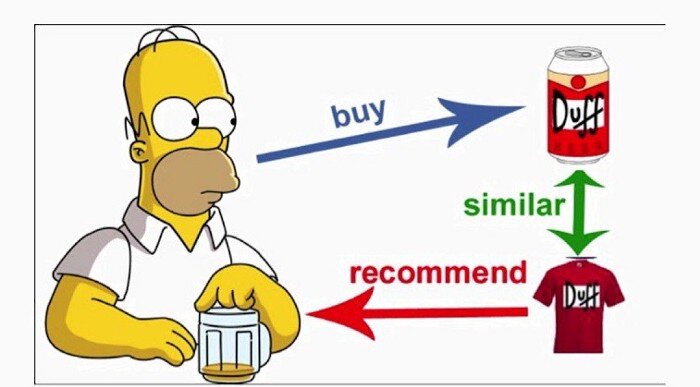
Система рекомендаций или система рекомендаций (иногда заменяющая «систему» синонимом, таким как платформа или движок), является подклассом системы фильтрации информации, которая нужна, чтобы предсказать «рейтинг» или «предпочтение», которое пользователь поставит объекту тому или иному объекту. В основном они используются в коммерческих приложениях.
Рекомендательные системы используются в различных областях и наиболее широко известны как генераторы списков воспроизведения для видео и музыкальных сервисов, рекомендатели продуктов для интернет-магазинов или рекомендатели контента для платформ социальных сетей и открытого веб-контента. Эти системы могут работать, используя данные на вход, например музыку, или несколько входов внутри и между платформами, такими как новости, книги и поисковые запросы. Существуют также популярные рекомендательные системы для определенных тем, таких как рестораны и онлайн-знакомства. Также существуют рекомендательные системы для изучения научных статей, экспертов , сотрудников и финансовых служб.
(https://en.wikipedia.org/wiki/Recommender_system)
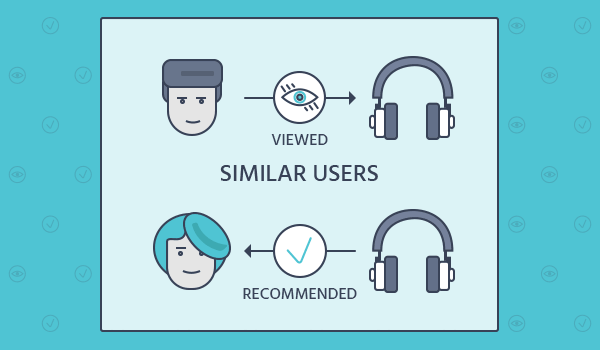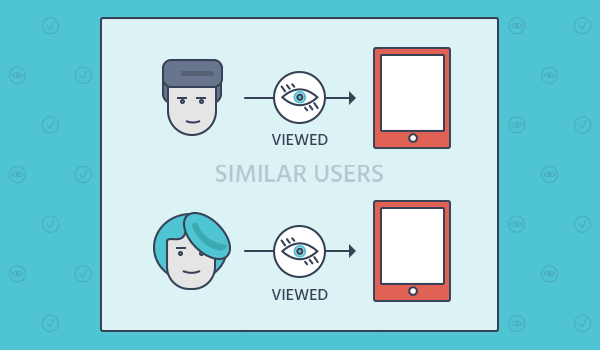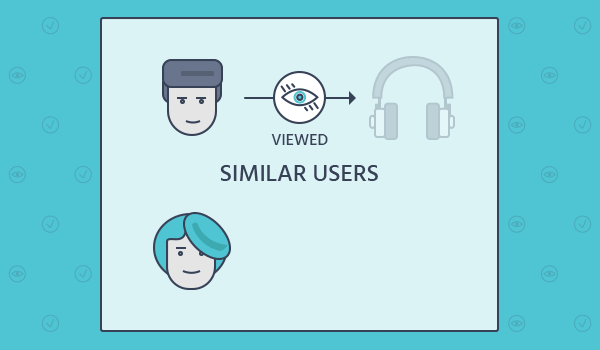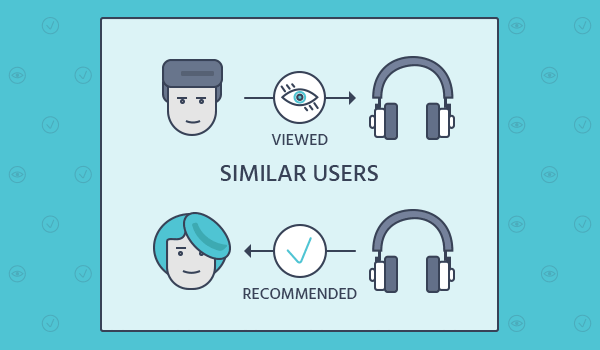
Совместная фильтрация
Ключевым преимуществом подхода совместной фильтрации является то, что он не полагается на контент, анализируемый машиной, и, следовательно, он способен точно рекомендовать сложные элементы, такие как фильмы, без необходимости «понимания» самого элемента. Многие алгоритмы использовались для измерения сходства предпочтений пользователей или элементов в рекомендательных системах. Например, метод k-ближайших соседей (k-NN) и корреляция Пирсона.
При построении модели на основе поведения пользователя часто проводится различие между явными и неявными формами сбора данных.
Примеры явного сбора данных включают следующее:
- Опрос пользователя оценить элемент по скользящей шкале.
- Собирать информацию о поиске пользователя .
- Просить пользователя оценить коллекцию элементов от избранных до наименее любимых.
- Представить пользователю два предмета и попросить его выбрать лучший из них.
- Попросить пользователя создать список элементов, которые ему нравятся (см. Классификацию Роккио или другие подобные методы).
Косинусное сходство
Используя Keras и CNN vgg16, мы собираемся разработать алгоритм, чтобы рекомендовать аналогичные продукты;
# imports
from keras.applications import vgg16
from keras.preprocessing.image import load_img,img_to_array
from keras.models import Model
from keras.applications.imagenet_utils import preprocess_input
from PIL import Image
import os
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
import pandas as pd# parameters setup
imgs_path = "../input/style/"
imgs_model_width, imgs_model_height = 224, 224
nb_closest_images = 5 # number of most similar images to retrieve
1. загрузка предварительно обученной модели VGG из Keras
Keras содержит несколько предварительно обученных моделей, которые можно очень легко загрузить.
Для нашей рекомендательной системы, основанной на визуальном сходстве, нам необходимо загрузить сверточную нейронную сеть (CNN), которая сможет интерпретировать содержимое изображения.
В этом примере мы загрузим модель VGG16, обученную в imagenet, большой базе данных помеченных изображений.
Если мы возьмем всю модель целиком, мы получим вывод, содержащий вероятности принадлежности к определенным классам, но это не то, что мы хотим.
Мы хотим получить всю информацию, которую модель смогла получить на изображениях.
Для этого мы должны удалить последние слои CNN, которые используются для предсказаний классов.
files = [imgs_path + x for x in os.listdir(imgs_path) if “jpg” in x]print(“number of images:”,len(files))
# load the model
vgg_model = vgg16.VGG16(weights='imagenet')
# remove the last layers in order to get features instead of predictions
feat_extractor = Model(inputs=vgg_model.input, outputs=vgg_model.get_layer("fc2").output)
# print the layers of the CNN
feat_extractor.summary()# compute cosine similarities between imagescosSimilarities = cosine_similarity(imgs_features)# store the results into a pandas dataframecos_similarities_df = pd.DataFrame(cosSimilarities, columns=files, index=files)
cos_similarities_df.head()def retrieve_most_similar_products(given_img):print("--------------------------------------------------------")
print("original product:")original = load_img(given_img, target_size=(imgs_model_width, imgs_model_height))
plt.imshow(original)
plt.show()print("-------------------------------------------------------")
print("most similar products:")closest_imgs = cos_similarities_df[given_img].sort_values(ascending=False)[1:nb_closest_images+1].index
closest_imgs_scores = cos_similarities_df[given_img].sort_values(ascending=False)[1:nb_closest_images+1]for i in range(0,len(closest_imgs)):
original = load_img(closest_imgs[i], target_size=(imgs_model_width, imgs_model_height))
plt.imshow(original)
plt.show()
print("similarity score : ",closest_imgs_scores[i])