
Итак, в этой статье мы приступаем к вопросу «Как устроена поисковая система?». Чем дальше, тем будет сложнее, если в начале вы не до конца понимали суть информации, отнеситесь к этому как к введению. Сейчас мы уходим глубже и приближаемся к факторам ранжирования. Поговорим сейчас об устройстве поисковой системы. Что такое поисковая система в общем понимании?
Во-первых, поисковые системы (Яндекс, Google, Email) призваны работать прежде всего в мире сайтов. Мы показывали уже скриншоты, и то что поисковику теперь нужно искать внутри пабликов, то есть внутри социальных сетей. Ему нужно находить видеоролики в YouTube или Rutube. Если вы сейчас попробуете с помощью поиска Яндекс. Видео найти какой-то видеоролик, то вы узнаете, что поиск Яндекс. Видео тесно связан с поиском по видео внутри Вконтакте. Он ищет ролики там и т.д.
Особенность и значимость сайта внутри поисковика
Но изначально все это появилось на поле сайтов. Это мир сайтов. Еще более правильно называть это – мир HTML документов. Каждый сайт состоит из страниц. Есть один случай, о котором вы знаете. Это landing page – сайты, состоящие из одной страницы. Здесь мы с вами согласны – это синонимы, сайт это или страница. Мы можем, когда говорим о продвижении, говорить о продвижении сайта. Но привыкайте к тому, что вы, как будущий SEO-шник или специалист, который будет анализировать деятельность SEO-шников. Вы должны мыслить не сайтами, а HTML документами.
Каждая страница внутри сайта имеет право быть погруженной в индексную базу Яндекса. Также она имеет право быть найденной, по каком-то своему ключевому запросу. То есть важна каждая страница внутри сайта. Если вы обладатель большого сайта, то у вас большой потенциал для продвижения. У вас есть много HTML документов, мы можете выйти в ТОП по разным запросам, оптимизировать разные страницы. Если у вас landing page, то да, ваше SEO будет странным. Для оптимизации вам доступна всего одна страница. Да, она главная, но других страниц нет. Это значит, что не так много ключевых запросов, под которые вы ее можете оптимизировать.
Вы очень скоро поймете, что оптимизация сайта, работа с текстами и заголовками – ограничена, не так много туда можно вместить. Если вы, например, сайт Авито, и вам нужно продвижение по 100 тысячам или миллионам поисковых запросах, то если бы у вас был landing page – оптимизация бы не удалась. Вы бы не вывели свою единственную страницу под 100 тысяч запросов. Были бы проблемы. То есть, чем больше семантическое ядро, тем больше список запросов, по которым вы хотите быть в ТОП, тем больше арсенал HTML документов, которые вам доступны для оптимизации.
Как выглядит мир сайтов?
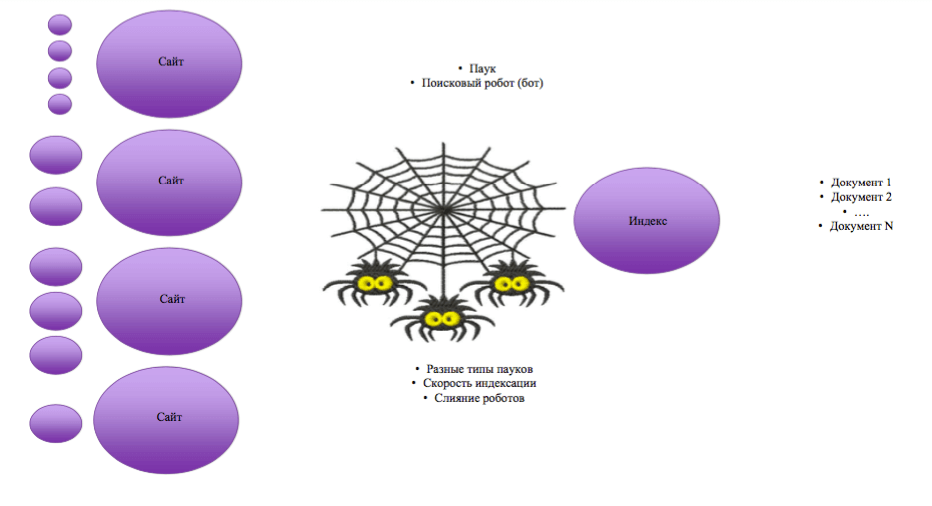
Образно мы нарисовали мир сайтов.
Справа – индексное хранилище. Это та самая невероятная библиотека, в которой Яндекс хранит избранные и лучшие HTML документы, как-то их классифицируя. Как устроено индексное хранилище, можно найти с помощью YouTube. Это видеоролики, где рассказывается, как выглядит Google. Там шуточный ролик, где Google – это библиотека, которая сидит за столом. Вокруг него книги и бумаги. К нему приходят люди и спрашивают. Они задают ему вопросы и Google ищет им документы. Мы бы еще дальше развили эту метафору. Представьте, что это не библиотека, а стеллажи с книгами. Сотни миллиардов HTML документов хранит в своей базе Google. Представьте себе библиотеку с сотней миллиардов книг. Пусть это даже одна страничка. Но каждая страничка отвечает какому-то запросу. Все должно быть хорошенько расставлено.
Как устроено индексное хранилище – это действительно одна из самых сложных частей и наук. Она связана как раз с поисковиком. Там, внутри Яндекс и Google, они думают, как раз об этом: как все правильно и гармонично разложить. Это не удивительно, так как Google потребляет несколько процентов электроэнергии мира. Есть открытая статистика Google по Америке – это более 10% электроэнергии. Компания Google стоит больше, чем вся Россия. Так вот, эта библиотека – это индексное хранилище. Это очень важная и ценная наука, а также емкая вещь. Это мы относимся к поисковику несерьезно: вбили запрос, получили информацию, что-то нам не понравилось, начали выставлять претензии к качеству работы поисковика. На самом деле за доли секунды Яндекс или Google находят в своем хранилище подборку нужных документов. Этих документов могут быть десятки миллионов. Потом располагают их в правильном порядке на странице результатов поиска.
Почитайте обязательно в Яндексе раздел «пауки» - поисковые роботы. Какие они бывают? Пауки разные. Это главное, что мы должны запомнить. То есть разные машины занимаются сбором данных в интернете. Какой-то паук качает твитер, какой-то индексирует паблики Вконтакте, какой-то занимается видеороликами, какой-то переиндексирует старые сайты, какой-то индексирует сайты на новых доменах и т.д. Роботов много, и они движутся с разной скоростью. Они обращаются с разной логикой к сайтам и не только. Дальше они формируют индексное хранилище. В момент, когда роботы собрались, обновили данные, в поисковой системе происходит aпдейт. Индексное хранилище обновляется и когда вы пишите поисковый запрос Яндексу, вы видите новые результаты.
Раньше долгое время SEO-шники выделяли Яндекс как систему, в которой aпдейты происходят раз в определенное время. Раз в 3-4 дня. Сейчас Яндекс все чаще обновляет поисковую выдачу. Роботы бегают быстрее, Яндекс становится совершеннее. Ну, а Google уже давно обновляет индексную базу несколько раз в течение дня. Яндекс долгое время к сайтам новостей, сайтам СМИ, социальным сетям относится так, что он информацию оттуда должен получать в реальном времени. Так вот, роботы бывают разные. Есть такой термин – слияние роботов. Они собираются в какое-то время. Возможно эта эпоха прошла в Яндексе, но других данных у нас нет. После слияния роботов происходит aпдейт, то есть обновляется индексное хранилище поисковика.
Вот хороший пример, который мы вас попросим посмотреть. Откройте Википедию – определение поисковой машины и вы увидите подтверждение наших слов. Три фундаментальных сущности в поисковике: робот или машина, которая собирает данные. Это отличие просто индексной базы от целой системы. То есть это индекс и паук, который попал в этот индекс в режиме реального времени. Индексное хранилище, вот эта библиотека – это база данных, в которой нужно правильно все разместить и сохранить, чтобы внутри этого быстро искать. Пункт номер три в Википедии – это то, о чем мы сегодня будем рассуждать в рамках статьи – это поисковый механизм. Согласно каким принципам поисковик находит эти документы, как он их индексирует, а также какие факторы ранжирования. По какому принципу он определяет, что этот HTML документ будет первый, а этот 999. Факторов ранжирования достаточно много. Именно им посвящены следующие наши статьи.



















