
Почему «просто загрузил фото — получил видео» работает хуже, чем кажется — и как пройти три шага до анимации, чтобы получить управляемый результат.
Все хотят «оживить фото». Загрузил картинку в Kling — получил видео. Да, так тоже работает. Но профессиональный результат начинается раньше — до того, как картинка попадает в нейросеть. Разбираю разницу на цифрах и промтах.
Почему «просто загрузить фото» даёт слабый результат
Image-to-video принимает любую картинку. Но вот в чём проблема: если картинка взята из стока или сделана без техзадания — нейросеть для анимации сама решает, что и как двигать. Результат непредсказуем.
Три кейса из практики (оценочно):
- Фото из стока → движение получилось, но сцена «не та», пришлось переделывать
- Картинка, сгенерированная без сценарного промта → Kling добавил случайное движение → не похоже на задачу
- Полный пайплайн сценарий → промты → картинки → анимация → нужный результат с первой попытки
Разница не в сложности. Разница в управляемости.
Шаг 1-2. Сценарий и промты для кадров — в одном запросе
Экономия времени: не делай два отдельных запроса. Один системный промт сразу даёт нужный формат.
Пример для Claude 4.6 Sonnet или GPT-5.5:
«Ты — сценарист и раскадровщик. Создай 15-секундный рилс для [тема]. Формат ответа строго: Кадр 1: [описание сцены, 1-2 предложения] → [промт для генерации картинки на английском, 50+ слов, укажи: освещение, ракурс, стиль, настроение]. Кадров: 3.»
Один запрос — сценарий и промты для всей раскадровки. Почему это работает лучше, чем спрашивать по частям: Промпт — это не запрос. Вот почему вы всё делаете неправильно.
Шаг 3. Картинки под анимацию: три правила
Nano Banana в Сабка ПРО даёт нужный контроль — если знать, что прописывать в промте.
Правило 1. Один главный объект движения. Слишком плотная сцена — нейросеть для анимации не знает, что анимировать. Один объект на первом плане, остальное — фон.
Правило 2. Закладывай движение уже в промт для картинки. «Волосы развеваются на ветру», «пар поднимается над чашкой» — это подсказки для аниматора. Kling читает контекст и следует логике изображения.
Правило 3. Единый стиль на серию. Один тег на все кадры: «cinematic, warm golden tones, shallow depth of field» — и кадры выглядят как части одного ролика, а не случайный коллаж.
Подробнее о работе с Nano Banana: Как пользоваться Gemini и Nano Banana (официально, на русском).
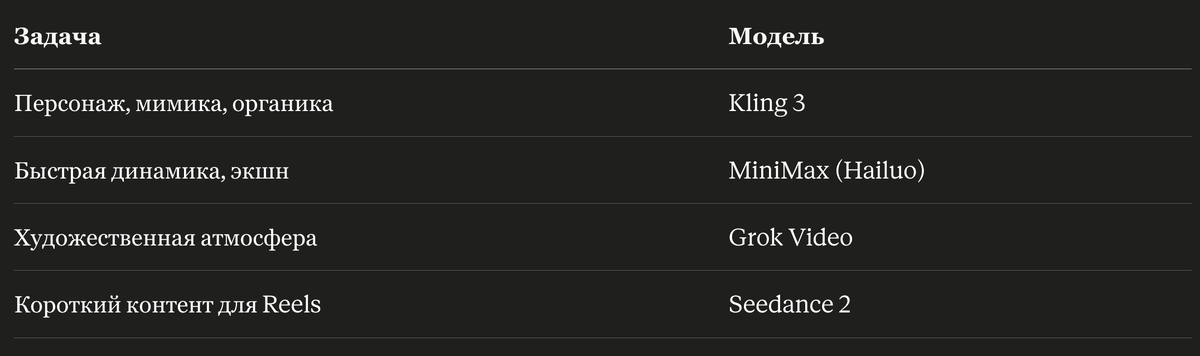
Шаг 4. Анимация: какую модель выбрать и как писать промт
Image-to-video — это режиссёрская задача. Ты описываешь движение, а не «жми кнопку».
Формула промта: субъект движения + характер движения + поведение камеры.
Примеры промтов для анимации:
- «Пар поднимается над чашкой. Камера медленно сближается.»
- «Листья дрожат на ветру. Золотой свет мигает. Камера статична.»
- «Девушка поднимает взгляд. Слабая улыбка. Камера не двигается.»
3 кадра × 5 секунд = 15-секундный рилс. Готово.
Весь стек — текстовые модели, Nano Banana, Kling, MiniMax — в Sabka Pro без VPN и в рублях. Мультичат работает только для текстовых нейросетей: картинки и видео выбираешь вручную. Какую модель брать под какую задачу видеорилса — разбирается в Claude vs Gemini: кто сделает рилс для Инсты?.
Разница между «загрузил фото» и «прошёл пайплайн» — как между «примерно» и «именно так». Те, кто прошёл всё четыре шага хотя бы раз, обратно не возвращаются.