
Что такое сегментация ?
Instance Segmentation - это функция распознавания контуров объекта на уровне пикселей. Это одна из самых сложных задач зрения по сравнению с аналогичными задачами компьютерного зрения. Используйте следующую терминологию:
- Classification — классификация изображения по типу объекта, которое оно содержит;
- Semantic segmentation — определение всех пикселей объектов определённого класса или фона на изображении. Если несколько объектов одного класса перекрываются, их пиксели никак не отделяются друг от друга;
- Object detection — обнаружение всех объектов указанных классов и определение охватывающей рамки для каждого из них;
- Instance segmentation — определение пикселей, принадлежащих каждому объекту каждого класса по отдельности;
Вы можете изучить основы и то, как на самом деле работает Mask RCNN, здесь.
Мы реализуем Mask RCNN для пользовательского набора данных на языку Python. В этом коде мы проведем простую классификацию лошади и человека. Вы можете изменить это на свой собственный набор данных.
Давай начнем.
1. Импорт и клонирование репозиториев.
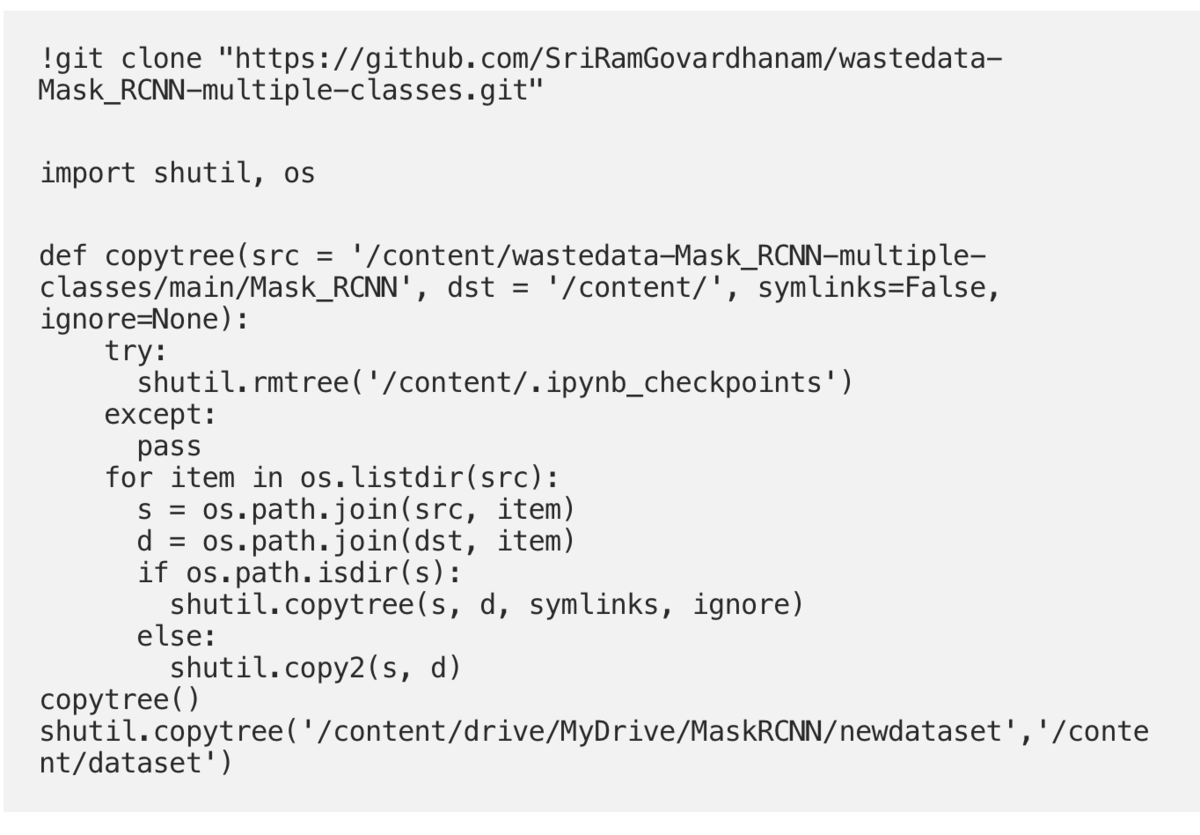
Сначала мы клонируем репозиторий, содержащий блоки кода для реализации Mask RCNN. Функция copytree () спарсит дляас н необходимые файлы. После клонирования репозитория мы импортируем набор данных. В данном примере - я импортирую набор данных со своего диска.
Теперь поговорим о наборе данных. Набор данных, который я импортировал имеет следующую структуру:
Датасет, создан с помощью VGG Image Annotator (VIA). Файл аннотации имеет формат .json, который содержит координаты всех многоугольников, которые я нарисовал для этого примера .Файл .json выглядит примерно так:
Примечание. Хотя в приведенном выше фрагменте я показал несколько фигур, при аннотации изображений следует использовать только одну фигуру. Например, если вы выберете полигоны, как я для классификатора «Лошадь или человек», то вам следует разметить все регионы только полигонами. Мы обсудим, как использовать несколько фигур для разметки позже в этом руководстве.
2. Подбор нужных версий библиотек.
Примечание. Это самый важный шаг для реализации архитектуры Mask RCNN без ошибок.
Лучше использовать Keras 2.2.5 версии, эьл избавит нас от многих ошибок. Я не буду вдаваться в подробности о том, какие ошибки это разрешает, достоточно зайти на стаковерфло и почитать вопросы с пометкой- RCNN Keras.
3. Конфигурация согласно нашему набору данных
Сначала мы импортируем несколько библиотек. Затем мы зададим путь к файлу обученных весов. Это может быть файл весов COCO или ваш последний сохраненный набор с парамтерами- весами (если у вас такой есть). Каталог журналов - это место, где все наши данные будут храниться, когда начнется обучение. Веса модели для каждой эпохи сохраняются в каталоге в формате .h5, поэтому, если обучение будет проблемным по какой-либо причине, вы всегда можете начать с того места, где остановились, указав путь к последним сохраненным весам модели. Например, если я тренирую свою модель в течение 10 эпох, а в эпоху 3 мое обучение затруднено, то в моем каталоге журналов будет храниться 3 файла .h5. И теперь мне не нужно начинать тренировки с самого начала. Я могу просто изменить свой путь весов к последнему файлу весов, например.‘Mask_rcnn_object_0003.h5’.
Класс CustomConfig содержит наши пользовательские конфигурации для модели. Мы просто перезаписываем данные в исходном классе Config из файла config.py, который был импортирован ранее. Количество классов должно быть total_classes + 1. Шагов на эпоху установлено 100, но при желании их можно увеличить, если у вас есть доступ к более высоким вычислительным ресурсам.
Порог обнаружения составляет 90%, что означает, что все предсказания с достоверностью менее 0,9 будут проигнорированы. Этот порог отличается от порога при тестировании изображения. Для пояснения посмотрите на код ниже.
4. Настройка класса CustomDataset.
Приведенный ниже класс содержит 3 важных метода для нашего настраиваемого набора данных. Этот класс наследуется от «utils.Dataset», который мы импортировали на первом шаге. Метод load_custom предназначен для сохранения аннотаций вместе с изображением. Здесь мы извлекаем полигоны, используч соответствующие классы.
polygons = [r[‘shape_attributes’] for r in a[‘regions’]]
objects = [s[‘region_attributes’][‘name’] for s in a[‘regions’]]
Переменная Polygons содержит координаты масок. Переменная Objects содержит имена соответствующих классов.
Метод load_mask загружает маски по координатам многоугольников. Маска изображения - это не что иное, как список, содержащий двоичные значения. Skimage.draw.polygon () выполняет эту задачу за нас и возвращает индексы для координат маски.
Удобночитаемый код тут:
https://gist.github.com/jackfrost1411/3302e5e0e5e3c56fba45f5e0e7de364a#file-function-py
class CustomDataset(utils.Dataset):
def load_custom(self, dataset_dir, subset):
"""Load a subset of the Horse-Man dataset.
dataset_dir: Root directory of the dataset.
subset: Subset to load: train or val
"""
# Add classes. We have only one class to add.
self.add_class("object", 1, "Horse")
self.add_class("object", 2, "Man")
# self.add_class("object", 3, "xyz") #likewise
# Train or validation dataset?
assert subset in ["train", "val"]
dataset_dir = os.path.join(dataset_dir, subset)
# Load annotations
# VGG Image Annotator saves each image in the form:
# { 'filename': '28503151_5b5b7ec140_b.jpg',
# 'regions': {
# '0': {
# 'region_attributes': {},
# 'shape_attributes': {
# 'all_points_x': [...],
# 'all_points_y': [...],
# 'name': 'polygon'}},
# ... more regions ...
# },
# 'size': 100202
# }
# We mostly care about the x and y coordinates of each region
annotations1 = json.load(open(os.path.join(dataset_dir, "via_project.json")))
# print(annotations1)
annotations = list(annotations1.values()) # don't need the dict keys
# The VIA tool saves images in the JSON even if they don't have any
# annotations. Skip unannotated images.
annotations = [a for a in annotations if a['regions']]
# Add images
for a in annotations:
# print(a)
# Get the x, y coordinaets of points of the polygons that make up
# the outline of each object instance. There are stores in the
# shape_attributes (see json format above)
polygons = [r['shape_attributes'] for r in a['regions']]
objects = [s['region_attributes']['name'] for s in a['regions']]
print("objects:",objects)
name_dict = {"Horse": 1,"Man": 2} #,"xyz": 3}
# key = tuple(name_dict)
num_ids = [name_dict[a] for a in objects]
# num_ids = [int(n['Event']) for n in objects]
# load_mask() needs the image size to convert polygons to masks.
# Unfortunately, VIA doesn't include it in JSON, so we must read
# the image. This is only managable since the dataset is tiny.
print("numids",num_ids)
image_path = os.path.join(dataset_dir, a['filename'])
image = skimage.io.imread(image_path)
height, width = image.shape[:2]
self.add_image(
"object", ## for a single class just add the name here
image_id=a['filename'], # use file name as a unique image id
path=image_path,
width=width, height=height,
polygons=polygons,
num_ids=num_ids
)
def load_mask(self, image_id):
"""Generate instance masks for an image.
Returns:
masks: A bool array of shape [height, width, instance count] with
one mask per instance.
class_ids: a 1D array of class IDs of the instance masks.
"""
# If not a Horse/Man dataset image, delegate to parent class.
image_info = self.image_info[image_id]
if image_info["source"] != "object":
return super(self.__class__, self).load_mask(image_id)
# Convert polygons to a bitmap mask of shape
# [height, width, instance_count]
info = self.image_info[image_id]
if info["source"] != "object":
return super(self.__class__, self).load_mask(image_id)
num_ids = info['num_ids']
mask = np.zeros([info["height"], info["width"], len(info["polygons"])],
dtype=np.uint8)
for i, p in enumerate(info["polygons"]):
# Get indexes of pixels inside the polygon and set them to 1
rr, cc = skimage.draw.polygon(p['all_points_y'], p['all_points_x'])
mask[rr, cc, i] = 1
# Return mask, and array of class IDs of each instance. Since we have
# one class ID only, we return an array of 1s
# Map class names to class IDs.
num_ids = np.array(num_ids, dtype=np.int32)
return mask, num_ids #np.ones([mask.shape[-1]], dtype=np.int32)
def image_reference(self, image_id):
"""Return the path of the image."""
info = self.image_info[image_id]
if info["source"] == "object":
return info["path"]
else:
super(self.__class__, self).image_reference(image_id)
Ранее мы обсуждали, что вы не должны использовать более одной формы при аннотации, так как это может усложнить загрузку масок.
Хотя, если вы хотите использовать несколько форм, например круг, эллипс и многоугольник, вам нужно будет изменить функцию маски , как показано ниже.
Это один из способов загрузки масок с несколькими формами, но это всего лишь предположение, и модель может не обнаружить круг или эллипс, если не захватит идеальную форму круга или эллипса.
5. Создание функции Train ()
Набор данных, который я импортировал со своего диска, имеет следующую структуру:
Сначала мы создадим экземпляр класса CustomDataset для набора обучающих данных. Точно так же создадим другой экземпляр для проверочного набора данных. Затем мы вызовем метод load_custom (), передав имя каталога, в котором хранятся наши данные. Параметр «layers» здесь установлен на «heads», поскольку я не планирую обучать все слои в модели. Это обучит только некоторые из верхних слоев нашей архитектуры. Если вы хотите, вы можете установить «layers» на «all» для обучения всех слоев модели.
Я использую модель только для 10, так как это руководство должно помочь вам.
Код: https://gist.github.com/jackfrost1411/71ddbe81ba18e2182ecdd44c4ed3b27e#file-trainclass-py
<script src="https://gist.github.com/jackfrost1411/71ddbe81ba18e2182ecdd44c4ed3b27e.js"></script>
def train(model):
"""Train the model."""
# Training dataset.
dataset_train = CustomDataset()
dataset_train.load_custom("/content/dataset", "train")
dataset_train.prepare()
# Validation dataset
dataset_val = CustomDataset()
dataset_val.load_custom("/content/dataset", "val")
dataset_val.prepare()
# *** This training schedule is an example. Update to your needs ***
# Since we're using a very small dataset, and starting from
# COCO trained weights, we don't need to train too long. Also,
# no need to train all layers, just the heads should do it.
print("Training network heads")
model.train(dataset_train, dataset_val,
learning_rate=config.LEARNING_RATE,
epochs=10,
layers='heads')
6. Настройка перед тренировкой
Этот шаг предназначен для настройки модели для обучения, загрузки и загрузки предварительно обученных весов. Вы можете загрузить вес COCO или последней сохраненной модели.
Вызов modellib.MaskRCNN () - это шаг, на котором вы можете получить много ошибок, если вы не выбрали правильные версии Keras и TF, как я писал выше. Этот метод имеет параметр «режим», который определяет, хотим ли мы обучать модель или тестировать ее. Если вы хотите протестировать, установите режим «mode» на «inference», «Model_dir» предназначен для сохранения данных во время обучения (бэкап). Затем на следующем этапе мы загружаем предварительно обученные веса COCO.
Примечание. Если вы хотите возобновить обучение с сохраненной точки, вам нужно изменить «weights_path» на путь, в котором хранится ваш файл .h5.
config = CustomConfig()
model = modellib.MaskRCNN(mode="training", config=config,
model_dir=DEFAULT_LOGS_DIR)
weights_path = COCO_WEIGHTS_PATH
# Download weights file
if not os.path.exists(weights_path):
utils.download_trained_weights(weights_path)
model.load_weights(weights_path, by_name=True, exclude=[
"mrcnn_class_logits", "mrcnn_bbox_fc",
"mrcnn_bbox", "mrcnn_mask"])
7. Начать обучение.
Этот шаг не должен вызывать никаких ошибок, если вы выполнили описанные выше шаги и обучение должно начаться плавно. Помните, что нам нужен Keras версии 2.2.5, чтобы этот шаг работал без ошибок.
Примечание. Если вы получили сообщение об ошибке, перезапустите среду выполнения и снова запустите все ячейки. Это может быть из-за загруженной версии TensorFlow или Keras. Следуйте шагу 2 для выбора правильных версий.
Примечание: игнорируйте любые предупреждения, которые вы получаете во время тренировки!
8. Тестирование
Вы можете найти в блокноте инструкции о том, как протестировать нашу модель после завершения обучения.
Здесь мы определяем путь к нашему последнему сохраненному файлу весов, чтобы запустить логический вывод.Затем мы определяем простые термины конфигурации. Здесь снова указывается уверенность для тестирования.Он отличается от того, который используется на тренировках.
Теперь загрузим модель для выполнения вывода.
Теперь загружаем веса в модель.
Теперь мы готовы к тестированию нашей модели на любом изображении.
9. Всплеск цвета
Для развлечения вы можете попробовать приведенный ниже код, который присутствует в исходной реализации Mask RCNNhttps://github.com/matterport/Mask_RCNN/tree/master/samples/balloon. Это преобразует все оттенки серого, кроме областей маски объекта.
def color_splash(image, mask):
"""Apply color splash effect.
image: RGB image [height, width, 3]
mask: instance segmentation mask [height, width, instance count]
Returns result image.
"""
# Make a grayscale copy of the image. The grayscale copy still
# has 3 RGB channels, though.
gray = skimage.color.gray2rgb(skimage.color.rgb2gray(image)) * 255
# We're treating all instances as one, so collapse the mask into one layer
mask = (np.sum(mask, -1, keepdims=True) >= 1)
# Copy color pixels from the original color image where mask is set
if mask.shape[0] > 0:
splash = np.where(mask, image, gray).astype(np.uint8)
else:
splash = gray
return splash
def detect_and_color_splash(model, image_path=None, video_path=None):
assert image_path or video_path
# Image or video?
if image_path:
# Run model detection and generate the color splash effect
print("Running on {}".format(args.image))
# Read image
image = skimage.io.imread(args.image)
# Detect objects
r = model.detect([image], verbose=1)[0]
# Color splash
splash = color_splash(image, r['masks'])
# Save output
file_name = "splash_{:%Y%m%dT%H%M%S}.png".format(datetime.datetime.now())
skimage.io.imsave(file_name, splash)
elif video_path:
import cv2
# Video capture
vcapture = cv2.VideoCapture(video_path)
width = int(vcapture.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(vcapture.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = vcapture.get(cv2.CAP_PROP_FPS)
# Define codec and create video writer
file_name = "splash_{:%Y%m%dT%H%M%S}.avi".format(datetime.datetime.now())
vwriter = cv2.VideoWriter(file_name,
cv2.VideoWriter_fourcc(*'MJPG'),
fps, (width, height))
count = 0
success = True
while success:
print("frame: ", count)
# Read next image
success, image = vcapture.read()
if success:
# OpenCV returns images as BGR, convert to RGB
image = image[..., ::-1]
# Detect objects
r = model.detect([image], verbose=0)[0]
# Color splash
splash = color_splash(image, r['masks'])
# RGB -> BGR to save image to video
splash = splash[..., ::-1]
# Add image to video writer
vwriter.write(splash)
count += 1
vwriter.release()
print("Saved to ", file_name)
Вы можете вызвать эту функцию, как указано ниже. Для обнаружения видео вызовите вторую функцию.
10. Далее…
Вы можете узнать, как работают предложения региона, из последних ячеек записной книжки. Ниже приведены некоторые из интересных изображений, которые могут привлечь ваше внимание, если вам интересно, как работают сети региональных предложений.
Возможно, вы захотите увидеть, как работает классификация предложений и как мы получаем конечные регионы для сегментации. Эта часть также покрыта последней частью ноутбука.
Вы можете найти блокнот, содержащий весь код, который мы видели выше, на GitHub здесь https://github.com/jackfrost1411/MaskRCNN. Вы можете связаться со мной в LinkedIn отсюда https://www.linkedin.com/in/dhruvilshah28/