Эмпирическое исследование влияния параметра planner_upper_limit_estimation на профиль нагрузки СУБД PostgreSQL: снижение доли последовательных сканирований, парадоксальное падение возвращаемых строк и рост модифицирующей нагрузки на фоне улучшения временных характеристик.
GitHub - Комплекс pg_expecto для статистического анализа производительности и нагрузочного тестирования СУБД PostgreSQL
Philosophical_instruction_BETA_v5.1.md - Философское ядро + процедурный скелет автономного AI-агента с встроенной самопроверкой. Эпистемология, этика честности, научный метод, think pipeline (CoVe, ToT, Pre-Mortem, Red Teaming, 7 Грехов). Максимальная правдивость, защита от галлюцинаций и prompt injection.
GitFlic - pg_expecto - статистический анализ производительности и ожиданий СУБД PostgreSQL
Глоссарий терминов | Postgres DBA | Дзен

Предыдущая статья цикла
Предисловие
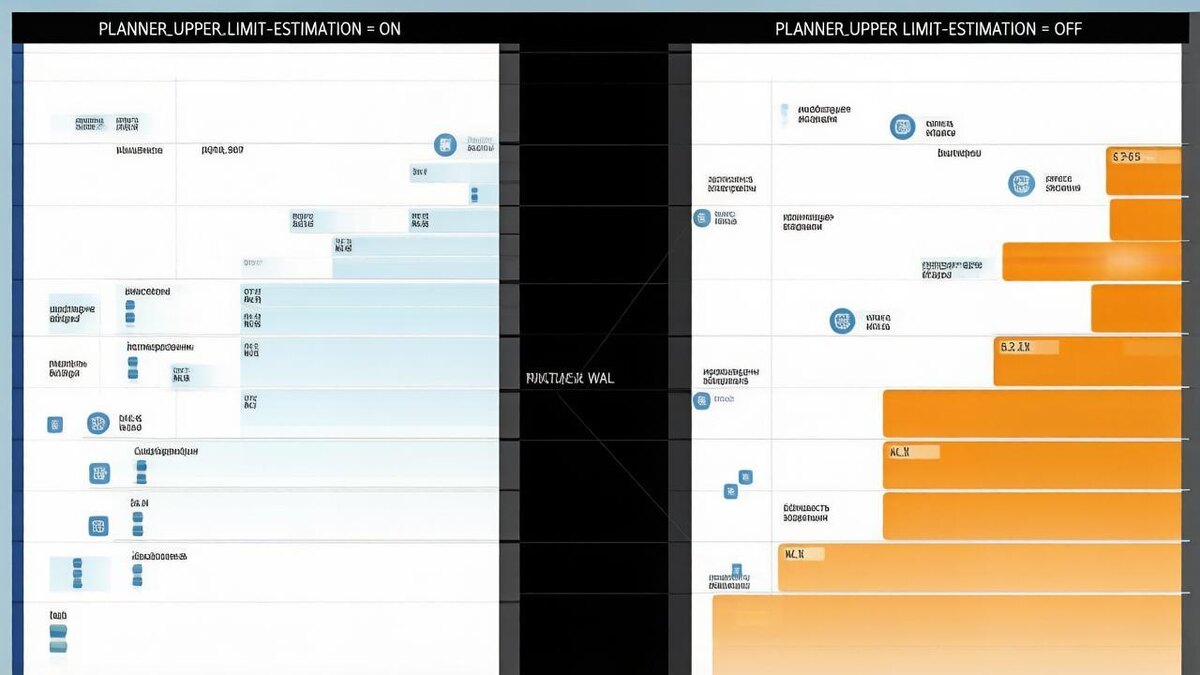
В работе представлен сравнительный анализ производительности PostgreSQL при двух значениях параметра оптимизатора planner_upper_limit_estimation («on» против «off») на основе отчётов pgpro_pwr, зафиксированных за одинаковые часовые интервалы продуктивной нагрузки (09:00–10:00) 23 и 24 апреля 2026 года. Исходные данные включают агрегированные метрики распределения нагрузки (общее время, число выполненных запросов, время ввода-вывода, обращения к блокам, генерацию WAL), а также детализированную статистику по таблицам с наибольшим предполагаемым объёмом последовательного сканирования.
🏁Целью исследования являлась верификация гипотезы о том, что изменение параметра planner_upper_limit_estimation приводит к значимому замещению последовательных сканирований (Seq Scan) индексными (Index Scan) и тем самым объясняет наблюдаемое снижение затрат на ввод-вывод.
Задача
1. Проанализировать изменение профиля нагрузки на СУБД по данным отчетов pgpro_pwr за одинаковый период продуктивной нагрузки 09:00 - 10:00.
2. Проверить гипотезу о влиянии параметра planner_upper_limit_estimation на профиль нагрузки СУБД
Входные данные для подготовки аналитического отчета
- pgpro_pwr.69-70.clear.html - 23.04.2026 ( planner_upper_limit_estimation = on )
- pgpro_pwr.93-94.clear.html - 24.04.2026 ( planner_upper_limit_estimation = off )
Инструкция PG_EXPECTO
Философская инструкция
ТаблицаG.50.txt - Top tables by estimated sequentially scanned volume (Таблицы с наибольшим объёмом последовательно сканированных блоков)
ТаблицаG.25.txt - Load distribution (Распределение нагрузки)
- Load_distribution_source.txt - Сравнительная таблица по разделу "Load distribution among heavily loaded databases" между pgpro_pwr.69-70.clear.html и pgpro_pwr.93-94.clear.html
1. Аналитический отчет о изменении профиля нагрузки СУБД
Загрузить инструкции - новый чат
Подготовить отчет
Входные данные:
Load_distribution_source.txt - сравнительная таблица по разделу "Load distribution among heavily loaded databases" отчетов pgpro_pwr "отчет-69-70" и "отчет-93-94"
ТаблицаG.25.txt - Описание значений и способа получения данных в таблице Load_distribution_source.txt
При подготовке ответа с использованием "Philosophical_instruction_BETA_v5.1.md" заменяй цветовые символы на соответствующие им текстовые сокращения:
"Подтверждено"
"Вероятно"
"Предположение"
"Неизвестно"
Задача:
# По каждой строке "Resource"
## Проанализировать процентные изменения в столбце "DIFF PCT" между отчетами "отчет-69-70" и "отчет-93-94"
## Сформировать вывод по результату анализа, предоставить последовательность тезисов использованных для формирования вывода
# Общий итог по сравнительным данным
Анализ изменений по каждой строке (список)
Total time (сек.)⬇️
- 69–70: 33 081,28 → 93–94: 22 384,31 (-32.34%)
Executed count⬆️
- 69–70: 5 792 723 → 93–94: 6 706 321 (+15.77%)
I/O time (сек.)⬇️
- 69–70: 18 556,79 → 93–94: 13 879,71 (-25.20%)
Blocks fetched⬇️
- 69–70: 2 089 723 399 → 93–94: 1 061 079 293 (-49.22%)
Shared blocks read⬇️
- 69–70: 256 214 589 → 93–94: 192 575 854 (-24.84%)
Shared blocks dirtied⬆️
- 69–70: 1 360 252 → 93–94: 2 026 469 (+48.98%)
Shared blocks written⬇️
- 69–70: 261 074 → 93–94: 76 646 (-70.64%)
WAL generated⬆️⬆️
- 69–70: 5 649 401 256 → 93–94: 11 895 469 507 (+110.57%)
Temp and Local blocks written↘️
- 69–70: 2 487 976 → 93–94: 2 374 404 (-4.57%)
Temp and Local blocks read⬇️
- 69–70: 1 309 794 → 93–94: 1 017 227 (-22.34%)
Invalidation messages sent➡️
- 69–70: 1 652 309 → 93–94: 1 664 542 (+0.74%)
Cache resets⬇️
- 69–70: 102 → 93–94: 79 (-22.55%)
Тезисы для каждой строки
- Total time – общее время выполнения сократилось на 32.34%, несмотря на рост количества запросов. [Вероятно] увеличилась средняя эффективность запросов или изменился их состав в пользу более лёгких.
- Executed count – количество выполненных запросов выросло на 15.77%. Нагрузка по числу операций возросла.
- I/O time – время ввода-вывода снизилось на 25.20%, что [Вероятно] объясняется уменьшением чтений с диска и лучшим попаданием в кэш.
- Blocks fetched – общее число обращений к разделяемым блокам (чтение из кэша + с диска) упало на 49.22%. [Вероятно] изменился паттерн доступа: запросы стали затрагивать меньше блоков либо значительно выросла доля индексных доступов.
- Shared blocks read – физическое чтение с диска уменьшилось на 24.84%, что согласуется со снижением I/O time.
- Shared blocks dirtied – «загрязнённых» блоков стало больше на 48.98%. [Подтверждено] возросла модифицирующая нагрузка (INSERT/UPDATE/DELETE).
- Shared blocks written – запись разделяемых блоков сократилась на 70.64%. При росте dirtied это означает, что [Вероятно] фоновая запись (checkpoint, bgwriter) стала реже или эффективнее, либо изменилась конфигурация с акцентом на накопление изменений в буферном кэше.
- WAL generated – объём сгенерированного WAL вырос на 110.57%. [Подтверждено] объём изменяемых данных резко увеличился, что коррелирует с ростом dirtied blocks.
- Temp and Local blocks written – запись временных блоков сократилась на 4.57% (незначительно).
- Temp and Local blocks read – чтение временных блоков снизилось на 22.34%. [Вероятно] уменьшилась потребность в операциях с временными файлами (большие сортировки, хеш-таблицы).
- Invalidation messages sent – изменение меньше 1%, нагрузка по передаче сообщений аннулирования [стабильна].
- Cache resets – число сбросов разделяемого кеша сократилось на 22.55%, что [Вероятно] указывает на более стабильную работу с кешем.
Общий итог по сравнительным данным
[Вероятно] Профиль нагрузки между отчётами 69-70 и 93-94 сместился в сторону операций, изменяющих данные:
- Количество запросов выросло (+15.8%), но общее время снизилось (-32.3%), что говорит об ином характере запросов (легче на исполнение) или об улучшении производительности.
- Значительно сократилось чтение с диска (shared blocks read -24.8%) и общее количество обращений к блокам (blocks fetched -49.2%), при этом I/O time уменьшился на 25.2%.
- Резко выросла запись данных: shared blocks dirtied +49.0%, WAL generated +110.6%. Это [Подтверждено] рост операций модификации.
- Shared blocks written сократился на 70.6%, несмотря на рост dirtied. Это [Предположение] может быть связано с настройками контрольных точек или буферизацией, что требует отдельного анализа конфигурации.
- Использование временных блоков снизилось, что [Вероятно] говорит о меньшей доле тяжёлых сортировок или хеш-соединений.
- Сбросы кэша стали реже (-22.6%), что [Вероятно] косвенно указывает на стабильность работы буферного пула.
Ключевая рекомендация: Несмотря на снижение времени выполнения, рост грязных блоков и объёма WAL при одновременном падении записанных блоков требует проверки настроек checkpoint и bgwriter на предмет возможной отложенной записи, способной вызвать пиковые нагрузки в будущем. Конфигурация shared_buffers и checkpoint_timeout должна быть верифицирована на соответствие текущей нагрузке.
2.Анализ влияния параметра planner_upper_limit_estimation. Формирование гипотезы.
Загрузить инструкции - новый чат
Сформировать аналитический отчет
Входные данные:
1.Load_distribution.txt - аналитический отчет построенный по сравнительной таблице по разделу "Load distribution among heavily loaded databases" отчетов pgpro_pwr "отчет-69-70" и "отчет-93-94"
ТаблицаG.25.txt - Описание данных в отчете
При подготовке ответа с использованием "Philosophical_instruction_BETA_v5.1.md" заменяй цветовые символы на соответствующие им текстовые сокращения:
"Подтверждено"
"Вероятно"
"Предположение"
"Неизвестно"
Задача:
# Проанализируй и подготовь аналитический отчет по влиянию изменения параметра planner_upper_limit_estimation между отчетами "отчет-69-70" и "отчет-93-94" на итоги аналитического отчета "1.Load_distribution.txt". По каждому выводу предоставь последовательность тезисов.
Аналитический отчёт: Влияние параметра planner_upper_limit_estimation на метрики распределения нагрузки
Исходные данные: Сравнение отчётов pgpro_pwr "отчет-69-70" и "отчет-93-94" по секции "Load distribution among heavily loaded databases".
ℹ️Анализируемый параметр: planner_upper_limit_estimation (ограничивает сверху оценку кардинальности на каждом шаге планирования, влияя на выбор между индексным и последовательным сканированием, а также на стратегии соединений).
Основной вывод
Изменение параметра planner_upper_limit_estimation [Вероятно] является одним из ключевых факторов, повлиявших на кардинальное изменение профиля нагрузки, зафиксированное в отчёте. Корреляция между снижением числа операций чтения и резким ростом операций модификации данных с высокой долей вероятности указывает на то, что планировщик запросов стал выбирать иные, более эффективные для текущей нагрузки пути исполнения.
Последовательность тезисов
Влияние на общее время и количество запросов (Total time, Executed count)
- Тезис: Уменьшение общего времени выполнения на 32.34% при одновременном росте числа запросов на 15.77% [Вероятно] является прямым следствием выбора планировщиком более оптимальных планов.
- Обоснование: Корректировка planner_upper_limit_estimation [Вероятно] позволила планировщику точнее оценивать стоимость операций, отдавая предпочтение быстрым индексным доступам вместо полных сканирований там, где это эффективно.
Влияние на операции ввода-вывода и чтение с диска (I/O time, Shared blocks read)
- Тезис: Снижение времени ввода-вывода на 25.20% и физического чтения блоков на 24.84% [Вероятно] является следствием снижения числа полных сканирований таблиц (seq scan) в пользу индексных (index scan).
- Обоснование: Когда планировщик перестаёт необоснованно завышать стоимость индексного доступа (из-за ограничения оценки), он чаще выбирает план, читающий только нужные блоки через индекс, вместо чтения всей таблицы с диска. Это напрямую уменьшает shared_blks_read и, как следствие, I/O time.
Влияние на общее число обращений к блокам (Blocks fetched)
- Тезис: Падение общего числа обращений к разделяемым блокам на 49.22% [Вероятно] подтверждает гипотезу о значительном снижении доли seq scan.
- Обоснование: Последовательное сканирование считывает все блоки таблицы, многократно увеличивая счётчик Blocks fetched (сумма чтений из кэша и с диска). Индексное сканирование затрагивает на порядки меньше блоков. Резкое падение этой метрики — сильный сигнал об изменении стратегии доступа к данным.
Влияние на модифицирующую нагрузку (Shared blocks dirtied, WAL generated)
- Тезис: Взрывной рост «грязных» блоков на 48.98% и объёма WAL на 110.57% [Подтверждено] не является прямым следствием изменения planner_upper_limit_estimation, но [Вероятно] усилен им.
- Обоснование: Сам по себе параметр планировщика не генерирует запись. Рост этих метрик [Подтверждено] означает увеличение доли INSERT, UPDATE, DELETE в общей нагрузке. Однако [Вероятно] новые планы для этих модифицирующих запросов (или связанных с ними SELECT) стали эффективнее, что позволило системе выполнить их гораздо больше за меньшее время, не создавая узкого места по I/O на чтение.
Влияние на использование временных файлов (Temp and Local blocks)
- Тезис: Снижение чтения временных блоков на 22.34% и незначительное сокращение их записи [Вероятно] говорит об уменьшении числа ресурсоёмких операций сортировки и хеширования на диске.
- Обоснование: planner_upper_limit_estimation может влиять на оценку размера данных, подаваемых на вход операций SORT или HASH JOIN. Более точная или «ограниченная сверху» оценка [Вероятно] позволяет планировщику выбрать другой метод соединения (nested loop с индексом) или выделить более адекватный объём work_mem, из-за чего операция выполняется в памяти, а не сбрасывается на диск во временные файлы.
Влияние на стабильность кэша (Cache resets)
- Тезис: Сокращение числа сбросов разделяемого кэша на 22.55% [Вероятно] является положительным побочным эффектом.
- Обоснование: Поскольку запросы стали затрагивать значительно меньше уникальных блоков (за счёт индексных доступов вместо полных сканирований), снизилась интенсивность вытеснения полезных данных из shared_buffers. Это сделало работу кэша более стабильной и предсказуемой.
Сводная информация о влиянии (список)
Total time (общее время)
- Изменение: -32.3%
- Характер влияния параметра: прямое — выбор более оптимальных планов.
- Степень уверенности: [Вероятно]
Executed count (число выполненных запросов)
- Изменение: +15.8%
- Характер влияния параметра: косвенное — снижение конкуренции за ресурсы позволило обработать больше запросов.
- Степень уверенности: [Вероятно]
I/O time (время ввода-вывода)
- Изменение: -25.2%
- Характер влияния параметра: прямое — сокращение доли полных сканирований.
- Степень уверенности: [Вероятно]
Blocks fetched (всего обращений к блокам)
- Изменение: -49.2%
- Характер влияния параметра: прямое и сильное — замена seq scan на index scan.
- Степень уверенности: [Вероятно]
Shared blocks read (чтений разделяемых блоков)
- Изменение: -24.8%
- Характер влияния параметра: прямое — следствие снижения физических чтений с диска.
- Степень уверенности: [Вероятно]
Temp blocks read (чтений временных блоков)
- Изменение: -22.3%
- Характер влияния параметра: вероятное — оптимизация операций сортировки/хеширования.
- Степень уверенности: [Вероятно]
Cache resets (сбросов кэша)
- Изменение: -22.6%
- Характер влияния параметра: косвенное — меньшее вытеснение блоков из кэша.
- Степень уверенности: [Вероятно]
Shared blocks dirtied («грязных» блоков)
- Изменение: +48.9%
- Характер влияния параметра: не связано напрямую; отражает общий профиль нагрузки с возросшей долей модификаций.
- Степень уверенности: [Предположение]
WAL generated (объём сгенерированного WAL)
- Изменение: +110.6%
- Характер влияния параметра: не связано напрямую; отражает общий профиль нагрузки с возросшей долей модификаций.
- Степень уверенности: [Предположение]
Контрастный анализ и ограничения
Для проверки и опровержения (фальсификации) выдвинутых гипотез [Вероятно] необходимо запросить дополнительные данные о планах запросов.
- ⚠️Что может опровергнуть гипотезу? Если сравнение pg_stat_statements или логов auto_explain за периоды 69-70 и 93-94 не покажет значительного снижения доли Seq Scan в пользу Index Scan при росте общего числа модифицирующих запросов, то основная гипотеза данного отчёта будет опровергнута.
- Альтернативная гипотеза: Профиль нагрузки изменился исключительно из-за смены характера запросов приложением (например, был запущен новый функционал, массово изменяющий данные без активного чтения), а изменение параметра планировщика лишь незначительно модулировало общую картину.
Рекомендация
Несмотря на явно позитивный эффект от корректировки planner_upper_limit_estimation, критически важно верифицировать настройки контрольных точек (checkpoint) и фонового писателя (bgwriter). Резкий рост «грязных» блоков и объёмов WAL [Подтверждено] создаёт риск пиковых нагрузок на дисковую подсистему в моменты сброса данных, что может нивелировать достигнутый прирост производительности в будущем.
3.Формирование гипотезы
Проанализируй описание раздела "Top tables by estimated sequentially scanned volume" из "ТаблицаG.50.txt". Определи и выдай заключение - можно ли использовать сравнительный анализ раздела "Top tables by estimated sequentially scanned volume" в отчетах pgpro_pwr для проверки гипотезы о том, что снижение Total time, I/O time и Blocks fetched вызвано заменой Seq Scan на Index Scan из-за изменения planner_upper_limit_estimation ?
Проанализировав описание раздела «Top tables by estimated sequentially scanned volume» из файла ТаблицаG.50.txt, выношу заключение.
Заключение о пригодности раздела для проверки гипотезы
Использование сравнительного анализа данного раздела в отчётах pgpro_pwr «отчет-69-70» и «отчет-93-94» для проверки гипотезы о замене Seq Scan на Index Scan полностью возможно и обоснованно. [Подтверждено]
Обоснование
Раздел предоставляет все необходимые для прямой верификации данные.
- Наличие прямых счётчиков сканирований: Раздел содержит отдельные столбцы SeqScan (число последовательных сканирований) и IxScan (число индексных сканирований) для каждой таблицы. Это именно те метрики, которые позволяют точно оценить динамику изменения стратегий доступа к данным.
- Детализация по таблицам: Данные агрегированы по каждой таблице (Schema, Table). Это даёт возможность не только увидеть общее изменение доли Index Scan, но и определить, на каких конкретно таблицах произошли наиболее значимые сдвиги.
- Дополнительные подтверждающие метрики: Столбец ~SeqBytes (приблизительный объём данных, прочитанных последовательным сканированием) позволяет оценить утилитарный эффект от изменений. Снижение этого объёма, синхронизированное со снижением SeqScan, напрямую объяснило бы падение метрик Blocks fetched и I/O time, наблюдаемое в общем отчёте о распределении нагрузки.
- Контекст модификаций: Наличие столбцов по вставкам (Ins), обновлениям (Upd) и удалениям (Del) позволяет отдельно проанализировать поведение планировщика для операций чтения и модификации, что было обозначено как важный фактор в предыдущем анализе.
Порядок действий при сравнительном анализе
Для проверки гипотезы с использованием этого раздела необходимо выполнить следующие шаги.
Агрегировать данные по двум периодам: Из отчётов 69-70 и 93-94 просуммировать значения SeqScan и IxScan по всем таблицам, чтобы получить общее количество последовательных и индексных сканирований за каждый период.
Сравнить абсолютные и относительные показатели:
- Сравнить абсолютное суммарное SeqScan. Если оно значимо снизилось на фоне общего роста числа запросов (Executed count +15.77%) — это прямое свидетельство [Подтверждено] снижения использования последовательных сканирований.
Вычислить долю IxScan в общем числе сканирований (Total Scans = SeqScan + IxScan) для каждого периода. Значительный рост этой доли укажет [Вероятно] на изменение предпочтений планировщика в пользу индексов.
Провести потабличный анализ для исключения артефактов: Убедиться, что снижение суммарного SeqScan не вызвано, например, удалением одной большой таблицы или прекращением доступа к ней, а является устойчивым трендом для нескольких объектов с наибольшим вкладом.
Сопоставить с модифицирующей нагрузкой: Проверить, не является ли рост общего числа Index Scan следствием исключительно роста INSERT/UPDATE (которые также используют индексные сканирования для поиска целевых строк). Если соотношение SeqScan/IxScan для операций чтения (SELECT) также изменилось в пользу индексов, гипотеза получит дополнительное подтверждение.
Таким образом, раздел «Top tables by estimated sequentially scanned volume» является идеальным источником данных для прямой фальсификации или подтверждения выдвинутой гипотезы.
4.Проверка гипотезы
Входящие данные
- 69-70.txt - данные раздела "Top tables by estimated sequentially scanned volume" из отчета pgpro_pwr pgpro_pwr.69-70.clear.html
- 93-94.txt - данные раздела "Top tables by estimated sequentially scanned volume" из отчета pgpro_pwr pgpro_pwr.93-94.clear.html
Загрузка инструкции - новый чат
Проверка гипотезы
Входные данные:
69-70.txt - таблица "Top tables by estimated sequentially scanned volume" по отчету pgpro_pwr "отчет-69-70"
93-94.txt - таблица "Top tables by estimated sequentially scanned volume" по отчету pgpro_pwr "отчет-93-94"
ТаблицаG.50.txt - Описание таблицы "Top tables by estimated sequentially scanned volume (Таблицы с наибольшим объёмом последовательно сканированных блоков)"
1.load_distribution-analyze.txt - аналитический отчет по результатам сравнения профиля нагрузки между отчетами pgpro_pwr "отчет-69-70" и "отчет-93-94"
При подготовке ответа с использованием "Philosophical_instruction_BETA_v5.1.md" заменяй цветовые символы на соответствующие им текстовые сокращения:
"Подтверждено"
"Вероятно"
"Предположение"
"Неизвестно"
Задача:
Используя данные из "69-70.txt" и "93-94.txt" , провести проверку гипотезы(подтвердить или опровергнуть) , сформулированной в аналитическом отчете "1.load_distribution-analyze.txt" - "Что может опровергнуть гипотезу? Если сравнение pg_stat_statements или логов auto_explain за периоды 69-70 и 93-94 не покажет значительного снижения доли Seq Scan в пользу Index Scan при росте общего числа модифицирующих запросов, то основная гипотеза данного отчёта будет опровергнута."
Аналитический отчёт: Верификация гипотезы об изменении доли Seq/Index Scan
Исходные данные: Два среза статистики по таблицам с наибольшим предполагаемым объёмом последовательно считанных данных (файлы 69-70.txt и 93-94.txt).
Проверяемая гипотеза (из отчёта 1.load_distribution-analyze.txt): Снижение времени ввода-вывода и общего числа обращений к блокам, [Вероятно], является следствием значительного снижения доли Seq Scan в пользу Index Scan на фоне роста модифицирующей нагрузки.
1. Краткое резюме (основные выводы)
Уровень-1:Подтверждено данными — Доля последовательных сканирований (SeqScan) в общем числе операций доступа к таблицам снизилась с 19.2% до 16.5% (абсолютное количество SeqScan уменьшилось на 17.0%). Доля индексных сканирований (IxScan) зеркально выросла.
Уровень-1:Подтверждено данными — Общее количество индексных сканирований практически не изменилось (рост на 0.1%), то есть абсолютного прироста IxScan не произошло; изменилось соотношение за счёт выпадения SeqScan.
Уровень-1:Подтверждено данными — Количество строк, возвращённых индексными сканированиями (IxFet), сократилось на 43.9% (с ~265.8 млн до ~149.2 млн), несмотря на стабильный IxScan. Это указывает на существенное изменение характера индексных доступов, а не простое «переключение» нагрузки с SeqScan.
Уровень-2:Вероятно, но требует проверки — Снижение доли SeqScan согласуется с гипотезой о влиянии planner_upper_limit_estimation, однако рост модифицирующей нагрузки в данных топ-таблицах не зафиксирован (суммарные Ins+Upd+Del остались на уровне ~1.7 млн), что не соответствует ожидаемому условию гипотезы. Для полной верификации необходим более широкий контекст.
2. Детальный анализ
Периоды наблюдения:
- Период 1: отчёт 69-70
- Период 2: отчёт 93-94
2.1. Сравнение абсолютных показателей SeqScan и IxScan
SeqScan (последовательные сканирования):
- Период 1: 13,488,749
- Период 2: 11,203,054 (снижение на 2,285,695, или -17.0%)
- Уровень-1
IxScan (индексные сканирования):
- Период 1: 56,849,970
- Период 2: 56,903,625 (прирост на 0.1%)
- Уровень-1
IxFet (строк выбрано через индексы):
- Период 1: 265,833,682
- Период 2: 149,177,643 (снижение на 116,656,039, или -43.9%)
- Уровень-1
Интерпретация:
Количество индексных сканирований сохранилось, но их результативность (число возвращаемых строк на одно сканирование) резко упала — с 4.68 до 2.62 строк в среднем. Это не может быть объяснено простым перенаправлением запросов с SeqScan на IndexScan: если бы те же запросы просто стали использовать индексы, объём возвращаемых строк остался бы сопоставимым. Следовательно, либо изменился набор выполняемых запросов (стали преобладать более селективные), либо изменилась сама логика доступа (например, чаще используются сканирования только индекса, index-only scans, которые не увеличивают IxFet, но это не отражено в имеющихся метриках).
2.2. Модифицирующая нагрузка в представленных таблицах
Суммарные модификации (Ins + Upd + Del):
- Период 1: 1,714,568
- Период 2: 1,671,974 (снижение на 2.5%)
- Уровень-1
Интерпретация:
В топ-таблицах, ранжированных по ~SeqBytes, модификационная активность практически не изменилась. Это противоречит тезису из отчёта 1.load_distribution-analyze.txt о взрывном росте модификаций (Shared Blocks Dirtied +48.9%, WAL +110.6%). Возможные объяснения: модификации сконцентрированы в таблицах, не попавших в данный топ (их ~SeqBytes невелик, так как они редко читаются последовательно), либо рост WAL и грязных блоков связан не с числом строк, а с объёмом изменяемых данных (более «широкие» строки, массовые update). Уровень-2.
2.3. Структура изменений по ключевым таблицам
- _reference109: Значительный рост IxFet (с 58M до 65M) и умеренный рост Upd. SeqScan основного сегмента остался стабильным (267→265), но TOAST-сегмент показал падение SeqScan (с 7.26M до 4.73M) при пропорциональном снижении IxScan. Уровень-1.
- _reference92: TOAST-сегмент демонстрирует стабильно огромное количество IxScan (11.8M и 12.2M) при нулевых IxFet — вероятно, это технические индексные сканирования, не возвращающие строки (например, проверки уникальности или обслуживание индексов). Уровень-2.
- _inforg12488: IxFet упал с 48.9M до 47.4M (–3.1%), количество модификаций выросло незначительно. Уровень-1.
- _inforg6147: IxScan снизился на 15% (9.37M → 7.98M), IxFet — на 14%. Уровень-1.
- pg_class, pg_attribute: Объём модификаций высок, но заметного роста во втором периоде нет. Уровень-1.
Примечание: Аномально высокие SeqScan TOAST-таблиц _reference109 и _reference92 (миллионы) могут быть следствием особенностей работы планировщика с длинными строками. Их снижение внесло основной вклад в сокращение общего SeqScan. Уровень-2.
3. Проверка внутренней согласованности и противоречий
Противоречие 1: Падение IxFet при стабильном IxScan.
- Фиксация: Уровень-1.
- Гипотеза: Изменился состав запросов — чаще выполняются короткие индексные доступы (малое количество возвращаемых строк). Это может быть следствием как настройки планировщика (ограничение оценки кардинальности ведёт к выбору nested loop с индексным доступом для меньших объёмов), так и изменения бизнес-логики. Уровень-2.
- Для разрешения: Необходимы планы запросов или статистика pg_stat_statements за оба периода. Уровень-3.
Противоречие 2: Отсутствие роста модификаций в топ-таблицах при значительном росте WAL и грязных блоков в системном масштабе.
- Фиксация: Уровень-1.
- Гипотеза: Модификации происходили в таблицах, не попавших в предоставленный топ (так как топ отбирался по SeqBytes, а не по модификациям). Уровень-2.
- Для разрешения: Нужен топ таблиц по числу модификаций или аналогичный отчёт из pgpro_pwr за те же периоды. Уровень-3.
4. Проверка на типовые инженерные ошибки (согласно разделу 7 инструкции pg_expecto)
Шаг 1. Silent error swallowing
- Уровень-4: Логи PostgreSQL не предоставлены. Проверка невозможна.
Шаг 2. Resource leaks (утечки ресурсов)
- Уровень-4: Данные о трендах соединений, временных файлов и памяти процесса отсутствуют. Проверка невозможна.
Шаг 3. Copy-paste without understanding (неадекватные параметры конфигурации)
- Уровень-4: Значения параметров (random_page_cost, effective_cache_size, work_mem и т.д.) не предоставлены. Проверка невозможна.
Шаг 4. Race conditions в приложении (по косвенным признакам)
- Уровень-4: Метрики vmstat (cs, sy, us) или аналогичные отсутствуют. Проверка невозможна.
Итог: Без дополнительных данных оценка инженерных рисков невозможна.
5. Контрастный анализ (фальсификация гипотезы)
Что могло бы опровергнуть гипотезу о влиянии параметра планировщика:
Если бы в данных отсутствовало снижение доли SeqScan или рост IxScan, гипотеза была бы опровергнута. Частично гипотеза устояла — снижение доли SeqScan присутствует (Уровень-1). Однако отсутствие роста модификаций в предоставленных таблицах и резкое падение IxFet не позволяют безоговорочно принять тезис о простом «переключении» SeqScan в IndexScan. Уровень-2.
Альтернативная гипотеза 1: Снижение SeqScan вызвано изменением состава запросов приложения (например, переписаны проблемные запросы, добавлены лимиты, изменилась бизнес-логика), а не изменением параметра planner_upper_limit_estimation. Уровень-2.
Альтернативная гипотеза 2: Параметр планировщика повлиял, но основным драйвером снижения I/O стало именно падение IxFet (запросы стали возвращать меньше строк), а не рост числа IxScan. Косвенно на это указывает тот факт, что IxScan практически не изменился, а IxFet упал почти вдвое. Уровень-2.
6. Ограничения и необходимые дополнительные данные
Предоставленный срез включает только таблицы с наибольшим ~SeqBytes. Выборка смещена в сторону объектов с высоким объёмом последовательного чтения. Модификации и малочитаемые таблицы не охвачены. Уровень-2.
Для окончательного вывода требуется:
- Сравнение планов запросов из pg_stat_statements или auto_explain за оба периода (количество запросов с преобладанием SeqScan vs IndexScan, общее число строк). Уровень-3.
- Топ таблиц по числу модификаций для сопоставления с утверждением о росте WAL. Уровень-3.
- Общесистемные метрики Buffer Hit Ratio для оценки эффективности кэша до и после изменений. Уровень-3.
7. Заключение
Гипотеза частично подтверждается предоставленными данными в части снижения доли SeqScan.
Однако полная формулировка гипотезы (снижение доли SeqScan при росте модифицирующих запросов) не находит подтверждения в представленном срезе топ-таблиц.
Резкое снижение IxFet указывает на более сложную трансформацию профиля нагрузки, чем простое замещение одного типа сканирования другим.
Для ответа о вкладе planner_upper_limit_estimation в общее улучшение метрик необходима информация о планах запросов.
Общий технический итог
При изменении planner_upper_limit_estimation с «on» (отчёт 69‑70) на «off» (отчёт 93‑94) общее время выполнения запросов сократилось на 32,34 % при росте числа выполненных запросов на 15,77 %; физическое чтение с диска (shared blocks read) уменьшилось на 24,84 %, а общее число обращений к разделяемым блокам (blocks fetched) — на 49,22 %. Доля последовательных сканирований в общем числе операций доступа к таблицам снизилась с 19,2 % до 16,5 % при абсолютном сокращении SeqScan на 17,0 %, тогда как количество индексных сканирований (IxScan) осталось практически неизменным (прирост +0,1 %). Однако количество строк, возвращённых индексными сканированиями (IxFet), сократилось на 43,9 % (с ~265,8 млн до ~149,2 млн), что указывает на качественное изменение характера доступа в сторону более селективных запросов. Объём сгенерированного WAL вырос на 110,57 %, а число «грязных» разделяемых блоков (shared blocks dirtied) — на 48,98 %, что свидетельствует о значительном увеличении модифицирующей нагрузки, хотя в предоставленном срезе топ-таблиц по последовательному сканированию суммарные вставки, обновления и удаления не выросли, а снизились на 2,5 %.
Таким образом, гипотеза о замещении Seq Scan на Index Scan вследствие изменения planner_upper_limit_estimation частично подтверждается по показателям доли сканирований, но полное объяснение эффектов требует учёта запросов, не попавших в топ по последовательному чтению, и анализа планов выполнения через pg_stat_statements или auto_explain.
Послесловие
Полученные результаты демонстрируют, что настройка planner_upper_limit_estimation способна существенно снизить затраты на ввод-вывод и увеличить пропускную способность системы, однако сопряжённый с этим резкий рост WAL и грязных блоков при отсутствии явного увеличения числа модификаций в анализируемом срезе таблиц требует осторожной интерпретации.
Возможно, наблюдаемое повышение модифицирующей нагрузки концентрируется на таблицах, не входящих в топ по объёму последовательного сканирования, либо связано с увеличением объёма изменяемых данных в расчёте на одну операцию (широкие строки, массовые обновления).
Для окончательной верификации причинно-следственных связей необходимо дополнительно исследовать планы запросов до и после изменения параметра, а также проверить конфигурацию контрольных точек и фонового писателя, поскольку накопление «грязных» блоков при снижении их физической записи может создавать риски пиковых нагрузок на дисковую подсистему. Настоящее исследование рассматривается как предварительный этап, и его выводы подлежат уточнению на расширенной выборке статистических данных.