
Здравствуйте!
Вчера мы с вами поговорили о HTML и CSS и о том, какое отношение они имеют к веб-разработке с использованием Python. Сегодня поговорим о более обширной и серьёзной для нашей работы веб-программистом теме. Не будем забегать вперёд о какой, сейчас вы всё узнаете.
Когда мы с вами заходим на любую страничку в интернете, конечно, если это не какая-нибудь статичная страничка, где данные никогда не меняются и отображаются обычным текстом и одноцветными блоками(хотя и в этом случае бывают исключения), мы видим на этой страничке различные данные — статьи, картинки, имя автора статьи, дату публикации и так далее, и так далее. И если статей много, то они распределяются по разным страницам, мы можем смотреть их, щёлкая по ним мышкой, а они открываются в полном размере. Вы никогда не задумывались откуда берутся все эти отображаемые данные и как браузер нам их так быстро предоставляет, через всего 0.5-1 секунду? Ведь они где-то должны храниться, не в коде же HTML и CSS они хранятся, в этом случае, вёрстка страницы у нас занимала бы миллионы строк кода, а браузер бы зависал, пока искал, что мы от него хотим. И, возможно, зависал бы намертво, потому что, чтобы вычислить такие объемы информации из кучи несгруппированной информации, ему понадобилось бы много-много времени.
Представьте себе такую городскую библиотеку, где все книги просто свалены в кучу, без каких-либо опознавательных знаков и без какой-либо сортировки, и книг этих, предположим, что хотя бы пять тысяч. К вам приходит читатель и просит выдать ему роман "Бесы" Фёдора Михайловича Достоевского. Вы идёте к этой большой куче книг и начинаете бегать глазами по корешкам, где они видны, а потом раскапывать кучу и перебирать каждую книгу. Сколько времени у вас это займёт? Хорошо, если вы управитесь в течение дня, но даже это время читатель не будет вас ждать, а пойдёт в библиотеку, где всё рассортировано по каталогам, а в каталогах всё рассортировано по карточкам. Где поиск книги занимает 5-10 минут максимум.
Вот и пользователь, который зашёл на страничку с таким бардаком и неотсортированными данными, тоже быстро от нас уйдёт. Кто же поможет нам в сложившейся ситуации?
Ответ на этот вопрос следующий — базы данных, а если быть совсем точным — реляционные базы данных. Не знаю, как вас, а меня сначала напугало слово "реляционные", но после того, как я понял, что оно образовано от английского слова relation(отношение), то всё встало на свои места. Чтобы лучше понять, что же такое реляционная база данных, посмотрим на следующую картинку, где всё очень наглядно показано.
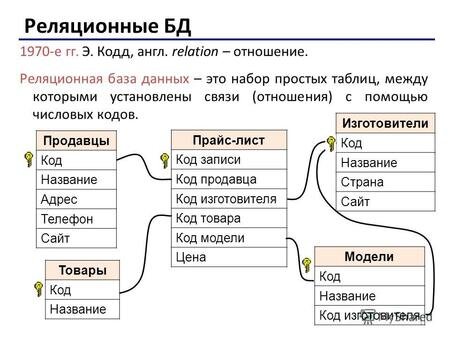
Как показано на данной картинке база данных это набор таблиц, в которых содержатся различные данные. Всё, на самом деле, достаточно просто. А реляционные они потому, что связаны определённым кодом. Сейчас объясню более понятно на примере библиотеки.
У нас с вами есть библиотека — это, в нашем случае, база данных. У книг есть авторы, у авторов есть имя, фамилия, отчество и порядковый номер в нашей библиотеке(id). Авторы — это таблица. Также у нас есть книги, как мы уже поняли, у книг есть название, год выпуска, количество страниц и ISBN(уникальный номер книги). Книги — ещё одна таблица с данными. У нас есть издательства, которые соответственно издают книги, у издательств есть город местонахождения, юридическое название, юридический адрес, фактический адрес и т.д. Издательства, как вы наверное уже поняли, тоже — таблица. Также в библиотеке есть полки, у полок есть их порядковый номер и местонахождение. Полки это тоже таблица. Так вот, чтобы нашему библиотекарю найти роман "Бесы" Фёдора Михайловича Достоевского, нужно зайти в таблицы книги, ввести в поиске "Бесы" и увидеть идентификатор полки, где книга находится. При этом в таблице с книгами не будет ни подробной информации о полке, ни о издательстве, ни об авторе. В таблице "Книги" будут ссылки на эти таблицы. А как же компьютер поймёт, что это та самая книга? По тому самому индивидуальному коду, который есть в каждой таблице, чаще всего это id(автоматически присваиваемый индивидуальный код каждой строки данных), но возможен и ISBN(но лучше так делать не надо, так как ISBN очень ёмкий по количеству символов и в его написании можно сделать ошибку, что приведёт к неработоспособности всей базы), так как он точно не может встретиться в пределах таблицы два раза, другими словами — уникальный. В таблице-родителе, например в таблице книг, id книги называется primary key(первичный ключ), а в таблице издательства, где на этот ключ идёт ссылка, он называется foreign key(внешний ключ). Давайте ещё раз проговорим: primary key в пределах таблицы должен быть всего один, иначе он теряет всякий смысл, foreign key может быть столько, сколько вам нужно для ваших задач.
SQL
Вы наверное уже догадались, что должно быть что-то, что ответственно за создание баз данных, таблиц в них, данных в этих таблицах и так далее. И ваша догадка верна, для этого существует специальный язык программирования — SQL. Также сущетсвует СУБД(система управления базами данных), из расшифровки думаю понятно, что это некий программный продукт, который позволяет нам управлять базами данных, а делает он это с помощью языка SQL в том числе. СУБД существует несколько, вот некоторые из них — MySQL, PostgreSQL, Oracle Database, SQLite, Microsoft SQL Server и другие. Работу с одной из них нам и предстоит изучить, а в процессе развития вашей карьеры, вы возможно, будете изучать и другие. По умолчанию при работе с Python в него уже включена SQLite.
Язык SQL достаточно прост и логичен, и изучение его доставляет одно удовольствие. А ещё изучать его очень интересно. Где можно ему обучиться, я расскажу в конце статьи.
Но мало выучить язык SQL.
Нужно, чтобы данные из нашей базы данных, каким-то образом обрабатывались в нашем коде Python, откуда потом пользователь получает их из шаблонов(но это совсем другая история=)). Так вот, для этой цели существует свой инструмент и называется он ORM(если вы проходили курс от JetBrains, то вы с ним уже встречались). ORM расшифровывается, как (информация из Википедии)
Object-Relational Mapping, рус. объектно-реляционное отображение, или преобразование
В Python самой популярной ORM является SQLAlchemy, она независима от различных фреймворков(опять это слово! скоро-скоро мы к ним придём, потерпите ещё чуть-чуть) Python и чувствует себя в них комфортно. Хотя, например, в Django(а Django это фреймворк))), всё-всё больше не буду))), есть своя ORM — Django ORM, но её недостаток в том, что работает она исключительно в пределах Django, и говорят не подходит для серьёзных запросов к базам данных, в отличие от SQLAlchemy.
И на данный момент у меня для вас есть небольшая хорошая новость: сейчас изучать SQLAlchemy вам не нужно, вы плавно будете приступать к его изучению в процессе работы с Django или Flask(позже-позже).
Где поучить SQL?
1. Learning SQL, 3rd Edition by Alan Beaulieu — очень крутая книжка по SQL, ищите именно третье издание, оно самое новое. И оно на английском. На русском есть второе издание, но, когда я недавно её хотел перечитать и освежить знания, я столкнулся с тем, что код в ней устарел и не работает на новых версиях MySQL. А третье издание выпущено в марте этого 2020 года.
2. Введение в базы данных — бесплатный курс на Stepik, с сертификатом от Высшей Школы Экономики.
3. SQL Fundamentals — сборник из пяти курсов по SQL с сертификатами за каждый и подтверждением полученных навыков в конце. Курс крутой — достаточно теории, много практики, хорошие примеры. Но он платный, доступен по подписке за 1000 с чем-то рублей в месяц(в зависимости от курса доллара). Можно найти промокод и тогда курс будет дешевле.
На сегодня на этом всё, завтра, возможно, поговорим о фреймворках, а возможно, о чём-то другом тоже важном и интересном =)
До завтра. А если понравилась статься — ставьте лайки и подписывайтесь на канал, если ещё нет. Приятного вам обучения!
Предыдущая статья ............................................................. Следующая статья.