Изучение наборов данных MNIST1 и FASHION MNIST2 с помощью логистической регрессии и случайного леса

Авторы Гэвин Смит и Суан Кхан Нгуен
В этом семестре я прошел курс машинного обучения в университете Тафтса. Это был один из моих любимых курсов по Data Science, которые я изучал до сих пор. Он научил меня определять, решает ли машинное обучение проблему. И что наиболее важно, это сделало меня лучше в области Data Science.
Нам дали три проекта на весь семестр. У каждого проекта есть структурная проблема и открытая проблема. Вы можете себе представить открытую спецификацию. В духе того, чтобы не заглушать блестящие искры творчества, нам было предложено создать модель машинного обучения по нашему выбору.
Для первого проекта нам дали два набора данных. Популярный набор данных MNIST1 соответствует написанным от руки цифрам 8 и 9 для Части 1 и изображениям сандалий и обуви из набора данных FASHION MNIST2 для Части 2. Для Части 1 наши задачи заключаются в изучении использования моделей логистической регрессии и определении влияния различные гиперпараметрические оптимизации точности модели на цифровых данных изображения. Для части 2 наша задача - найти наилучшую возможную модель в наборе данных Fashion MNIST для определения разницы между обувью и сандалиями. В обоих разделах поясняются методики вместе с соответствующими рисунками и изображениями.
Часть 1. Набор рукописных цифр MNIST
1.1. Исследование набора данных
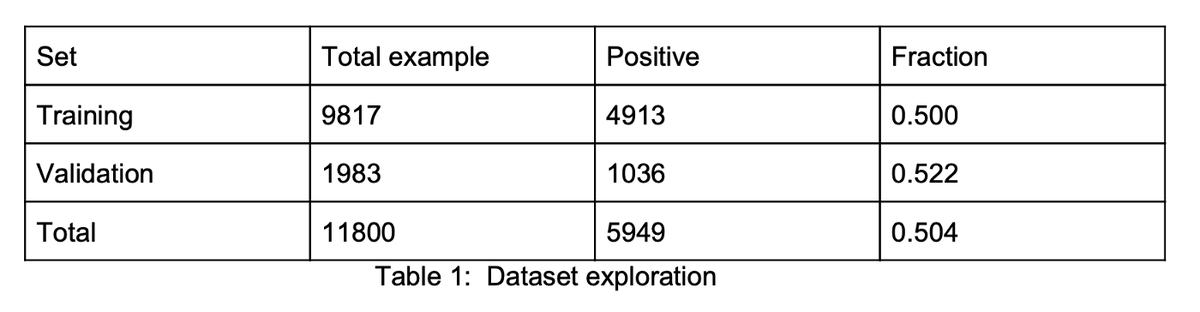
Набор данных, использованный для этой части проекта, был подразделом набора данных MNIST, который включает только цифры 8 и 9. В результате (см. Таблицу 1) обучающий набор состоял из 11 800 наборов функций, каждая из которых состоит из 784 пикселя (соответствует сетке 28x28). Набор для проверки состоял из наборов функций 1983 года. Модель логистической регрессии была адаптирована к этим наборам данных с помощью sklearn, и была выполнена настройка различных параметров.
1.2. Оценка потерь и ошибок в сравнении с итерациями обучения
В этом разделе модели логистической регрессии были подогнаны к обучающим данным с помощью sklearn с использованием решателя lbfgs. Все остальные значения были оставлены по умолчанию, и основное исследование было результатом итерации для моделей с использованием параметра max_iter.
Рисунок 1: Потеря доступа и ошибка в сравнении с итерациями обучения
На левом графике показаны потери (ось Y) в зависимости от итераций (ось X) с двумя линиями (синяя для обучения, красная для проверки). От i = 0 до i = 5 логистические потери уменьшаются с линейной скоростью для обучающей выборки, пока не выровняются от i = 5 до i = 40. Логистические потери для набора для проверки линейно уменьшаются в течение первых семи итераций и начинают расти. Для первых семи итераций частота ошибок уменьшается как на обучающем, так и на проверочном наборе. Мы видим переобучение после 10 итераций, когда потери при обучении уменьшаются до нуля, а потери при проверке возрастают. Эта функция логистических потерь наказывает ошибочные прогнозы за счет высокой стоимости, и она увеличивается по мере того, как прогнозируемая вероятность отклоняется от фактического истинного значения для выходного класса.Идеальная модель должна иметь нулевые логистические потери.
Правый график показывает коэффициент ошибок (ось y) в зависимости от итераций (ось x) с двумя линиями (синяя для обучения, красная для проверки). Мы использовали sklearn.metrics.zero_one_loss, чтобы получить частоту ошибок. В sklearn потеря нуля или единицы считает, что весь набор меток для данного образца неверен, если он не полностью соответствует истинному набору меток. Для первых семи итераций частота ошибок уменьшается как на обучающем, так и на проверочном наборе данных. После этого частота ошибок начинает увеличиваться на проверочном наборе и уменьшается на обучающем наборе. Это проблема переоборудования.Одна из причин объяснения такого переобучения состоит в том, что модель слишком долго тренируется.
1.3. Выбор гиперпараметра
В этом разделе мы используем ту же модель логистической регрессии с решателем lbfgs, как описано ранее, наилучшее значение C равно 0,01.
Рисунок 2: Коэффициент ошибок как функция C
1.4. Анализ ошибок
В этом разделе ошибки, допущенные лучшей моделью, определяемые значением C, а также соответствующие логистические потери и точность были проанализированы путем обнаружения ложных срабатываний и ложных отрицательных результатов в выходном наборе нашей модели и их построения в виде изображений с помощью matplotlib.
Рисунок 3: Ложноположительный результат на наборе для проверки
На рисунке 3 показано, что, согласно прогнозам модели, все они представляют цифру 9.
Рисунок 4: Ложноотрицательные результаты в наборе для проверки.
На рисунке 4 показано, что, согласно прогнозам модели, все они представляют цифру 8.
Классификатор неправильно определяет, когда на изображении есть некоторые ключевые факторы для другого предмета. Например, если 9 написано в очень с большим наклоном нижней части, такой как «/», а не прямым «|» или имеет горизонтальную линию внизу, 9 классифицируется как 8. Это линейно-взвешенная модель, поэтому, как только эти ключевые характеристики перевешивают, модель делает неверный прогноз. Это можно объяснить с точки зрения порога, используемого для классификации между 8 или 9. Использование пороговых значений 0,5 повышает вероятность того, что классификатор будет делать ошибки даже при определении ложных срабатываний и ложных отрицаний. Еще один возможный результат этого результата состоит в том, что обучающие данные входного набора могли классифицировать некоторые из этих изображений как восьмерки, тогда как они должны были быть девятками. Такую теорию можно подтвердить только путем преобразования всех наборов функций в представления изображений и классификации их выходных меток вручную.
1.5. Интерпретация выученных весов
Рисунок 5: Весовые коэффициенты модели логистической регрессии
Пиксели, соответствующие цифре 8 (имеют отрицательные веса), имеют красный оттенок. Пиксели, которые соответствуют 9 (имеют положительные веса), имеют более синий оттенок. Красные и синие пиксели за пределами областей с высокой плотностью красных / синих пикселей соответствуют добавленному шуму при предварительной обработке набора данных MNIST. Пиксели, которые не являются ни красными, ни синими, но соответствуют желтому оттенку, являются пустыми пространствами внутри изображений. Эти результаты можно проверить, используя значения vmin и vmax, а также цветовую карту RdYlBu. Поскольку vmin = -0,5, отрицательные веса, которые ближе к -0,5, имеют более красный оттенок, а поскольку vmax = 0,5, веса, которые более положительны и ближе к 0,5, имеют более синий оттенок. Веса, близкие к нулю, будут иметь желтоватые оттенки, соответствующие пустому пространству на изображении.
Часть 2: классификация образа кроссовок и сандалий
Раздел 1: Способы изготовления кроссовок-сандалий
2.1.дизайн
Мы решили разделить данные, используя фиксированную проверку, а не перекрестную проверку. Чтобы решить это, мы проанализировали частоту ошибок в нашем базовом классификаторе, используя много разного количества данных для перекрестной проверки и множество разных разделений данных для фиксированной проверки.Результаты для этого можно увидеть на рисунках 6 и 7, где для перекрестной проверки потери журнала на проверочном наборе уменьшались по мере увеличения количества складок. Для фиксированной проверки потеря журнала в наборе проверки была минимизирована, при этом 30% данных были тестовыми. Оба метода дали логарифмические потери около 0,1. Мы решили использовать фиксированную проверку вместо перекрестной проверки с этими результатами, потому что фиксированная проверка имеет более короткое время выполнения, особенно при использовании множества сверток в перекрестной проверке. Мы выбрали фиксированную проверку, потому что с большим набором данных, который нам был предоставлен, проблема случайного набора проверок, создание большого разброса в нашей ошибке, минимальна.
Рисунок 6: Частота ошибок в базовых моделях по мере увеличения количества перекрестных проверок
На рисунке 6 показано, что по мере увеличения количества разделений с перекрестной проверкой потери и ошибки журнала проверки уменьшаются.
Рисунок 7.Частота ошибок в базовой модели по мере увеличения размера набора тестов при фиксированной проверке.
На рис. 7 показано, что по мере увеличения размера тестового набора при фиксированной проверке потери и ошибки журнала проверки немного уменьшаются, но ошибки обучения и потери журнала увеличиваются.
2.2 Базовый классификатор, подгонка модели и процесс выбора гиперпараметров.
Для базового классификатора мы рассмотрели 3 параметра: C, максимальное количество итераций и штраф. Во-первых, мы рассмотрели параметр C, который измеряет инверсию регуляризации, а это означает, что чем ниже значение C, тем более регуляризованной будет модель и тем сильнее будет наказание за переобучение. Мы выбрали значение C, используя поиск по сетке, где возможные значения варьировались от десятичных знаков до десяти тысяч. Мы выбрали эти возможные значения, потому что значения C обычно работают лучше всего, когда они не слишком велики или слишком малы. Если C слишком велик, регуляризация будет очень слабой, и модель может стать очень сложной и переобученной. Если C слишком мал, тогда будет большой объем регуляризации, и данные могут стать недостаточно приспособленными. Используя этот поиск по сетке, мы обнаружили, что значение C, равное 1, было оптимальным для минимизации как потерь журнала, так и ошибки нуля или единицы на проверочном наборе, как показано в разделе 2.2, рисунок 13.
Другой гиперпараметр, который мы рассмотрели, - это максимальное количество итераций, которые должна сойтись решающая программа. Из данных (показанных на рисунке 8) мы увидели, что после нескольких сотен итераций модель всегда могла сходиться, поэтому выбор значения для этого был произвольным.
Рисунок 8: Частота ошибок в базовой модели при увеличении максимального числа итераций для сходимости.
На рисунке 8 показано, что частота ошибок остается постоянной при увеличении максимального числа итераций в классификаторе логистической регрессии.
Еще один параметр, который мы рассмотрели, увеличивают ли штраф L1 или L2 производительность модели.Регрессия лассо (L1) дала нам меньшую частоту ошибок на тестовых данных по сравнению с L2. Вероятно, это связано с тем, что регрессия L1 может привести некоторые веса к 0, чтобы эти функции можно было игнорировать, и поскольку большая часть пиксельных изображений всегда выключена (черная), веса для этих функций можно игнорировать.
2.3 Логистическая регрессия с преобразованием признаков, подгонкой модели и процессом выбора гиперпараметров.
Преобразования функций, которые мы использовали для нашей второй модели, - это преобразование Бокса-Кокса, тип преобразования мощности. Преобразование Бокса-Кокса изменит переменную-предиктор или переменную ответа, а затем подгонит линейную модель к данным, чтобы изучить влияние, которое наша переменная-предиктор оказывает на преобразованный ответ. Это полезно, потому что мы можем предположить, что наша линейная модель имеет нормально распределенные члены ошибок, что снижает ошибки типа I и типа II. Кроме того, преобразование Бокса-Кокса будет поддерживать линейную зависимость между переменной ответа Y и предиктором X, включая меньшую асимметрию. По этим причинам легче делать прогнозы на основе нормализованных данных благодаря избавлению от выбросов. Это работает с нашим набором данных, потому что большая часть данных в любой момент равна 0 (черный). Мы также обнаружили, что использование этого преобразования данных улучшило производительность базового классификатора на проверочном наборе.
Поскольку мы все еще используем классификатор логистической регрессии, мы должны снова настроить C. Как и в случае с базовым классификатором, мы варьировали C в широком диапазоне значений и снова обнаружили, что значение 1 для C было оптимальным (см. Рисунок 9). . Наличие такого значения C гарантирует, что мы не переобучаем или не подгоняем данные из-за регуляризации. Мы также оставили то же самое значение max итераций, чтобы модель могла сойтись. Наконец, мы по-прежнему оставили включенным штраф L1 из-за увеличения производительности. Найдя правильное значение C, мы снова оптимизировали потерю журнала, потому что это минимизирует максимальное значение ошибки.
Рисунок 9: Частота ошибок при логистической регрессии с преобразованием Бокса-Кокса как сила изменений регуляризации.
На рисунке 9 показано, что значение C, которое уменьшает ошибки и потери журнала, составляет около 1, потому что оно применяет соответствующую степень регуляризации и не обеспечивает недостаточную или чрезмерную компенсацию переобучения.
2.4: Случайный лес с преобразованием признаков, подгонкой модели и процессом выбора гиперпараметров.
Для этого нового классификатора мы снова использовали преобразование мощности Бокса-Кокса, поскольку оно обеспечивает более нормальное распределение наших данных, так что наша модель будет более стабильной и точной.
Для этого нового классификатора мы снова использовали преобразование мощности Бокса-Кокса, поскольку оно обеспечивает более нормальное распределение наших данных, так что наша модель будет более стабильной и точной.
Классификатор, который мы выбрали для нашей последней модели, - это классификатор случайного леса. Мы думали, что классификатор случайного леса будет хорошо работать для этого набора данных, потому что случайный лес - это классификатор дерева решений, в котором данные разбиваются на множество различных деревьев. Каждый классификатор (дерево) строится путем объединения различных независимых базовых классификаторов. Независимость применяется путем обучения каждого базового классификатора на обучающем наборе, выбранном с заменой исходного обучающего набора. Затем он определяет лучшую функцию разделения из случайного подмножества доступных функций. Затем весь классификатор объединяет отдельные прогнозы для объединения в окончательный прогноз, основанный на большинстве голосований по отдельным прогнозам. Этот процесс гарантирует, что результат будет более надежным и точным и менее подверженным переобучению. Еще одна причина, по которой классификатор случайного леса был предпочтительнее, заключается в том, что он более легко может обрабатывать данные многих измерений и большого размера. Время выполнения и память были для нас серьезными препятствиями при использовании различных методов предварительной обработки и классификаторов, поэтому простота использования этого классификатора для наших данных является большим преимуществом.
Один гиперпараметр, который мы можем изменить с помощью этого классификатора, - это количество деревьев в лесу. Увеличение количества деревьев даст более точный прогноз с использованием перекрестной проверки и уменьшит вероятность переобучения наших данных. Мы варьировали количество деревьев в диапазоне от небольшого числа, например, от 10 до 1000 деревьев (см. Рисунок 10). Мы сделали это, потому что при больших значениях количество деревьев мало влияло на точность прогноза на проверочном наборе. Используя поиск по сетке, мы обнаружили, что оптимальное количество деревьев - 600, хотя при использовании более 100 деревьев улучшение производительности было очень небольшим.
Рис. 10: Частота ошибок классификатора случайных лесов по мере увеличения количества деревьев.
На рисунке 10 показано, что увеличение количества оценщиков (деревьев) немного снижает потери журнала проверки и частоту ошибок в случайном лесу. Это связано с тем, что чем больше деревьев, тем больше перекрестная проверка и больше учитывается переобучение.
Другими гиперпараметрами, которые мы рассматривали, были минимальное количество выборок, необходимых для разделения внутреннего узла, и минимальное количество выборок, необходимых для того, чтобы быть листовым узлом. Мы пробовали эти значения только в диапазоне от 1 до 10, потому что их значения по умолчанию были 2 и 1 соответственно (см. Рисунки 11 и 12). С помощью поиска по сетке мы обнаружили, что эти значения были оптимальными при значениях по умолчанию, поэтому их оставили в покое.
Рисунок 11: Частота ошибок в классификаторе случайных лесов как минимальное количество выборок для разделения узла.
На рисунке 11 показано, что увеличение количества выборок, необходимых для разделения внутреннего узла, увеличивается, потери журнала обучения и проверки немного увеличиваются.
Рисунок 12: Частота ошибок на классификаторе случайного леса как минимальное количество выборок, которые должны быть конечным узлом.
На рисунке 12 показано, что по мере увеличения количества выборок, необходимых для того, чтобы быть листовым узлом, потери журнала обучения и проверки увеличиваются.
Мы попытались минимизировать двоичную кросс-энтропию при поиске оптимальных гиперпараметров, поскольку двоичная кросс-энтропия является верхней границей частоты ошибок. Минимизация этого значения гарантирует, что мы получим минимально возможное максимальное значение ошибки тестового набора. Коэффициент ошибки ноль один часто совпадает с двоичной кросс-энтропией, поэтому минимизация любого значения дала бы аналогичные результаты.
Раздел 2. Результаты для набора данных Sneaker-Sandal
Рисунок 13: Выбор гиперпараметров в базовой модели.
Чтобы найти доказательства переобучения, мы изменили гиперпараметр c с классификатором линейной регрессии.Поскольку c является мерой, обратной регуляризации, чем больше значение, тем менее регуляризованной будет модель и чем меньше она, тем более регуляризованной она будет. Это означает, что большие значения c соответствуют модели с переобучением, а малые значения c соответствуют модели с недостаточной подгонкой.Эта модель показывает, что значение c, равное примерно 1, является оптимальным, поскольку оно штрафует значения веса достаточно, чтобы не переобучать модель, а также наказывает их достаточно, чтобы модель не была недостаточно подогнанной.
Рис. 14: Кривая ROC для производительности тренировочного и временного набора на всех моделях.
На этом рисунке все три модели хорошо работают с классификацией данных в удерживаемом наборе. Все три модели имеют кривую ROC, которая сразу переходит в верхний левый угол, что означает, что они могут иметь почти все истинные положительные результаты для данного порога, при этом почти не имея ложных срабатываний. Это также можно увидеть, потому что наши модели имеют очень высокие значения AUROC, что означает, что область под кривой ROC является высокой. Классификатор случайного леса простирается дальше к верхнему левому углу на обоих графиках, что означает, что он может дать более точный прогноз для заданного порога. Две другие модели имеют аналогичную производительность, поэтому базовый классификатор скрывает классификатор преобразования Бокса-Кокса.
Рисунок 15: Ложные срабатывания и ложные отрицательные результаты в наборе отложенных результатов для случайных лесных и базовых моделей.
На этом рисунке показаны некоторые ложные срабатывания и ложные отрицания, сделанные классификатором случайного леса и базовым классификатором. Вверху показаны ошибки случайного леса, а внизу - ошибки базового уровня. Из этих рисунков мы видим, что классификаторам было сложно определить кроссовки с контрастными цветами в середине обуви. Обычно сандалии маркируются наличием пустого пространства на верхней части обуви, поэтому кроссовки с черным логотипом на нем, в то время как остальная часть кроссовок белая, могут быть ошибочно идентифицированы как сандалии. С другой стороны, классификатору Random Forest было труднее прогнозировать сандалии, которые в основном имеют закрытые пальцы или твердую форму, что может быть связано с тем, что без явных отверстий в сандалиях они выглядят как кроссовки. У базового классификатора были аналогичные проблемы с идентификацией этого, но в некоторых примерах есть более очевидные возможности.
Рекомендации:
- https://towardsdatascience.com/optimization-loss-function-under-the-hood-part-ii-d20a239cde11