
Разведочный анализ данных (Exploratory Data Analysis) – предварительное исследование Датасета (Dataset) с целью определения его основных характеристик, взаимосвязей между признаками, а также сужения набора методов, используемых для создания Модели (Model) Машинного обучения (Machine Learning).
Давайте рассмотрим, на какие этапы EDA разбивают. Для этого мы используем данные банка, который автоматизирует выдачу кредитов своим клиентам. В реальной жизни получить такой датасет – довольно дорогое удовольствие, по карману зачастую это только среднему и крупному бизнесу. К счастью, мы располагаем обширным набором переменных (столбцов):
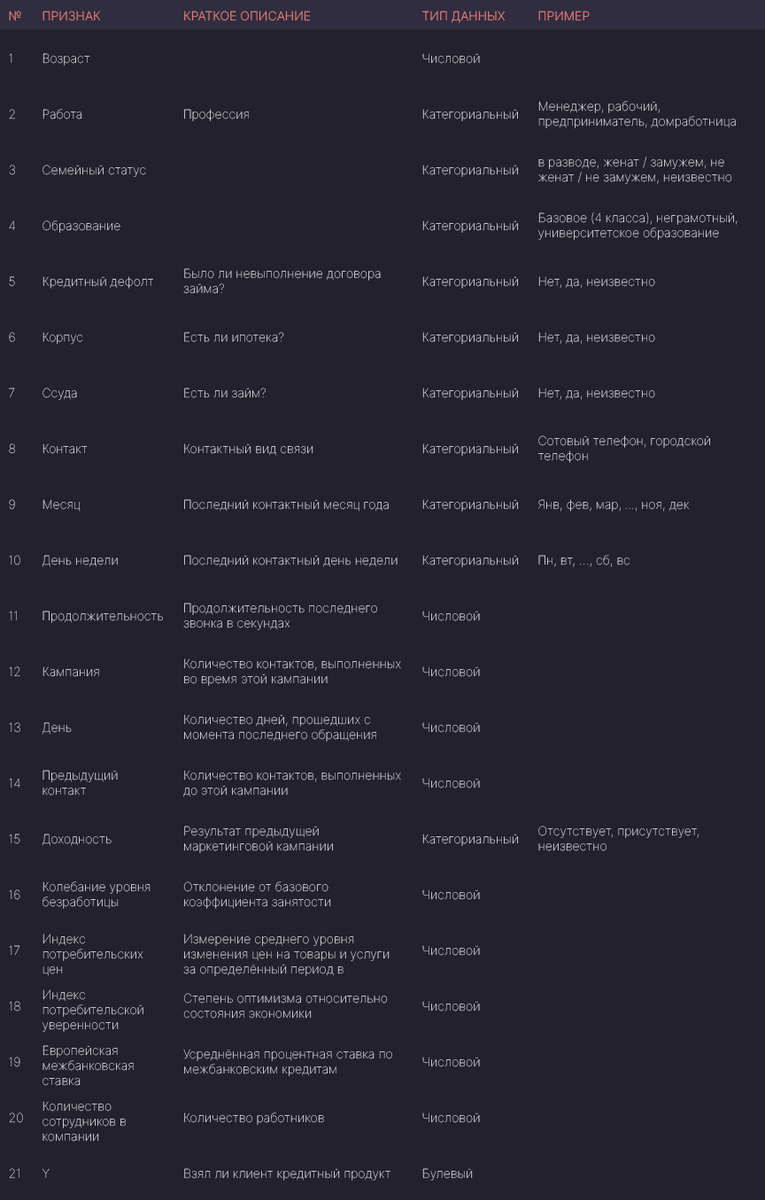
Теперь стало немного понятнее, почему менеджеры по продажам, звонящие из банков, ведут себя так странно? Они располагают именно таким набором данных о Вас.
Довольно увесистый датасет для восприятия, особенно если учесть, что записей в нем – более 40 тысяч. Однако приступим! Для начала импортируем датасет и посмотрим на "шапку". Параметр 'sep' используется, чтобы указать на нестандартный разделитель, в данном случае – точку с запятой, которая используется в Apple Numbers.
Итак, нам предстоит пройти несколько этапов разведочного анализа, и среди них будут взаимоисключающие, потому его придется импортировать несколько раз.
Удаление дубликатов
Дублирующие записи не только искажают статистические показатели датасета, но и снижают качество обучения модели, потому удалим полные дублирующие вхождения. Для начала уточним, сколько записей в датасете с помощью свойства Pandas.DataFrame.shape:
Удалим дублирующие записи с помощью Pandas.drop_duplicates() и обновим данные о размере данных:
Pandas нашел и удалил 12 дубликатов. Хоть число и небольшое, все же качество данные мы повысили.
Обработка пропусков
Существует несколько способов обозначить пропуски, и зачастую создатели датасета не описывают данные в достаточной мере, и определять, как обозначены пропуски, приходится вручную. Из встреченных доселе обозначений приведу следующие:
- NaN / NaT (упрощенно: "не число" / "не время")
- Пустая ячейка
- Для числовых признаков – радикальный выброс. К примеру, для столбца "День" это число 999.
- Маркер или нестандартный символ
Встроенные методы Pandas позволяют с легкостью справиться с первыми двумя разновидностями таких пробелов. Разберемся для начала с категориальными переменными, объединив их в один вектор. Список получится совсем уж нелогичный, но это не столь важно в данной ситуации: мы лишь ищем способы обозначения пропуска.
Из общего списка уникальных значений этих переменных пропуски обозначаются словом "Неизвестно". Для числовых переменных пропуски – число 999 или пустая ячейка.
Процесс обработки пропусков, к счастью, можно сократить с помощью sklearn.impute.SimpleImputer. Мы выбираем все категориальные переменные и применяем стратегию "[вставить вместо пропуска] самое распространенное значение":
Такой код можно сократить еще с помощью Пайплайнов (Pipeline), однако здесь обработаем каждую переменную построчно.
Признаки, принадлежащие к булевому типу данных, обрабатываются алгоритмом тем же образом. Целевую переменную Y мы не обрабатываем (если в этом столбце есть пропуски, такие строки стоит удалить):
Подобным образом заполняются пустоты в числовых переменных, только стратегия теперь – "вставить среднее значение".
Обнаружение аномалий
Самый легкий способ обнаружить выбросы – визуальный. Мы построим разновидность графика "ящик с усами" для одной из числовых переменных – "Возраст":
Скучковавшиеся окружности в верхней части изображения – и есть аномалии, и от них, как правило, избавляются с помощью квантилей:
Во второй части статьи о разведочном анализе Вы узнаете про:
- Одномерный анализ (описательная статистика, важность признаков (Feature Importance)
- Одномерный анализ (парный анализ, уменьшение размерности, стандартизация, Нормализация (Normalization)
Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Понравилась статья? Поддержите нас, поделившись статьей в социальных сетях и подписавшись на канал. И попробуйте наши курсы по Машинному обучению на Udemy.