий проектор будет отображать все точки данных в виде их встраиваний, спроецированных до трех измерений. Это полезно для изучения и понимания кластеров точек данных.
LIT предоставляет 2 типа встраиваемых проекций: -
UMAP. Как и t-SNE, UMAP - это средство уменьшения размерности, специально разработанное для визуализации сложных данных в малых размерах (2D или 3D). По мере увеличения количества точек данных UMAP становится более эффективным по времени по сравнению с TSNE.
PCA - реализован для уменьшения размерности встраивания слов. Короче говоря, это метод извлечения признаков - он объединяет переменные, а затем отбрасывает наименее важные переменные, сохраняя при этом ценные части переменных.
Примечание. Цвет точек внедрения можно изменить либо с помощью предсказанного класса / исходного класса, либо с помощью меток в строке главного меню.
Вкладка производительности
Таблица показателей - показывает такие показатели, как точность (для классификаторов), ошибка (для задач регрессии) и оценка BLEU (для задач перевода) для выбранной модели.
Модуль Metrics показывает показатели модели не только для всего набора данных, но и для текущего набора точек данных (выбранных из таблицы данных или из среза).
Матрица неточностей - матрица неточностей, отображаемая для всех данных из набора данных (или текущей выбранной точки данных) только для модели классификации.
Вкладка "Прогнозы"
Результаты классификации: -Он покажет результат модели на выбранной точке данных.
Скаляры: он покажет общий прогнозируемый результат и выбранные вероятности точек данных.
Локальные модули объяснения для задачи классификации
Карты значимости: карты значимости показывают влияние различных частей входных характеристик на прогноз модели при первичном выборе.
Фон каждого фрагмента текста окрашен в зависимости от его значимости в прогнозе, и при наведении курсора на любой фрагмент будет отображаться точное значение, рассчитанное для этого фрагмента.
Градиентная норма Важность - он обрабатывает градиенты токенов и токены, возвращаемые моделью, и выдает список оценок для каждого токена.
Важность точки градиента - для этого требуется ввод и соответствующий вывод встраивания токена, а также поле метки Target, чтобы привязать цель градиента к тому же классу, что и ввод и соответствующий вывод.
Интегрированные градиенты - значения атрибута функции вычисляются путем взятия интеграла градиентов по прямому пути от базовой линии до анализируемого входа. Он также требует того же ввода, что и градиентная точка.
Лаймовая заметность: он проверяет каждое слово в зависимости от того, насколько оно положительно или отрицательно повлияло на предсказание.
См. Ссылку ниже для более подробного объяснения и математики расчета значимости - Аксиоматическая атрибуция для глубоких сетей https://arxiv.org/pdf/1703.01365.pdf (arxiv.org)
Противодействие: создание точек данных путем ручного редактирования или автоматического создания текста из существующих данных для динамического создания и оценки новых примеров.
Скремблер: перемешивает слова в тексте случайным образом.
Word Replacer: предоставляет текстовое поле для определения разделенного запятыми набора замен для выполнения (например, «отлично -> ужасно, привет -> привет»).
Заменитель слов также поддерживает несколько целей для каждого слова с «|» разделитель. Например, «отлично -> ужасно | плохой »даст два результата, в которых« отлично »заменено на« ужасно »и« плохо ».
Противодействующее объяснение: это похоже на карту значимости, но влияние здесь рассчитывается путем просмотра результатов модели на этой точке данных по сравнению с результатами для остальных выбранных точек данных.
Примечание. Вышеуказанные компоненты интерпретируемости модели относятся только к задаче классификации.
Вывод:
-Простота использования -Пользователь может переключаться между визуализацией и анализом, чтобы проверить гипотезу и подтвердить эту гипотезу по точке данных.
-Генерация динамических данных-Новые точки данных могут быть добавлены с помощью редактора создания контрфактов / точек данных, и их влияние на модель может быть визуализировано бок о бок.
-Multi Model Comparison -Это позволяет сравнивать два похожих типа моделей или две точки данных для визуализации одновременно. Загружая более одной модели в элементы управления глобальными настройками, LIT может сравнивать несколько моделей.
-Объясните поведение модели - например, Вопросы типа «Что произойдет, если я изменю в тексте такие вещи, как стиль текста или глагольное время». Как это изменит прогноз? На каких примерах моя модель плохо работает? Изучены ли лингвистические знания или игнорируются?
-Configurable-Существует краткий обзор того, как запускать LIT с вашими собственными моделями и наборами данных. LIT легко расширить с помощью новых компонентов интерпретируемости, генераторов и многого другого как на интерфейсе, так и на сервере. Для получения дополнительных сведений см. Документацию LIT в репозитории кода.
статья: https://arxiv.org/pdf/2008.05122v1.pdf
code: https://github.com/pair-code/lit



















