
После миграции СУБД для «1С:Предприятие» с Postgres Pro Enterprise 15.14.1 на Postgres Pro Enterprise 17.9.2 возник непрогнозируемым дефицит дисковой подсистемы: показатель iowait резко возрос, процессорное время выполнения запросов увеличилось в несколько раз, при этом штатные диагностические отчёты не позволили установить непосредственную причину. Предпринятое расследование, длившееся несколько недель, выявило не регрессионное нарушение в целевой версии, а две независимые проблемы: во-первых, ошибку планировщика, индуцированную активированным по умолчанию параметром planner_upper_limit_estimation = on и усугублённую совместным влиянием autoprepare_threshold и отключённого online_analyze; во-вторых, классическое истощение буферного кэша при фиксированном значении shared_buffers на фоне возросшей рабочей нагрузки. В статье представлена хронология диагностических мероприятий, опиравшихся на инструмент pgpro_pwr, методологию PG_EXPECTO и верификацию с привлечением нейросетевых моделей, а также приведены конкретные параметры конфигурации, рекомендуемые к проверке администраторам, планирующим или уже осуществившим аналогичное обновление.
Для диагностики использовались:
- pgpro_pwr — расширение для сбора и анализа статистики производительности PostgreSQL, формирующее детальные отчёты по нагрузке, ожиданиям, планам запросов;
- PG_EXPECTO — доменная методология анализа, предписывающая проверять внутреннюю согласованность метрик, разделять подтверждённые факты и гипотезы, явно указывать границы применимости выводов;
- философская инструкция для нейросетевой модели DeepSeek, обеспечивающая эпистемическую честность: каждый вывод снабжался уровнем достоверности («Подтверждено данными», «Вероятно, но требует проверки», «Предположение», «Невозможно оценить»).
- Коллекция промптов для нейросети DeepSeek (на русском языке), предназначенных для анализа и оптимизации производительности СУБД PostgreSQL.
Глава 1. После апгрейда: процессорное время ×5 при тех же планах
Первая проблема с аномальной утилизацией CPU/IO после обновления версии.
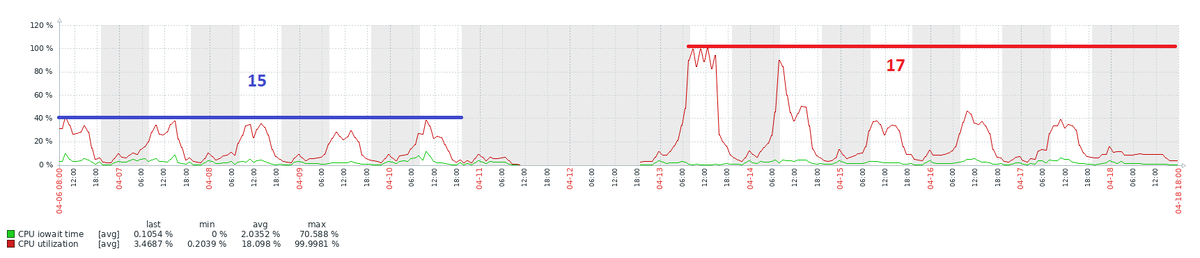
Рис.1 Графики метрик Zabbix: "CPU iowait time" и "CPU Utilization" - до и после обновления версии СУБД (СУБД-1)
Сравнение двух отчётов pgpro_pwr — до обновления (PG 15) и после (PG 17) — выявило картину, далёкую от ожидаемой:
- общее количество выполненных запросов выросло на 20% (с 33,7 млн до 40,4 млн);
- однако суммарное время выполнения подскочило в 2,6 раза (с ~5 094 с до ~13 462 с);
- процессорное время (сумма user + system) увеличилось более чем в 5 раз — с ~5 550 с до ~31 134 с;
- пиковое число сессий в новом периоде достигало 1 317 (против 435 ранее), при этом параметр max_connections был установлен в экстремальные 5 000.
Конфигурационные параметры, влияющие на кэширование и стоимость доступа (shared_buffers = 55 ГБ, effective_cache_size = 165 ГБ, random_page_cost = 1.1), остались неизменными.
Но были и различия:
- work_mem удвоился (с 32 МБ до 64 МБ),
- max_parallel_workers_per_gather в обоих случаях, по-видимому, был отключён или близок к нулю.
ℹ️Проблемные запросы сохранили свои паттерны: частые вызовы SELECT FASTTRUNCATE для очистки временных таблиц (до 1,2 млн раз в час), операции с таблицей BinaryData (чтение и вставка BLOB-объектов), активное использование временных файлов (16 ГБ в новом периоде). Но их «цена» в терминах процессорного времени резко возросла. Так, один только запрос FASTTRUNCATE в новом периоде потреблял 37,7% всего CPU, хотя вызывался в 2,4 раза реже, чем в старом.
Первичный вывод (Уровень‑2):
Деградация, скорее всего, связана с изменением поведения оптимизатора или конкуренцией за ресурсы на фоне возросшего числа сессий. Но для точного ответа требовался анализ конкретных планов выполнения.
Корневая причина - не установлена.
️Утилизация со временем относительно нормализовалась.
Глава 2. Планы стабильны, но физические чтения выросли в разы — первый признак системной причины
Повторение проблемы - аномальная утилизация CPU/IO после обновления версии .
📋На этот раз принято решение - провести глубинный сводный анализ проблемы с целью установить причину и запланировать мероприятия для следующих обновлений.
Рис.2 Графики метрик Zabbix: "CPU iowait time" и "CPU Utilization" - до и после обновления версии СУБД (СУБД-2)
📋Начало анализа:
- 5 запросов, лидировавших по времени выполнения,
- 12 запросов, доминировавших по времени ожидания ввода-вывода.
ℹ️Поскольку после обновления идентификаторы Query ID изменились, пришлось искать текстовые соответствия между отчётами.
Время выполнения :
Сравнительный анализ раздела "Total exec time"
- Запрос с _InfoRg12488 (LIMIT + ORDER BY): план улучшился — вместо Bitmap Heap Scan стал чаще выбираться прямой Index Scan. Среднее время одного вызова сократилось с 255 мс до 19,5 мс, но частота вызовов выросла в 39 раз (с 777 до 30 185). Общее время увеличилось, но не критично.
- Запрос с _Reference109 (OR по двум полям): частота выросла в 105 раз (с 15 до 1 580), план остался Seq Scan, и запрос стал главным потребителем CPU (1 197 с user_time).
- Запросы с _InfoRg15516 и _Reference15235 показали катастрофический рост: при неизменном Seq Scan и небольшом числе вызовов среднее время взлетело с 0,33 с до 20,9 с и с 37 мс до 23,7 с соответственно. Причина — многократный рост объёмов данных при отсутствии индексов по фильтруемым полям.
Ожидания I/O :
Сравнительный анализ раздела "Top SQL by I/O wait time"
ℹ️Из 12 проанализированных запросов 11 продемонстрировали рост времени DataFileRead от 1,6 до 32 раз при неизменных или даже снизившихся количествах вызовов.
ℹ️Планы выполнения для них не изменились.
Например:
- INSERT в _InfoRg16813: при снижении числа вызовов на 12% общее время выросло в 2,5 раза, а время I/O — с 27,4 с до 84,2 с;
- INSERT в _InfoRg12488: общее время выросло в 5 раз (с 4,5 с до 22,9 с) при практически неизменном числе вызовов;
- SELECT из _Reference109 по первичному ключу: в новом периоде оптимизатор переключился на менее эффективный индекс (_reference109_no_pkey вместо _reference109ng_pkey1), что привело к росту прочитанных блоков с 2 292 до 34 526 и времени I/O с 0,11 с до 28,49 с.
Лишь один запрос (SELECT из _InfoRg13163) не показал деградации — он полностью обслуживался из кеша (I/O time = 0 в обоих периодах).
Вывод (Уровень‑1):
️Ключевой фактор замедления — многократный рост физических чтений с диска. Планы в основном не изменились, значит, причина не в регрессе оптимизатора, а в изменившихся условиях выполнения.
Но почему планы «поплыли» для отдельных запросов?
Ответ дал следующий этап.
⬇️
Глава 3. Поворотный момент: +3300% сбросов кэша — ключ к механизму
Изучение раздела «Load distribution among heavily loaded databases» вскрыло аномалию, которая переопределила направление расследования.
️Счётчик cache_resets (сбросов разделяемого кеша) в представлении pgpro_stats_totals увеличился с 1 до 34 событий за час — то есть на 3300%.
Одновременно:
- время ввода-вывода (I/O time) выросло на 2310%;
- объём физических чтений (Shared blocks read) — на 248%;
- общее время выполнения (Total time) — на 536% при снижении числа запросов на 10%.
ℹ️Метрика cache_resets фиксирует принудительные очистки кеша планов (и/или буферов), вызванные такими событиями, как DISCARD ALL, ALTER SYSTEM, SET, DDL-команды или аварийные перезапуски обслуживающих процессов. Каждый такой сброс обнуляет накопленную статистику и заставляет планировщика заново строить планы, часто на основе устаревших данных.
Возникла гипотеза № 3: что-то в новой конфигурации заставляет сервер регулярно терять кеш планов.
Глава 4. Двойная верификация: как тандем autoprepare_threshold и online_analyze методично вымывает кэш планов
Сравнение всех конфигурационных параметров между старым и новым периодами выявило три ключевых отличия, не считая уже известных:
- autoprepare_threshold: 0 → 2 (включена автоматическая подготовка общих планов);
- online_analyze.enable: on → off (отключено автоматическое обновление статистики при DML-операциях);
- generic_plan_fuzz_factor: 1 → 0.9.
Чтобы подтвердить их причастность, был проведён двойной анализ — с помощью DeepSeek и специализированной нейросети «Ask Postgres».
ℹ️Обе системы независимо пришли к одному и тому же механизму:
- При autoprepare_threshold = 2 сервер начинает кешировать общие (generic) планы в локальной памяти каждого обслуживающего процесса (бэкенда) — после второго выполнения одного и того же шаблона запроса с разными литералами. При значении 0 кеш был пуст, и сбрасывать было нечего.
- При online_analyze.enable = off статистика таблиц перестала обновляться немедленно после INSERT/UPDATE/DELETE. Теперь она обновляется только фоновым autovacuum, причём массово — когда накапливается порог изменений (по умолчанию 10% таблицы + 50 строк). Каждый такой ANALYZE изменяет содержимое системного каталога pg_statistic, что для PostgreSQL служит триггером инвалидации всех кешированных планов, зависящих от изменённых таблиц. В результате кеш, наполненный благодаря autoprepare_threshold, периодически полностью очищается — отсюда и взрывной рост cache_resets.
- generic_plan_fuzz_factor = 0.9 добавляет «допуск» при сравнении стоимости общего и специализированного планов, делая планировщик более консервативным. В сочетании с устаревшей статистикой это приводит к тому, что единственным способом получить новый план становится полный сброс кеша.
️Таким образом, активация автоподготовки создала сам объект для сбросов, а отключение online_analyze обеспечило регулярный триггер для них.
Но оставался вопрос: почему после сброса кеша планировщик стал выбирать заведомо неоптимальные последовательные сканирования?
Ответ нашёлся в ещё одном новом параметре PostgreSQL 17.
⬇️
Глава 5. Прорыв: planner_upper_limit_estimation = on — главный виновник Seq Scan и лавины чтений
Параметр planner_upper_limit_estimation (boolean), появившийся в Postgres Pro 17, по умолчанию равен off. Однако в конфигурации после апгрейда он оказался включён (on).
ℹ️Согласно документации, он «включает возможность планировщика запросов завышать оценку ожидаемого количества строк в выражениях, содержащих сравнение с неизвестной константой».
Проще говоря, для условий, по которым нет статистики, планировщик применял поправочный коэффициент, искусственно занижая селективность.
️Для проверки влияния были поставлены натурные эксперименты :
Параметр отключили (off) и сняли два новых часовых отчёта (периоды 69–71 и 74–76).
Рис.3 Графики метрик Zabbix: "CPU iowait time" и "CPU Utilization" - до и после обновления версии СУБД при разных значениях параметра planner_upper_limit_estimation
Результаты превзошли все ожидания:
- Total time — с 76 563 с до 19 963 с (–73,9%);
- I/O time — с 45 356 с до 7 962 с (–82,4%);
- Blocks fetched — с 4,36 млрд до 2,04 млрд (–53,1%);
- Shared blocks read — с 532 млн до 155 млн (–70,9%);
- Cache resets — с 289 до 10 (–96,5%);
- Executed count — с 11,95 млн до 13,43 млн (+12,4%).
ℹ️Сравнение планов выполнения показало: при on для ключевого запроса к _InfoRg12488 использовался Seq Scan, а после переключения в off — Bitmap Heap Scan и Index Scan. Доля последовательных сканирований в общем числе операций доступа снизилась с 19,2% до 16,5%. При этом количество индексных сканирований практически не изменилось, зато резко упало количество строк, возвращаемых через индексы (IxFet — на 43,9%). Это означало, что планировщик стал точнее оценивать стоимость и отказывался от избыточных чтений.
Вывод (Уровень‑1): planner_upper_limit_estimation = on был главным виновником первоначальной деградации. Он заставлял планировщика систематически недооценивать селективность условий без статистики, выбирая неоптимальные последовательные сканирования.
В сочетании с частыми сбросами кеша (из-за autoprepare_threshold и online_analyze) это создавало порочный круг: статистика терялась → планировщик ошибался → данные читались с диска → кеш вымывался ещё быстрее.
Глава 6. Вторая волна: hit ratio рухнул с 95% до 86% без единого изменения конфигурации — shared_buffers больше не справляется
После отключения проблемных параметров острая фаза была снята, но через некоторое время на том же сервере вновь зафиксировали аномальную утилизацию диска:
Сравнение периодов 165–166 и 170–171 (уже на PG 17 с planner_upper_limit_estimation = off) показало иную картину: при полностью идентичной конфигурации и стабильных планах запросов (12 из 13 основных запросов сохранили планы) наблюдалось:
- Hit ratio кластера упал с 95,2% до 86,3% (на DB‑4 — с 95,1% до 86,2%);
- Ожидания DataFileRead выросли в 3,9 раза и стали занимать 63,8% всех ожиданий (5 828 с против 1 479 с);
- Ожидания BufferIo (конкуренция процессов за одни и те же буферные страницы) взлетели в 126 раз (с 2,75 с до 347,9 с);
- Количество выполненных запросов выросло на 39% (с 4,74 млн до 6,61 млн), а общее время — в 4,3 раза (с 6 228 с до 26 856 с);
- Объём временных файлов (Temp blocks written) увеличился на 82%.
Размер shared_buffers при этом оставался неизменным — около 12,3 ГБ. Рабочий набор данных вырос и перестал помещаться в буферный кеш, что привело к массовому вытеснению страниц и физическому чтению с диска.
️Планы не изменились — замедление было вызвано исключительно нехваткой буферного пула.
Дополнительно work_mem в 32 МБ при максимальном числе подключений 1 000( создавал риск, что множество одновременных сортировок и хеш-соединений будут сбрасываться на диск во временные файлы. Рост Temp blocks written на 82% косвенно подтверждал эту гипотезу.
ℹ️Таким образом, вторая волна проблем имела принципиально иную природу: не ошибка планировщика, а истощение ресурсов при росте нагрузки.
Как одна фраза в промпте к DeepSeek чуть не увела расследование в сторону
Отдельного внимания заслуживает побочное, но важное исследование:
Влияние семантики инструкций для нейросети DeepSeek на результаты анализа.
Сравнивались две версии промпта:
- v1: содержала жёсткое допущение «характер нагрузки кардинально не изменился»;
- v2: без такого допущения, более нейтральная.
Результаты показали, что v1 систематически склонял модель к подтверждению заранее выдвинутой гипотезы, игнорируя или принижая альтернативные объяснения. Например, для запроса _InfoRg13163 отчёт v1 интерпретировал изменения как умеренное улучшение, в то время как v2 зафиксировал, что Seq Scan, присутствовавший в старом периоде, исчез в новом — то есть план формально улучшился, но v1 этого не отметил, фокусируясь на подтверждении общей деградации.
Вывод: прайминг-эффект реален, и при использовании ИИ-ассистентов в диагностике критически важно тестировать промпты на устойчивость и избегать неявных предположений.
Глава 7. Итоги: две независимые проблемы — один чеклист для DBA
Расследование показало, что аномальная дисковая утилизация после миграции была вызвана двумя независимыми, но наложившимися проблемами.
Проблема 1: ошибка планировщика (сразу после апгрейда)
☑️Корневая причина: planner_upper_limit_estimation = on — завышение оценки селективности для условий без статистики, приводившее к выбору Seq Scan.
ℹ️Усугубляющие факторы: autoprepare_threshold = 2 создал кеш планов, online_analyze.enable = off вызывал массовые ANALYZE и, как следствие, частые сбросы этого кеша (cache_resets +3300%). generic_plan_fuzz_factor = 0.9 усилил эффект.
️Решение:
- Установить planner_upper_limit_estimation = off.
- Включить online_analyze.enable или тщательно настроить пороги autovacuum_analyze_scale_factor и autovacuum_analyze_threshold для минимизации времени жизни устаревшей статистики.
- Рассмотреть увеличение autoprepare_threshold (например, до 10), чтобы в кеш попадали только действительно частые запросы.
- Статус: подтверждено прямыми измерениями (Уровень‑1).
Проблема 2: истощение ресурсов при росте нагрузки (отсроченная)
☑️Корневая причина: фиксированный shared_buffers (~12,3 ГБ) перестал вмещать рабочий набор данных, что привело к падению hit ratio с 95,2% до 86,3% и взрывному росту физических чтений.
ℹ️Сопутствующие факторы: work_mem = 32 МБ при высокой конкурентности (max_connections = 1000) вызывал активное использование временных файлов; рост объёмов данных увеличил генерацию WAL.
Решение:
- Увеличить shared_buffers с учётом доступной оперативной памяти (например, до 24–36 ГБ, если оборудование позволяет).
- Рассмотреть увеличение work_mem (например, до 64–128 МБ), но с осторожной оценкой пикового потребления памяти: при 1 000 одновременных активных запросов увеличение work_mem на 32 МБ может потребовать дополнительно 32 ГБ ОЗУ в худшем случае. Рекомендуется мониторинг фактического использования и, возможно, ограничение параллелизма на уровне пула соединений.
- Актуализировать effective_cache_size пропорционально новому shared_buffers (обычно ~75% от общего объёма ОЗУ).
- Обеспечить регулярный мониторинг hit ratio, wait events и временных файлов для предотвращения повторной деградации.
- Статус: hit ratio и ожидания подтверждены прямыми измерениями (Уровень‑1); роль work_mem — вероятна (Уровень‑2).
Вместо заключения: пять уроков миграции, которые сэкономят недели
- Новые параметры — зона риска. Появившиеся в новой версии настройки планировщика (planner_upper_limit_estimation) не должны приниматься «как есть», даже если они рекомендованы документацией. Обязательно нагрузочное тестирование на копии продуктивной среды с профилированием планов запросов и системных метрик I/O.
- autoprepare_threshold и online_analyze — опасная комбинация. Если вы включаете кеширование общих планов, убедитесь, что статистика обновляется достаточно часто, чтобы избежать лавины cache_resets. Отключение online_analyze в высоконагруженных системах требует компенсации через агрессивный autovacuum.
- pgpro_pwr + PG_EXPECTO + нейросеть = мощный инструмент, но требующий дисциплины. Формулировки промптов влияют на объективность выводов — необходимо перекрёстное тестирование гипотез и явная фиксация уровней достоверности.
- Недостаточность буферного кеша может имитировать регрессию версии. Рост рабочих данных требует периодического пересмотра shared_buffers и work_mem, особенно в системах без регулярного реконфигурирования.
- Смотрите на систему в целом. Проблема редко имеет одну причину. В данном случае сошлись сразу несколько факторов: новый параметр планировщика, отключённая статистика, включённая автоподготовка, а позже — просто нехватка памяти под возросшую нагрузку.
Итог
ℹ️История этого расследования — хороший пример того, как систематический анализ метрик, поэтапная проверка гипотез и грамотное привлечение автоматизированных средств позволяют докопаться до истинных причин деградации.
Оказалось, что «новая версия во всём виновата» — слишком грубое упрощение.
Реальная картина включила в себя несколько наслоившихся факторов, каждый из которых потребовал своего метода обнаружения.
Именно комплексный подход — от высокоуровневых профилей к точечному сравнению планов, от конфигурационных параметров к событиям ожидания и hit ratio — позволил не только найти корень проблемы, но и выработать конкретные, работающие рекомендации.
ℹ️Ограничения. Представленные выводы основаны на данных конкретной инсталляции (Postgres Pro Enterprise, платформа «1С»). Абсолютные значения параметров (shared_buffers, work_mem) приведены для иллюстрации и должны адаптироваться под ваше оборудование и профиль нагрузки. Все рекомендации уровня «Вероятно» требуют проверки в тестовой среде перед внедрением в продуктив.