Если вы делали расшифровки в Premiere или Resolve, то можете себе представить их качество. Часто слова не расслышанные превращаются в набор букв, а если вы используете англоязычные термины, то в лучшем случае будет транскрипция на русском, в худшем набор букв или похожее слово.
И в принципе для монтажа по тексту этого достаточно, но для работы с текстом, например для написания сценария или для подготовки описания этого может быть недостаточно.
Лучший результат на мой взгляд выдает elevenlabs, там и разные языки корректно определяются и спикеров можно разделить, и потом конвертнуть в субтитры нормальные. НО за это надо платить кредитами, а стоят расшифровки там почти как генерации речи.
Вопрос, что делать если нужны просто расшифровки?
Я выход себе нашел, я с ChatGPT смастерил себе скрипт, который используя модель WHISPER LARGE 3 делает расшифровки локально на своей машине. При этом ей даже не нужно GPU, так как она работает и на CPU просто в несколько раз дольше. На вход принимает видео файл на выходе TXT с расшифровками и Таймкодами по 3 минуты.
Что с ними дальше можно делать? Мне допустим они нужны для подготовки описания к видео и урокам. Я закидываю расшифровки в любую GPT систему и на выходе получаю описание к видео и таймкоды по темам.
Рецептом как это сделать я и делюсь. Попробую сделать это максимально подробно, чтобы каждый мог повторить. если вылетают какие то ошибки закидывайте их скринами или текстом в любой GPT там подскажут ответ. Я опишу в целом алгоритм.
ШАГ 1. Установить Python
Если ещё нет, скачиваем Python 3.10 или 3.11 с
https://www.python.org
Во время установки обязательно поставить галочку: Add Python to PATH
Для чего это нужно? Все приложения добавленные в PATH потом запускаются по командной строке. В данном случае по команде python будут обращения к питону
Возможно вы спросите: Как запускать командную?
Переходим в папку где хотите запустить и прямо в адресной строке пишите CMD либо powershell. Я предпочитаю powershell, потому что там больше возможностей и в целом круче звучит.
После установке в терминале можно запустить "python --version" без кавычек и если питон установлен и прописан в PATH то команда пройдёт и будет написана версия питона
ШАГ 2. Установить FFmpeg
FFmpeg будет преобразовывать входной файл в wav 16 kHz, ну и в принципе нужен для чтения всего видеозвукообразного.
Можно с сайта просто папку с архивом, тогда её надо будет прописать в PATH https://ffmpeg.org/download.html
Либо через командную строку "winget install ffmpeg"
Проверка "ffmpeg -version"
Если проверка не проходит скорее всего он не прописался в PATH, тогда надо прописать его там вручную.
Можно через командную строку, команда выглядит так "setx PATH "%PATH%;C:\путь\к\программе""
Одни из кавычек убрать и нужно дать права администратора.
ШАГ 3. Установить PyTorch c CUDA(если делать на CPU, то можно пропустить).
В powershell запускаем "pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121"
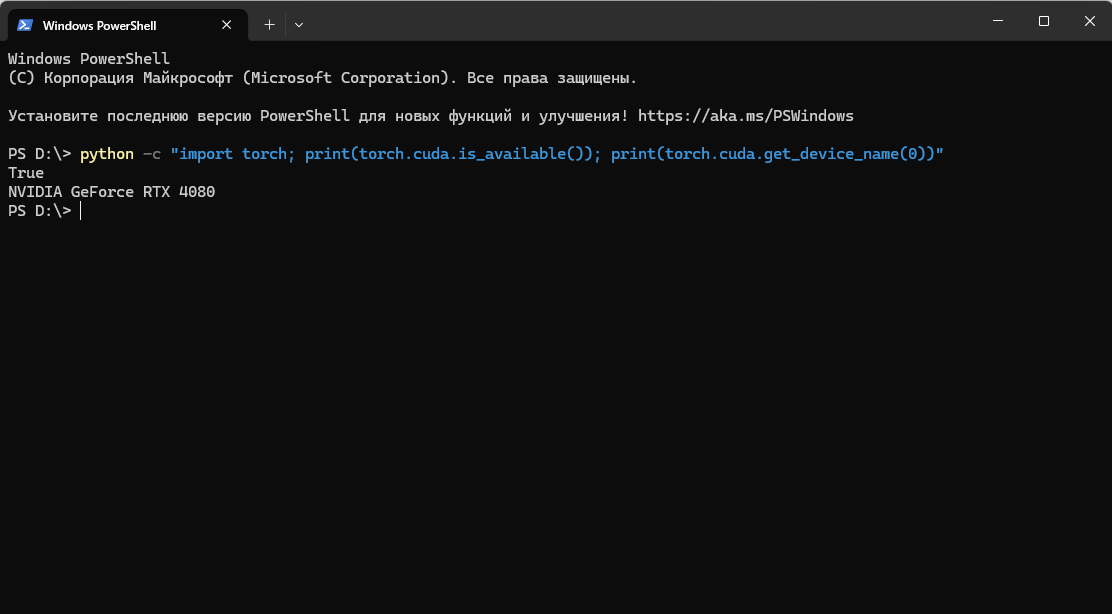
Проверка - python -c "import torch; print(torch.cuda.is_available()); print(torch.cuda.get_device_name(0))"
На выходе должно быть название видеокарты
ШАГ 4. Устанавливаем whisper
pip install openai-whisper
ШАГ 5. Запуск скрипта
Мы в папку где запускаем кладём файл скрипта, файл для анализа без русских букв и без пробелов в названии.
Сама команда запуска состоит из трёх частей -- "python (команда обращение к python) ПРОБЕЛ названиескрипта.py ПРОБЕЛ названиефайла.mp4"
Всё это делаете в командной строке изнутри папки.
Дальше будет два варианта скрипта для CUDA и для CPU. Этот текст засовываете в блокнот. Сохраняете с расширением .py и кладёте в папку, где всё будете расшифровывать. После чего запускаете скрипт и ждёте.
Наслаждайтесь!
СКРИПТ ДЛЯ CUDA
import sys
import os
import whisper
import torch
import subprocess
BLOCK_SECONDS = 120
def format_time(seconds):
seconds = int(seconds)
h = seconds // 3600
m = (seconds % 3600) // 60
s = seconds % 60
return f"{h:02}:{m:02}:{s:02}"
def convert_to_wav(input_file):
output_file = os.path.splitext(input_file)[0] + "_16k.wav"
if not os.path.exists(output_file):
print("Конвертация в WAV 16kHz mono...")
subprocess.run([
"ffmpeg",
"-y",
"-i", input_file,
"-ar", "16000",
"-ac", "1",
output_file
], check=True)
return output_file
def main(audio_path):
if not os.path.isfile(audio_path):
print("Файл не найден")
return
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Используем устройство:", device)
wav_path = convert_to_wav(audio_path)
print("Загрузка модели large-v3...")
model = whisper.load_model("large-v3", device=device)
print("Распознавание...")
result = model.transcribe(
wav_path,
language="ru",
task="transcribe",
temperature=0.0,
beam_size=5,
best_of=5,
condition_on_previous_text=False,
compression_ratio_threshold=2.4,
logprob_threshold=-1.0,
no_speech_threshold=0.6,
fp16=(device == "cuda")
)
segments = result["segments"]
output_path = os.path.splitext(audio_path)[0] + "_blocks_cuda.txt"
current_block = []
block_start = None
with open(output_path, "w", encoding="utf-8") as f:
for segment in segments:
if block_start is None:
block_start = segment["start"]
current_block.append(segment)
if segment["end"] - block_start >= BLOCK_SECONDS:
text = " ".join(s["text"].strip() for s in current_block)
f.write(f"[{format_time(block_start)}] {text}\n\n")
current_block = []
block_start = None
if current_block:
text = " ".join(s["text"].strip() for s in current_block)
f.write(f"[{format_time(block_start)}] {text}\n\n")
print("Готово.")
print("Файл сохранён:", output_path)
if name == "main":
main(sys.argv[1])
КОНЕЦ СКРИПТА
СКРИПТ ДЛЯ CPU
import sys
import os
import whisper
import torch
BLOCK_SECONDS = 120
def format_time(seconds):
seconds = int(seconds)
h = seconds // 3600
m = (seconds % 3600) // 60
s = seconds % 60
return f"{h:02}:{m:02}:{s:02}"
def main(audio_path):
if not os.path.isfile(audio_path):
print("Файл не найден")
return
device = "cpu"
print("Используем CPU")
print("Загрузка модели...")
model = whisper.load_model("large-v3", device=device)
print("Распознавание...")
result = model.transcribe(
audio_path,
language="ru",
task="transcribe",
temperature=0.0,
beam_size=5,
best_of=5,
condition_on_previous_text=False,
compression_ratio_threshold=2.4,
logprob_threshold=-1.0,
no_speech_threshold=0.6,
fp16=False
)
segments = result["segments"]
output_path = os.path.splitext(audio_path)[0] + "_blocks.txt"
current_block = []
block_start = None
with open(output_path, "w", encoding="utf-8") as f:
for segment in segments:
if block_start is None:
block_start = segment["start"]
current_block.append(segment)
if segment["end"] - block_start >= BLOCK_SECONDS:
text = " ".join(s["text"].strip() for s in current_block)
f.write(f"[{format_time(block_start)}] {text}\n\n")
current_block = []
block_start = None
if current_block:
text = " ".join(s["text"].strip() for s in current_block)
f.write(f"[{format_time(block_start)}] {text}\n\n")
print("Готово.")
print("Файл сохранён:", output_path)
if name == "main":
main(sys.argv[1])
КОНЕЦ СКРИПТА
Если дошли досюда, то напоминаю, лучшие курсы по монтажу видео на Zernovlab.academy