📌Perplexity опубликовала рецепт посттрейна поискового агента на Qwen3.5
Исследовательская команда ИИ-поисковика опубликовала техотчёт о деталях создания своего веб-поискового агента на открытых моделях Qwen3.5-122B-A10B и Qwen3.5-397B-A17B.
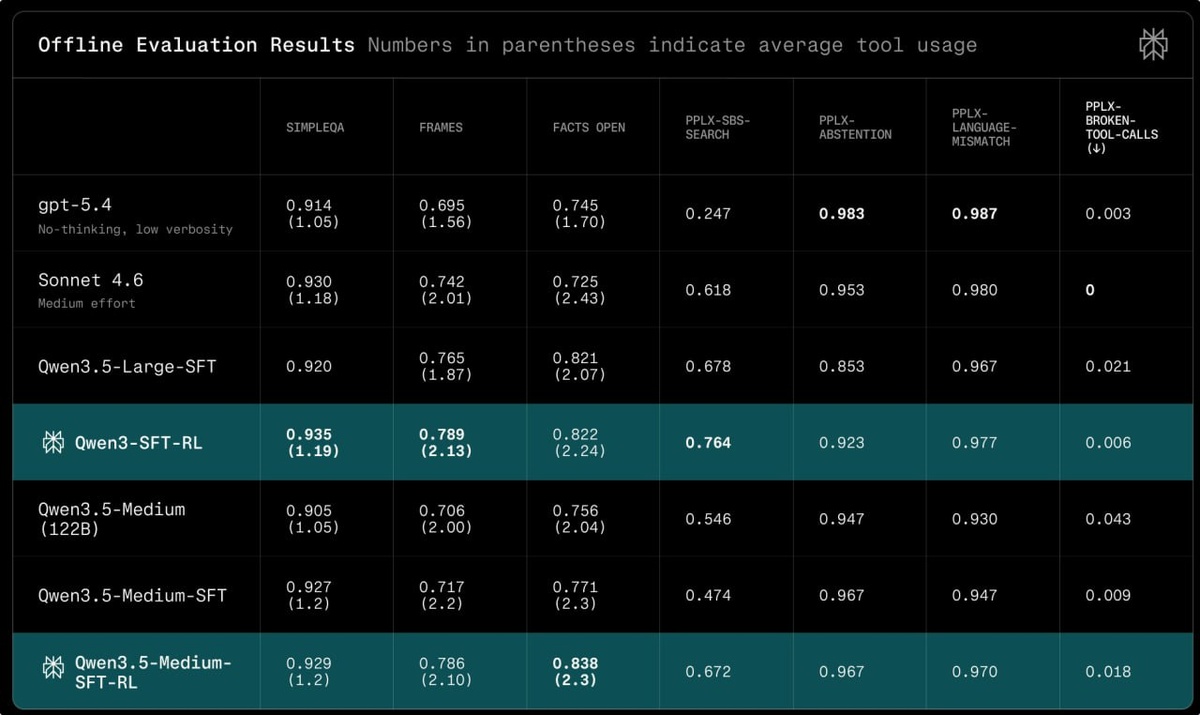
При бюджете в 4 вызова инструмента итоговая Qwen3.5-397B-SFT-RL показывает 73,9% точности на FRAMES и стоит 2 цента за запрос против 67,8% за 8,5 цента у GPT-5.4 и 62,4% за 15,3 цента у Sonnet 4.6.
🟡Пайплайн
Сначала SFT закрепляет целевое поведение: следование инструкциям, формат ответа, языковую согласованность, корректные отказы.
Затем RL с GRPO оттачивает точность поиска и эффективность вызовов инструментов, не трогая поведение, заданное на первой стадии.
Попытка оптимизировать эти цели совместно в один этап обычно ломает либо качество поиска, либо продакшен-требования.
🟡Данные для RL собраны из двух источников.
Первый - синтетические многошаговые вопросы с проверяемым ответом: из затравочного запроса выстраивают цепочку связанных сущностей, формулируют вопрос, а единственность ответа подтверждают несколько независимых решателей.
Второй - диалоги общего назначения, где требования к формату и инструкциям превращают в набор атомарных рубрик, проверяемых без субъективной оценки.
Итоговая смесь берётся в пропорции 90/10 в пользу верифицируемых QA, чтобы более лёгкий сигнал рубрик не перетягивал градиент на себя.
В основе системы вознаграждений - агрегирование со шлюзом по корректности: скор Bradley-Terry-модели учитывается только при условии, что базовый бинарный сигнал равен 1 (то есть ответ корректен или все рубрики выполнены).
Это блокирует взлом награды, когда стилистически удачная реплика компенсирует фактическую ошибку.
Штраф за эффективность привязан к GRPO: число вызовов инструмента и длина генерации сравниваются с победителями внутри группы, а не с фиксированной нормой.
На FRAMES при 1 вызове инструмента старшая Qwen3.5 показывает 57,3% (это +5,7 пункта к GPT-5.4 и +4,7 к Sonnet 4.6). Разрыв увеличивается в диапазоне 2–7 вызовов, а это и есть рабочий режим продакшена.
Расчёт использует публичные цены API без учёта кэширования. Perplexity отдельно оговаривает, что внутренние оптимизации инференса (повторное использование KV-кэша, префиксное кэширование, квантование MoE) снижают реальную стоимость ещё сильнее.
🔜 Полный рисерч можно почитать тут
#AI #ML #LLM #Train #Research #Perplexity