Партнёрский материал
В начале сентября 2020 г. компания NVIDIA впервые представила графические карты семейства GeForce RTX 3000 на базе архитектуры RTX второго поколения — Ampere. NVIDIA нарушила свою традицию, когда новые поколения карт продавались дороже своих предшественников, а это значит, что стоимость тренировки модели оставалась примерно на одном уровне.
В этот раз NVIDIA установила стоимость новых и более популярных карт на уровне стоимости карт предыдущего поколения в момент начала их продаж. Для разработчиков ИИ-приложений это событие стало действительно важным — по сути, карты RTX 3000 открывают доступ к производительности, сравнимой с Titan RTX, но с гораздо более приятным ценником. Теперь у разработчиков data science появилась возможность тренировать модели быстрее без увеличения затрат.

Флагманские карты новой серии GeForce RTX 3090 получили 10 496 ядер NVIDIA CUDA с тактовой частотой 1,44 ГГц (ускорение до 1,71 ГГц), 328 тензорных ядер третьего поколения и 24 Гбайт 384-битной графической памяти GDDR6X. Еще более доступная по цене GeForce RTX 3080 обладает 8 704 ядрами CUDA с теми же тактовыми частотами, 272 тензорными ядрами и 10 Гбайт 320-битной памяти GDDR6X. Несмотря на дефицит новых видеокарт (NVIDIA даже была вынуждена приносить извинения рынку за образовавшуюся нехватку карт на старте продаж), уже в начале октября GPU-серверы появились в линейке продуктов у хостинг-провайдеров.
Нидерландский провайдер HOSTKEY одним из первых в Европе протестировал и представил GPU-серверы на базе новых карт GIGABYTE RTX3090/3080 TURBO. С 26 октября конфигурации на базе RTX 3090/Xeon E-2288G и RTX 3080/AMD Ryzen 9 3900X стали доступны всем клиентам HOSTKEY в дата-центрах в Нидерландах и Москве.
NVIDIA RTX 3000: золотая середина?
Карты RTX3090/3080 позиционируются производителем как более производительное решение на замену карт серии RTX 2000 с предыдущей архитектурой Turing. И, конечно, серверы с новыми картами значительно производительнее, чем доступные «народные» GPU-серверы на базе видеокарт GTX1080 (Ti), которые тоже пригодны для работы с нейросетями и прочими задачами машинного обучения (хотя и с оговорками), но при этом доступны по совсем уж «демократичным» ценам.
«Над» серией NVIDIA RTX 3000 располагаются все мощные решения на базе карт класса A100/A40 (Ampere) с тензорными ядрами третьего поколения числом до 432, Titan RTX/T4 (Turing) с тензорными ядрами второго поколения в количестве до 576, и V100 (Volta) с 640 тензорными ядрами первого поколения. Ценники на эти мощные карты, равно как и на аренду GPU-серверов с ними, значительно превышают предложения с RTX 3000, поэтому особенно интересно оценить на практике разрыв в производительности в задачах AI/ML.
Практические исследования
Face Reenactment
Одной из рабочих задач для оперативного тестирования GPU-серверов на основе новых карт RTX 3090 и RTX 3080 был выбран процесс Face Reenactment для нейросети U-Net+ResNet с пространственно-адаптивной нормализацией SPADE и patch-дискриминатором. В качестве фреймворка использовался Facebook PyTorch версии 1.6 со встроенным автоматическим режимом Automated mixed precision (AMP), а также режимом флага torch.backend.cudnn.benchmark = True.
Для сравнения этот же тест был запущен на GPU-сервере с картой GeForce GTX 1080 Ti, но уже без AMP, который только замедлил бы процесс, а также на машине с картой Titan RTX. Для чистоты эксперимента следует упомянуть, что в этом тестировании с картой Titan RTX использовалась система на процессоре Intel Core i9-10920X, в то время как остальные GPU-серверы со всеми остальными картами работали на Xeon E-2288G.
Безусловно, сравнение при классификации важно производить на одинаковых процессорах, поскольку именно они зачастую являются «бутылочным горлышком», ограничивающим производительность системы. Так что доля скептицизма в отношении погрешности результатов тестирования GPU в данном случае вполне уместна. Мы получили следующие результаты:
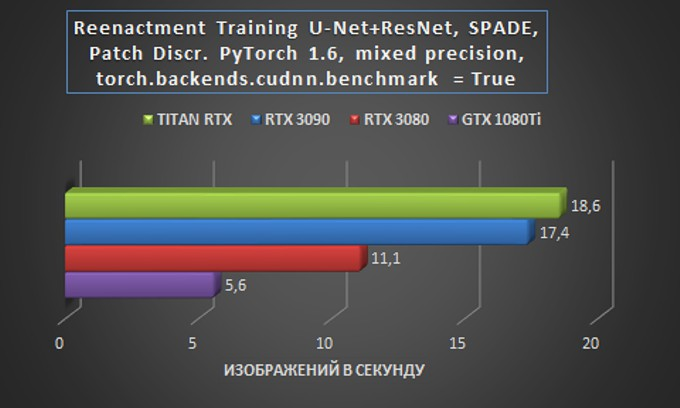
Минимальная разница между результатами RTX 3090 и Titan RTX выглядит особенно впечатляюще, если вспомнить об огромном ценовом разрыве между этими решениями. В следующем тестировании RTX 3090 заслуживает, как минимум, полноценного глубокого сравнения с GPU-сервером на базе одной и двух карт RTX 2080. Отставание RTX 3080 от RTX 3090 вполне объяснимо значительной разницей в объеме памяти — 10 Гбайт против 24 ГБ, на соответственное двух- и трехкратное отставание GTX 1080 Ti также наложила свой отпечаток разница в архитектурах.
Если же посмотреть на эти результаты с практической точки зрения, то есть в плане оценки финансовых расходов на обучение модели в случае аренды GPU-сервера, то чаша весов окончательно склоняется в пользу выбора системы с RTX 3090 — именно эта карта обеспечит наилучший использование бюджета как при недельном, так и при месячном тарифных планах.
Обучение GAN
Во второй тестовой задаче, которая заключалась в тренировке генеративно-состязательной нейронной сети (Generative Adversarial Network, GAN) с пакетом PyTorch, было интересно не только сравнить производительность карт различных поколений, но также отследить влияние состояния флага torch.backends.cudnn.benchmark на финальные результаты. При обучении GAN-архитектуры включение флага в положение True дает прирост производительности, но при этом может пострадать воспроизводимость результатов (Reproducibility).
Полученные результаты еще раз доказывают, что карта RTX 3090 с ее 24 Гбайт памяти GDDR6X представляет собой лучший выбор для решения тяжелых задач по обработке изображений. Как по производительности (выигрыш на 65% по сравнению с RTX 3080), так и по затратам на тренинг модели при аренде GPU-сервера в пересчёте на стоимость тренировки.
RTX 3080 значительно обошла по производительности GTX 1080 Ti, причём с любой установкой флага и несмотря на примерный паритет объема памяти. Однако следует помнить, что при обучении GAN-архитектуры включение флага torch.backends.cudnn.benchmark=True дает прирост производительности, но при этом может пострадать воспроизводимость результатов. причем,
Так что аренда более доступного GPU-сервера с картами GTX 1080 Ti при некоторых условиях может быть вполне разумным выбором — или, как минимум, сравнима по бюджету на тренинги моделей с RTX 3080. К сожалению, на прогон этой сетки через Titan RTX времени уже не оставалось, но с большой вероятностью картина в этом случае осталась бы аналогичной.
Обучение и инференс в vision-задачах
В следующей тестовой задаче по тренингу сетей в vision-задачах производительность видеокарт RTX 3090 и RTX 3080 сравнивалась с возможностями мощнейшего (и все еще очень дорогого) «ветерана» Tesla V100 с 16 Гбайт памяти HBM2. Было протестировано пять классификационных моделей для обнаружения объектов со следующими тренинговыми установками: model forward + mean (no loss) + backward.
Тестовые задания запускались с применением последней версии фреймворка NVIDIA PyTorch (20.09-py3 от 24 октября). К сожалению, эта версия не собрана под архитектуру Ampere, поэтому для полноценной поддержки видеокарт RTX 3000 пришлось использовать PyTorch версии nightly build, а именно 1.8.0.dev20201017+cu110. У серии RTX 3000 также есть некоторые проблемы с torch.jit, но вопрос полностью снимается при сборке PyTorch под конкретную карту. Во всех тестах PyTorch использовался с автоматическим скриптом Mixed Precision, с включенным по умолчанию флагом torch.backend.cudnn.benchmark = True.
Стоит упомянуть некоторые нюансы этого сравнения. В частности, была задействована не самая быстрая V100, которая работала внутри виртуальной машины. Из-за этого могли возникнуть некоторые потери, которые, вполне возможно, можно было бы оптимизировать при лучшей настройке. Помимо этого, в процессе тестирования не была задействована вся доступная VRAM, что позволило бы придать расчетам дополнительное ускорение.
Classification Training
Задача обучения сложных моделей нейросетей является профильным заданием для GPU-серверов на картах NVIDIA, позволяя порой на порядки сократить время тренировки алгоритмов глубокого обучения.
В условиях запуска задачи для получения результатов бенчмарка пересылка обнаружения объектов производилась без NMS, а пересылка для обучения не включала сопоставления целей. Иными словами, на практике скорость обучения с большой вероятностью замедлится на 10-20%, а скорость вывода снизится примерно на 20-30%.
Classification Inference
В данном случае инференс — это процесс получения предсказаний посредством прогона изображений через заранее обученную нейронную сеть, который вполне подходит для развертывания на удаленном GPU-сервере.
В целом можно говорить о том, что в заданиях тренировки и инференса сетей в Vision-задачах карта RTX 3090 медленнее Tesla V100 в среднем всего на 15-20%, и это очень впечатляюще — особенно с учетом разницы в цене.
Показателен и тот факт, что отставание RTX 3080 от RTX 3090 относительно невелико — по крайней мере, значительно меньше, чем при выполнении других задач. На практике это означает, что даже со сравнительно небольшим бюджетом, выделенным на аренду GPU-сервера на базе RTX 3080, можно добиться достаточно высокой производительности лишь с небольшим увеличением затрат времени на обработку данных.
Detection Training
Тестирование RetinNet c ResNet50FPN для обнаружения объектов производилось с указанными выше параметрами PyTorch (20.09-py3 от 24 октября), с флагом torch.backend.cudnn.benchmark=True и с тренинговыми установками model forward + mean (no loss) + backward.
Detection Inference
Здесь отставание карт серии RTX30 уже минимально, что говорит о несомненных преимуществах новой архитектуры Ampere для решения подобных задач. Карта RTX 3090 показала себя просто великолепно.
Сравнительно небольшое отставание бюджетной карты говорит о том, что благодаря отличному соотношению цена/возможности RTX 3080 может стать желанным выбором для решения задач прототипирования с экономичным бюджетом. По завершению создания прототипа модель можно масштабировать, развернув, например, на GPU-серверах с картами RTX 3090.
Заключение
По итогам тестирования новых графических решений семейства GeForce RTX 3000 можно с уверенностью утверждать, что компания NVIDIA блестяще справилась с задачей выпуска доступных видеокарт с тензорными ядрами, достаточно производительными для быстрых ИИ-вычислений. В некоторых задачах обучения сетей, таких как работа с разреженными сетями (Sparse network), преимущества архитектуры Ampere над поколением RTX20 позволяют добиться ускорения процесса в два раза.
Преимущества использования GPU-серверов с картами GeForce RTX 3090 особенно очевидны в задачах, где обучение моделей связано с повышенными требованиями к объему памяти — при анализе медицинских снимков, современном моделировании компьютерного зрения и везде, где есть необходимость обработки очень крупных изображений — например, при работе с GAN-архитектурами.
В то же время RTX 3080 с ее 10 Гбайт графической памяти вполне подойдет для работы с задачами глубокого машинного обучения, поскольку для изучения основ большинства архитектур вполне достаточно уменьшить размер сетей или использовать на входе изображения меньшего размера, а затем при необходимости масштабировать модель до необходимых параметров на более мощных GPU-серверах.
С учетом того, что память HBM, применяемая в картах класса A100, вряд ли существенно подешевеет в ближайшее время, можно сказать, что карты RTX 3090 / RTX 3080 являются вполне эффективной инвестицией на несколько ближайших лет.
Нидерландский хостинг-провайдер HOSTKEY предлагает широкий ассортимент GPU-серверов в дата-центрах в Нидерландах и в Москве на основе как GPU последнего поколения RTX3080 и RTX3090, так и на основе карт предыдущих поколений RTX2080Ti и GTX1080Ti/1080. Компания предлагает как готовые к работе серверы, так и серверы с индивидуальными конфигурациями, которые идеально отвечают потребностям заказчика. Компания благодарит Эмиля Закирова и Александра Широносова за помощь в проведении тестов.